聊聊大数据Lambda架构
2021-02-04 分类: 网站建设
Lambda Architecture 概念
Mathan Marz的大作Big Data: Principles and best practices of scalable real-time data systems介绍了Lambda Architecture的概念,用于在大数据架构中,如何让real-time与batch job更好地结合起来,以达成对大数据的实时处理。
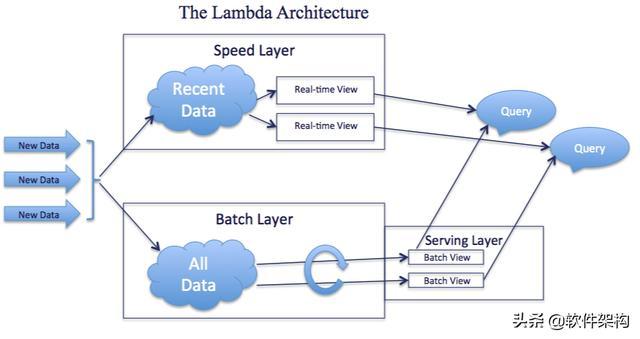
大数据平台中包括批量计算的Batch Layer和实时计算的Speed Layer,通过在一套平台中将批计算和流计算整合在一起。
例如使用Hadoop MapReduce、Spark进行批量数据的处理,使用Apache Storm、Spark Streaming 进行实时数据的处理。
这种架构在一定程度上解决了不同计算类型的问题,但是带来的问题是框架太多,会导致平台复杂度过高、运维成功高等。
Lambda架构的主要思想就是将大数据系统构建为多个层次,如下图所示:
我们来梳理一下他们是如何分工协助的:
- 首先new data作为整个数据系统的数据源头,Batch Layer作为数据的批处理层次对原始数据进行加工与处理,并且将处理的数据结果的Batch View输入到Serving Layer。(这里对应的是全量数据)
- Speed Layer对于实时增加的数据进行处理,生成对增量数据计算结果的Real-time View。(这里对应的是增量数据)
- 最终用户查询是通过Batch View与Real-time View相结合的形式将最终结果呈现出来。
基于Lambda架构,一旦数据通过Batch layer进入到Serving layer,在Real-time view中的相应结果就不再需要了。
小 结
Lambda架构结合了实时处理与批处理的结果,很好的反馈了查询需求,并且在速度和可靠性之间求取了平衡,具有足够的扩展性。理想状态下,所有的查询都可以定位成一个函数:
- Query = Function(Data)
但是,若数据达到相当大的一个级别(例如PB),且还需要支持实时查询时,就需要耗费非常庞大的资源。
而Lambda架构将数据和计算系统进行细分:
- Query = Batch(Old_Data) + RealTime(New_Data)
但是这种架构同样存在一些问题:需要运维两套不同的计算系统,并且合并查询结果,这一定程序上带来了复杂性的增加。
网页名称:聊聊大数据Lambda架构
本文路径:https://www.cdcxhl.com/news/99044.html
成都网站建设公司_创新互联,为您提供动态网站、定制开发、品牌网站设计、搜索引擎优化、网站改版、全网营销推广
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
猜你还喜欢下面的内容
- 百度SEO怎么收费?如何推广才有流量? 2021-02-04
- 一分钟带你了解建设网站对于企业的真正意义 2021-02-04
- 智能客服为何能够快速渗透各行各业? 2021-02-04
- 模板建站类型有哪些?看看你适合做哪种网站 2021-02-04
- 跨境电商运营模式包括哪些? 2021-02-04
- 你的跨境电商平台,如何选择服务器? 2021-02-04
- 小程序与APP和公众号的区别? 2021-02-04

- 想实现移动广告规模变现 你必须了解的关键要素 2021-02-04
- SSL证书抵御企业网络攻击的风险 2021-02-04
- 跨境电商卖家如何打开日本电商市场 2021-02-04
- 安装SSL安全证书对网站有哪些影响 2021-02-04
- 计算机网络太难?了解这一篇就够了 2021-02-04
- 微信又上线新功能!网友炸了 2021-02-04
- 数据安全三部曲:存储、传输与使用 2021-02-04
- 域名抢注的技巧及域名到期后的几个状态 2021-02-04
- 电商时代 | 如何抓住年轻人的市场 2021-02-04
- 沉寂多年,无服务器爆发,其硬核是什么? 2021-02-04
- 域名对企业重要不重要吗?有什么影响 2021-02-04
- 现代企业为什么要开发小程序 2021-02-04