收藏!盘点很实用的数据科学Python库
2021-03-02 分类: 网站建设
数据科学是一门研究数据并从中挖掘信息的学科。它不要求自创或学习新的算法,只需要知道怎么样研究数据并解决问题。这一过程的关键点之一就在于使用合适的库。本文概述了数据科学中常用的、并且有一定重要性的库。在进入正题之前,本文先介绍了解决数据科学问题的5个基本步骤。这些步骤是笔者自己总结撰写的,并无对错之分。步骤的正确与否取决于数据的研究方法。

数据科学的五个重要步骤包括:
1.获取数据
2.清理数据
3.探索数据
4.构建数据
5.呈现数据
这五个步骤只是经验之谈,并不是什么标准答案。但是如果仔细思考,就会发现这五个步骤是非常合理的。
1. 获取数据
获取数据是解决数据科学问题的关键一步。你需要提出一个问题并最终解决它。这取决于你是如何以及从何处获取数据的。获取数据较好的方法就是从Kaggle上下载或从网络上抓取。
当然,你也可以采用适当的方法和工具从网络上抓取数据。
网络数据抓取最重要、最常用的库包括:
1.Beautiful Soup
2.Requests
3.Pandas
Beautiful Soup是一个可从HTML和XML文件中提取数据的Python库。推荐读者阅读Beautiful Soup库官方文档。
如果已经安装Python,只需输入以下命令,即可安装Beautiful Soup。文中所涉及的库全部给出了安装方法。但是我更推荐读者使用Google Colab,便于练习代码。在Google Colab中,无需手动安装,只需要输入“importlibrary_name”,Colab就会自动安装。
pip install beautifulsoup4
导入Beautiful Soup库:
from bs4 import BeautifulSoupSoup = BeautifulSoup(page_name.text, ‘html.parser’)
Python的Requests库采用更加简单易用的方式发送HTTP请求。Requests库中有很多种方法,其中最常用的是request.get()。在URL转发成功或失败的情况下,request.get()都能够返回URL转发状态。推荐读者阅读Requests库官方文档了解更多信息(https://realpython.com/python-requests/?source=post_page-----a58e90f1b4ba----------------------)。
安装Requets:
pip install requests
导入Requests库:
import requestspaga_name = requests.get('url_name')
Pandas是一种方便易用的高性能数据结构,同时也是Python编程语言分析工具。Pandas提供了一种能够清晰、简洁地存储数据的数据框架。Pandas库官方文档如下:https://pandas.pydata.org/pandas-docs/stable/?source=post_page-----a58e90f1b4ba----------------------
安装Pandas:
pip install pandas
导入Pandas库:
import pandas as pd
2. 清理数据
清理数据有许多重要的步骤,往往包括清除重复行、清除异常值、查找缺失值和空值,以及将对象值转换成空值并绘制成图表等。
数据清理常用的库包括:
1.Pandas
2.NumPy
Pandas可以说是数据科学中的“万金油”——到处都可用。关于Pandas的介绍详见上文,此处不再赘述。
NumPy即Numeric Python,是一个支持科学计算的Python库。众所周知,Python本身并不支持矩阵数据结构,而Python中的NumPy库则支持创建和运行矩阵计算。NumPy库官方文档如下:https://numpy.org/devdocs/?source=post_page-----a58e90f1b4ba----------------------
运行以下命令下载NumPy(确保已经安装了Python):
python -m pip install --user numpy scipy matplotlib ipython jupyter pandas sympy nose
导入NumPy库:
import numpy as np
3. 探索数据
探索性数据分析(Exploratory Data Analysis, EDA)是用于增强信息索引理解的工具,通过有规律地删减和用图表绘制索引基本特征实现。使用EDA能够帮助用户更加深入、清晰地探索数据,展现重要信息采集的发布或情况。
运行EDA常用的库包括:
1.Pandas
2.Seaborn
3.Matplotlib.pyplot
Pandas:详见上文。
Seaborn是一个Python数据可视化库,为绘制数据图表提供了一个高级接口。安装新版本的Seaborn:
pip install seaborn
使用Seaborn,可以轻松绘制条形图、散点图、热力图等图表。导入Seaborn:
import seaborn as sns
Matplotlib是一个Python 2D图形绘图库,能够在多种环境中绘制图表,可替代Seaborn。事实上,Seaborn是基于Matplotlib开发的。
安装Matplotlib:
python -m pip install -U matplotlib
推荐阅读Matplotlib官方文档:https://matplotlib.org/users/index.html?source=post_page-----a58e90f1b4ba----------------------
导入Matplotlib.pyplot库:
import matplotlib.pyplot as plt
4. 构建模型
构建模型是数据科学中的关键一步。由于这一步要求根据要解决的问题和所获取的数据来构建机器学习模型,所以和其他步骤相比难度更大。在这一步中,问题陈述是至关重要的一点,因为它会影响对问题的定义和提出的解决方法。网络上大部分公开的数据集都是基于某一个问题收集的,因此解决问题的能力就尤为重要。而且,由于没有某个特定的算法最适合自己,你需要在多种算法中进行选择,考虑数据适合用回归、分类、聚类还是降维算法。
选择算法经常是一件让人头疼的事。读者可以使用SciKit learn算法选择路径图来记录追踪哪个算法的性能最优。下图展示了一张SciKit learn的路径图:
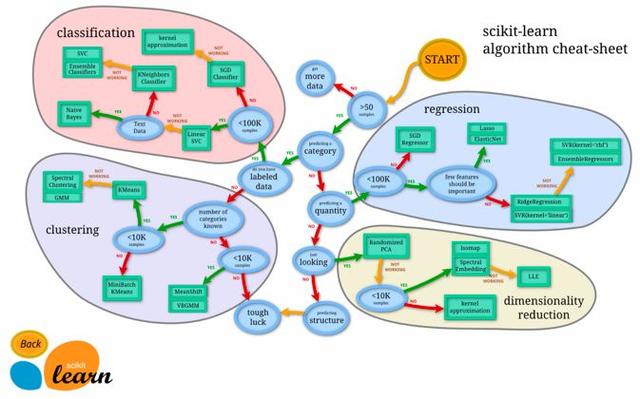
不难猜出,建模时最常用的库是:
1.SciKit learn
SciKit learn是Python中一个便于使用的构建机器学习模型的库。它是基于NumPy、SciPy和Matplotlib开发的。SciKit learn库官方文档如下:https://scikit-learn.org/stable/?source=post_page-----a58e90f1b4ba----------------------
导入scikit learn:
import sklearn
安装scikit learn:
pip install -U scikit-learn
5. 呈现数据
这是数据科学的最后一步,也是很多人不想做的一步——毕竟没有人想要公开发表他们的数据发现。呈现数据也是有法可循的,并且这个方法极为重要,因为无论如何,成果最终还是要向人们展示的。而且由于人们并不关心所使用的的算法,他们只关心结果,所以展示还要做到简洁明了。为了展现数据成果,推荐读者安装Jupyter notebook:https://jupyter.org/install.html?source=post_page-----a58e90f1b4ba----------------------
同时,安装如下指令给notebook配备展示选项:
pip install RISE
阅读文章:http://www.blog.pythonlibrary.org/2018/09/25/creating-presentations-with-jupyter-notebook/,了解更多如何使用notebook做出精彩展示的教程。务必遵循教程的步骤。读者还可以观看Youtube的视频进行学习:
以上就是本文全部内容。本文从最基础的内容开始介绍,读完全文,读者已经知道了在数据科学中如何、在何时、以及在哪一步使用Python库。
网站名称:收藏!盘点很实用的数据科学Python库
网站链接:https://www.cdcxhl.com/news/103728.html
成都网站建设公司_创新互联,为您提供微信公众号、搜索引擎优化、域名注册、网站建设、软件开发、外贸网站建设
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
猜你还喜欢下面的内容
- 企业官网建设要多少钱?步骤有哪些? 2021-03-02
- 电商如何利用好小程序做引流推广和营销 2021-03-02
- 跨境电商网站部署SSL证书迫在眉睫 2021-03-02
- 企业想做大,重产品还是重营销? 2021-03-02
- 外贸网站怎么做优化?这些技巧能让你事半功倍 2021-03-02
- 写ios和安卓系统的人到底有多牛? 2021-03-02
- 为什么进入测试行业要趁早? 2021-03-02

- 电脑cpu和手机cpu有什么区别,差距有多大? 2021-03-02
- 直销公司选择什么服务器,需要考虑什么 2021-03-02
- 5G消息服务入口在哪,你可能想不到 2021-03-02
- 快时尚的时代,过去了? 2021-03-02
- 域名投资掌握什么技巧?行业大佬都是怎么投资域名? 2021-03-02
- 新基建:之云计算,风起“云”涌,驱动未来,关注产业链投资机会 2021-03-02
- 做电商为什么一定要申请商标 2021-03-02
- 解决百度算法更新的折磨 2021-03-02
- 域名国家工程研究中心主任毛伟解读.net”断网”事件 2021-03-02
- 企业该不该选择SAAS服务? 2021-03-02
- 百度SEO,长期真的有效果吗? 2021-03-02
- 云计算对社会的改变,企业如何发展云计算 2021-03-02