数据中心如何向400G/800G迁移?
2022-10-11 分类: 网站建设
跨数据中心的情况再次发生变化。
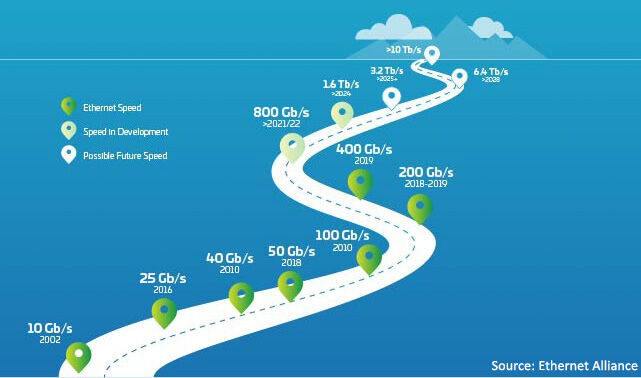
图 1:以太网路线图
加速采用云基础设施和服务正在推动对更多带宽、更快速度和更低延迟性能的需求。 先进的交换机和服务器技术正在迫使布线和架构发生变化。 无论您的设施的市场或重点如何,您都需要考虑企业或云架构的变化,这些变化可能是支持新要求所必需的。 这意味着了解推动采用云基础架构和服务的趋势,以及使您的组织能够满足新要求的新兴基础架构技术。
在规划未来时,需要考虑以下几点。
一、数据中心格局正在演变
1、全球数据使用
当然,这些变化的核心是正在重塑消费者期望和对更多更快通信的需求的全球趋势,例如:
社交媒体流量爆炸式增长 5G 服务的推出,通过大规模的小型蜂窝密集化实现 加速物联网和 IIoT(工业物联网)的部署 从传统的办公室工作转向远程选项2、超大规模供应商的增长
在全球范围内,真正的超大规模数据中心可能不到十几个左右,但它们对整体数据中心景观的影响是巨大的。 根据最近的研究,仅在 2020 年,全世界的在线时间就达到了 12.5 亿年。大约 53% 的流量通过超大规模设施。
3、与多租户数据中心 (MTDC / co-Location) 设施建立超大规模合作
随着对更低延迟性能的需求增加,超大规模和云规模供应商努力将他们的存在扩展到更靠近最终用户/终端设备的地方。 许多人正在与 MTDC 或托管数据中心合作,将他们的服务定位在所谓的网络“边缘”。 当边缘物理上靠近时,较低的延迟和网络成本会扩大新的低延迟服务的价值。
在超大规模领域,MTDC 和主机代管设施正在调整其基础设施和架构,以支持更典型的超大规模数据中心日益增长的规模和流量需求。 同时,这些大的数据中心必须继续灵活地满足客户对与云提供商入口交叉连接的请求。
4、Spine-Leaf 和 Fabric Mesh 网络
支持低延迟、高可用性、超高带宽应用的需求几乎不仅限于超大规模和托管数据中心。 所有数据中心设施现在都必须重新考虑其处理最终用户和利益相关者不断增长的需求的能力。 作为回应,数据中心管理人员正在迅速转向光纤更密集的网状结构网络。 任意对任意连接、更高光纤数的主干电缆和新的连接选项使网络运营商能够支持更高的通道速度,因为他们准备过渡到每秒 400 G。
5、启用人工智能 (AI) 和机器学习 (ML)
此外,部分受物联网和智慧城市应用驱动的大型数据中心提供商正在转向人工智能和机器学习,以帮助创建和完善数据模型,以支持近乎实时的边缘计算能力。除了有可能实现新的应用世界(想想商业上可行的自动驾驶汽车)之外,这些技术还需要海量数据集(通常称为数据湖)、数据中心内的海量计算能力和足够大的管道来推动在需要时将模型细化到边缘。
6、向 400G/800G 迁移的时机
不要仅仅因为你今天以 40G 甚至 100G 的速度运行,就不要陷入虚假的安全感。 如果数据中心发展的历史教会了我们什么,那就是变化的速度——无论是带宽、光纤密度还是通道速度——都呈指数级加速。 向 400G 的过渡比您想象的要近。 不确定? 将您当前支持的 10G(或更快)端口的数量加起来,想象它们发展到 100G,您会意识到对 400G(及更高)的需求并不遥远。
二、对数据中心意味着什么?
随着数据中心经理展望未来,基于云的演进迹象无处不在。
在云本身内部,硬件正在发生变化。 传统数据中心中典型的多个不同网络已经发展为使用池化硬件资源和软件驱动管理的更加虚拟化的环境。 这种虚拟化推动了以尽可能快的方式路由应用访问和活动的需求,迫使许多网络管理员问:“我如何设计我的基础架构来支持这些云优先的应用?”
答案从启用更高的信道速度开始。 从 25 到 50 到 100G 及以上的演进是达到 400G 及以上的关键,它已开始取代传统的 1/10G 迁移路径。 但它不仅仅是提高信道速度,还有更多。 我们必须更深入地挖掘。
三、什么正在推动向更高速度的转变?
数据中心行业正处于拐点。 400G 的采用速度非常快,但很快 800G 预计将开始比 400G 更快。 正如人们所预料的那样,对于“什么推动了向 400G 的过渡?”没有简单的答案。 有多种因素在起作用,其中许多是相互交织的。 当通道速率增加时,新技术可以降低每比特成本。
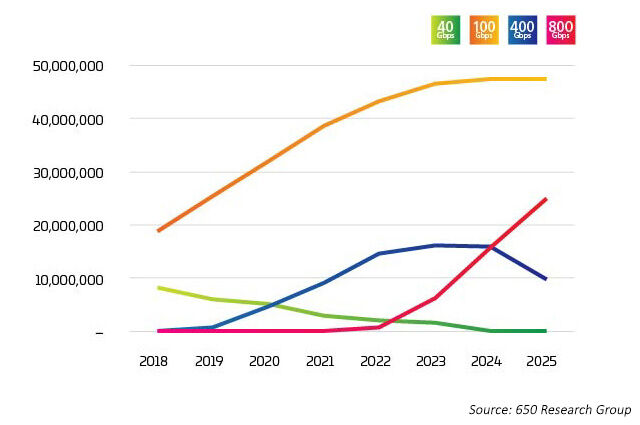
最新数据显示,100G 通道速率将与八进制交换机端口相结合,从 2022 年开始将 800G 选项推向市场。然而,这些端口正以多种方式被利用,如 Light Counting 数据所示,正如在光计数数据6中所示,其中400G和800G主要被分解为4X或8X 100G。正是这种突破性的应用,成为了这些新型光学应用的早期驱动因素。
四、向 400G 的过渡是一项集体努力
400G/800G 迁移的四大支柱
当您开始考虑支持迁移到 400G 的“具体细节”时,很容易被所涉及的所有移动部件所淹没。 为了帮助您更好地了解需要考虑的关键变量,我们将它们分为四个主要领域:
增加交换机端口密度 光收发器技术 连接器选项 布线进展
这四个领域共同代表了迁移工具箱的重要组成部分。 使用它们来微调您的迁移策略,以满足您当前和未来的需求。
更高的交换机端口密度(radix)——ToR 的终结?
随着序列化/反序列化器(SERDES)为交换专用芯片从10G、25G、50G移动提供电气I/O,交换速度正在提高。一旦IEEE802.3ck成为被批准的标准,SERDES预计将达到100G。开关专用集成电路(asic)也在增加I/O端口密度(又名基数)。更高的基数asic支持更多的网络设备连接,提供了消除层顶机架(ToR)交换机的潜力。这反过来又减少了云网络所需的交换机总数。(一个拥有100,000台服务器的数据中心可以支持两级交换,基数为512。)更高的基数asic意味着更低的资本支出(更少的交换机),更低的运营支出(更少的交换机供电和冷却所需的能源),并通过更低的延迟改善网络性能。
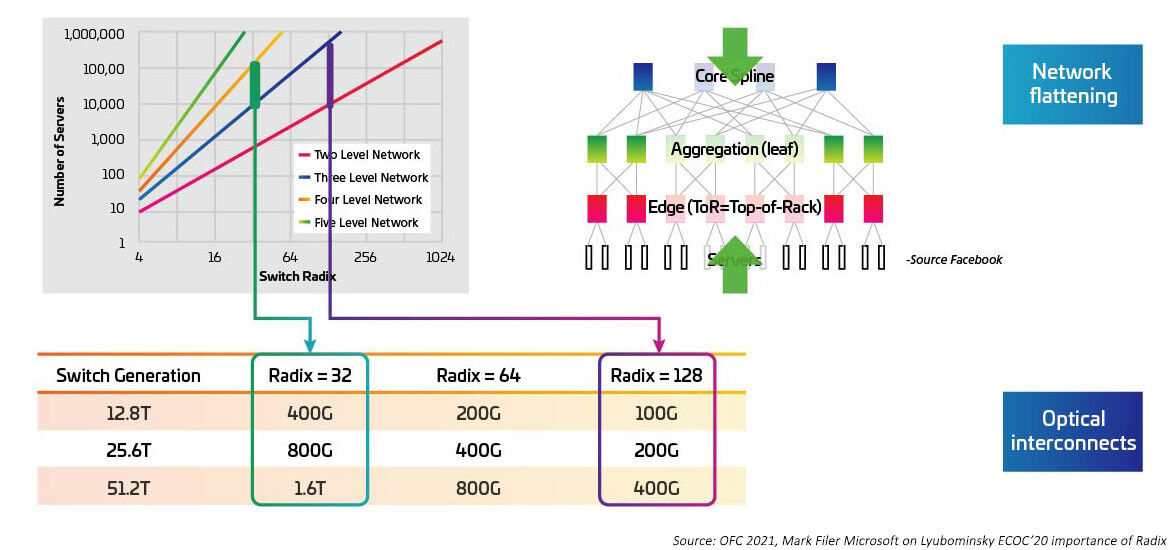
图 4:Effects of higher Radix switches on switch bandwidth
与基数和交换速度的提高密切相关的是从架顶式 (ToR) 拓扑向行中 (MoR) 或行尾 (EoR) 配置的转变,以及结构化的好处 布线方法适用于促进行内服务器和 MoR/EoR 交换机之间的许多连接。 使用新的高基交换机需要以更高的效率管理大量服务器附件的能力。 这反过来又需要新的光学模块和结构化布线,例如 IEEE802.3cm 标准中定义的那些。 IEEE802.3cm 标准支持可插拔收发器的优势,可与大型数据中心的高速服务器网络应用一起使用,定义一个 QSFP-DD 收发器的八个主机连接。
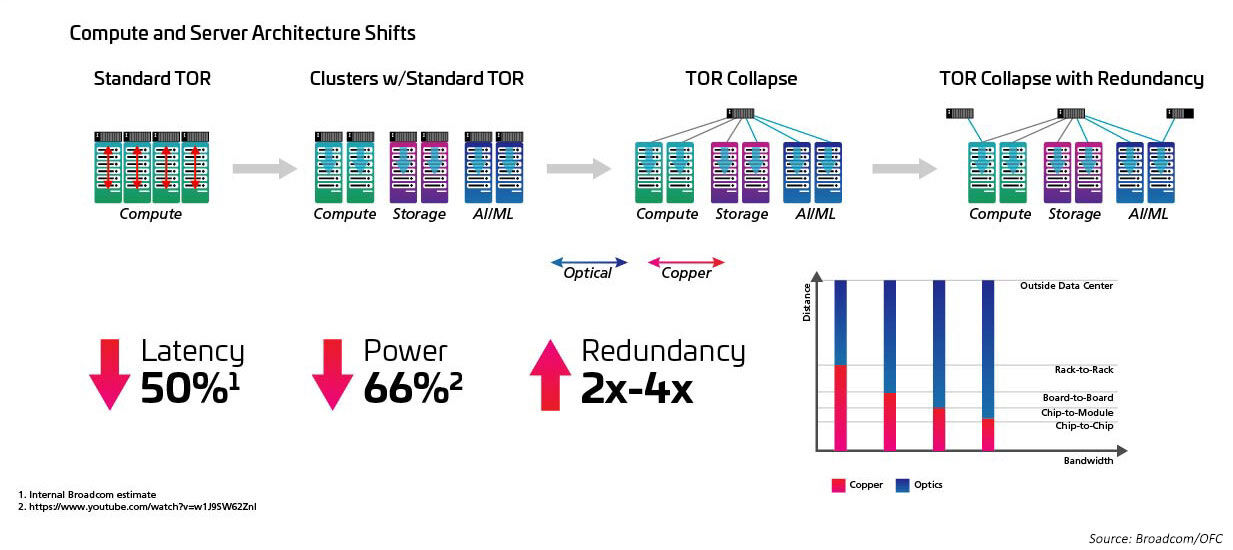
图 5:架构从 ToR 转变为 MoR/EoR
收发器技术
正如 QSFP28 外形尺寸的采用通过提供高密度和低功耗推动了 100G 的采用一样,新的收发器外形尺寸正在实现向 400G 和 800G 的飞跃。 当前的 SFP、SFP+ 或 QSFP+ 光学器件足以实现 200G 链路速度。 然而,跃升至 400G 需要将收发器的密度提高一倍。 没问题。
QSFP-双密度 (QSFP-DD7) 和八进制(2 倍四倍)小型可插拔 (OSFP8) 多源协议 (MSA) 使网络能够将与 ASIC 的电气 I/O 连接数量增加一倍。 这不仅允许汇总更多 I/O 以达到更高的聚合速度,还允许 ASIC I/O 连接的总数到达网络。
具有 32 个 QSFP-DD 端口的 1U 交换机外形与 256 (32x8) 个 ASIC I/O 匹配。 这样,我们既可以在交换机之间建立高速链路(8*100或800G),又可以在附加服务器时保持大连接数。
新的收发器格式

图 6:OSFP 与 QSFP-DD 收发器
随着 OEM 试图进入超大规模和云规模数据中心的好位置,400G 的光学市场受到成本和性能的推动。 2017 年,CFP8 成为第一代 400G 模块规格,用于核心路由器和 DWDM 传输客户端接口。 CFP8 收发器是 CFP MSA 指定的 400G 外形尺寸类型。模块尺寸略小于 CFP2,而光学器件支持 CDAUI-16 (16x25G NRZ) 或 CDAUI-8 (8x50G PAM4) 电气 I/O。带宽密度方面,分别支持CFP和CFP2收发器8倍和4倍的带宽密度。
“第二代”400G 外形模块采用 QSFP-DD 和 OSFP。 QSFP-DD 收发器向后兼容现有的 QSFP 端口。它们建立在现有光模块 QSFP+ (40G)、QSFP28 (100G) 和 QSFP56 (200G) 的成功之上。
OSFP 与 QSFP-DD 光学器件一样,支持使用 8 个通道而不是 4 个通道。两种类型的模块都支持 1RU 卡(交换机)中的 32 个端口。为了支持向后兼容性,OSFP 需要一个 OSFP-to-QSFP 适配器。
调制方案
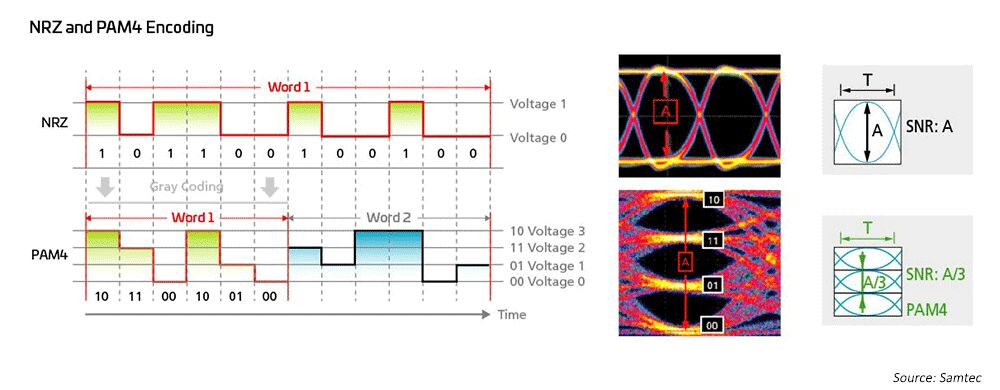
图 7:使用更高速的调制方案来支持 50G 和 100G 技术
网络工程师长期以来一直在为 1G、10G 和 25G 使用不归零 (NRZ) 调制,并使用主机端前向纠错 (FEC) 来实现更远距离的传输。 为了从 40G 到 100G,业界简单地转向并行化 10G/25G NRZ 调制,同时利用主机端 FEC 来实现更长的距离。 在实现 200G/400G 和更快的速度时,需要新的解决方案。
因此,光网络工程师采用了四级脉冲幅度调制(PAM4)来实现超高带宽网络架构; PAM4 是 400GPAM4 的当前解决方案。 这在很大程度上基于 IEEE802.3,它已经为多模 (MM) 和单模 (SM) 应用完成了速率高达 400G (802.3bs/cd/cu) 的新以太网标准。 有多种分线选项可用于适应大型数据中心中的不同网络拓扑。
更复杂的调制方案意味着需要能够提供更好的回波损耗和衰减的基础设施。
预测——OSFP 与 QSFP-DD
关于 OSFP 与 QSFP-DD,现在判断行业将走向何方还为时过早。这两种外形尺寸都得到的数据中心以太网交换机供应商的支持,并且都拥有大量的客户支持。也许企业会更喜欢 QSFP-DD 作为对当前基于 QSFP 的光学器件的增强。随着 OSFP-XD 的引入,OSFP 似乎正在推动地平线的扩展,将通道数量扩展到 16 个,并着眼于未来 200G 的通道速率。
对于高达 100G 的速度,QSFP 已成为选解决方案,因为与双工收发器相比,它具有尺寸、功率和成本优势。 QSFP-DD 在此成功的基础上提供了向后兼容性,允许在具有新 DD 接口的交换机中使用 QSFP 收发器。
展望未来,许多人认为 100G QSFP-DD 封装将在未来几年流行。 OSFP 技术可能更适合 DCI 光链路或那些特别需要更高功率和更多光 I/O 的链路。 OSFP 支持者设想在未来出现 1.6T 甚至 3.2T 收发器。

联合封装光学器件 (CPO) 提供了通往 1.6T 和 3.2T 的替代路径。但 CPO 将需要一个新的生态系统,该生态系统可以将光学器件移近交换机 ASIC,以在降低功耗的同时实现更高的速度。该轨道正在光互联网络论坛 (OIF) 中开发。 OIF 现在正在讨论可能最适合“下一个速率”的技术,许多人主张将其翻倍至 200G。其他选项包括更多的车道——可能是 32 条,因为一些人认为最终将需要更多的车道和更高的车道率,以以可承受的网络成本跟上网络需求。
唯一确定的预测是,布线基础设施必须具有内置的灵活性,以支持您未来的网络拓扑和链路要求。虽然天文学家长期以来一直认为“每个光子都很重要”,因为网络设计人员希望将每比特的能量降低到几 pJ/Bit9,但每个级别的守恒都很重要。高性能布线将有助于减少网络开销。
未完待续……
当前标题:数据中心如何向400G/800G迁移?
文章源于:https://www.cdcxhl.com/news25/204575.html
成都网站建设公司_创新互联,为您提供微信小程序、手机网站建设、软件开发、关键词优化、网站营销、网站制作
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
猜你还喜欢下面的内容
- 虚拟主机应该如何解决电信网通间互联互通 2022-10-11
- ssl证书怎么购买?要多少钱? 2022-10-11
- 虚拟服务器的4个应用场景 2022-10-11
- 漫画行业租用香港服务器,靠谱吗? 2022-10-11
- 边缘计算、边缘网络和边缘数据管理如何协同工作 2022-10-11
- 租用国内免备案空间靠谱吗? 2022-10-11
- ca申请证书有什么用 2022-10-11

- 私有云、公共云、混合云安全性的优点和缺点 2022-10-11
- 网站ssl证书多少钱才是合理的呢 2022-10-11
- 海外空间租用的优势有哪些? 2022-10-11
- 扩展数据中心规模将迎来更好的未来 2022-10-11
- 护卫神主机大师(Linux)登录账户密码忘记的解决办法 2022-10-11
- 香港服务器数据中心好不好? 2022-10-11
- 云计算成本的7个秘密 2022-10-11
- 安装ssl证书需要域名备案吗,应用IP申请ssl证书的注意事项 2022-10-11
- 企业对控制和可见性的需求仍然减缓云计算应用 2022-10-11
- 数字签名证书是什么? 2022-10-11
- 怎么办理数字证书? 2022-10-11
- 如何验证https证书是否一致?域名证书需要多少钱? 2022-10-11