顺序表和单链表的对比(十二)
我们在之前学习了线性表和单链表的相关特性,本节博客我们就来看看它们的区别。首先提出一个问题:如何判断某个数据元素是否存在于线性表中?那肯定是直接遍历一遍了,我们来看看代码
成都创新互联公司拥有十多年成都网站建设工作经验,为各大企业提供成都网站建设、网站建设服务,对于网页设计、PC网站建设(电脑版网站建设)、重庆APP软件开发、wap网站建设(手机版网站建设)、程序开发、网站优化(SEO优化)、微网站、申请域名等,凭借多年来在互联网的打拼,我们在互联网网站建设行业积累了很多网站制作、网站设计、网络营销经验,集策划、开发、设计、营销、管理等网站化运作于一体,具备承接各种规模类型的网站建设项目的能力。
#include <iostream>
#include "LinkList.h"
using namespace std;
using namespace DTLib;
int main()
{
LinkList<int> list;
for(int i=0; i<5; i++)
{
list.insert(0, i);
}
for(int i=0; i<list.length(); i++)
{
if( list.get(i) == 3 )
{
cout << list.get(i) << endl;
}
}
return 0;
}我们判断 3 是都存在于当前线性表中,如果存在,便输出。看看输出结果

我们看到在查找的时候还得去手动遍历一遍,感觉很麻烦。那么我们在之前的实现中,少了一个操作,那便是查找操作 find。它可以为线性表(List)增加一个查找操作,原型为 int find(const T& e) const;参数为带查找的数据元素;返回值:>=0 时,则表示数据元素在线性表中第一次出现的位置;为 -1 时,则表示数据元素不存在。下面我们看看数据元素查找的示例代码,如下
LinkList<int> list;
for(int i=0; i<5; i++)
{
list.insert(0, i);
}
cout << list.find(3) << endl; // ==> 1下来我们在 List.h 源码中添加 find 操作,如下
List.h 源码
#ifndef LIST_H
#define LIST_H
#include "Object.h"
namespace DTLib
{
template < typename T >
class List : public Object
{
protected:
List(const List&);
List& operator= (const List&);
public:
List() {}
virtual bool insert(const T& e) = 0;
virtual bool insert(int i, const T& e) = 0;
virtual bool remove(int i) = 0;
virtual bool set(int i, const T& e) = 0;
virtual bool get(int i, T& e) const = 0;
virtual int find(const T& e) const = 0;
virtual int length() const = 0;
virtual void clear() = 0;
};SeqList.h 源码
#ifndef SEQLIST_H
#define SEQLIST_H
#include "List.h"
#include "Exception.h"
namespace DTLib
{
template < typename T >
class SeqList : public List<T>
{
protected:
T* m_array;
int m_length;
public:
bool insert(int i, const T& e)
{
bool ret = ((0 <= i) && (i <= m_length));
ret = ret && (m_length < capacity());
if( ret )
{
for(int p=m_length-1; p>=i; p--)
{
m_array[p+1] = m_array[p];
}
m_array[i] = e;
m_length++;
}
return ret;
}
bool insert(const T& e)
{
return insert(m_length, e);
}
bool remove(int i)
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
for(int p=i; p<m_length-1; p++)
{
m_array[p] = m_array[p+1];
}
m_length--;
}
return ret;
}
bool set(int i, const T& e)
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
m_array[i] = e;
}
return ret;
}
bool get(int i, T& e) const
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
e = m_array[i];
}
return ret;
}
int find(const T& e) const // O(n)
{
bool ret = -1;
for(int i=0; i<m_length; i++)
{
if( m_array[i] == e )
{
ret = i;
break;
}
}
return ret;
}
int length() const
{
return m_length;
}
void clear()
{
m_length = 0;
}
T& operator[] (int i)
{
if( (0 <= i) && (i < m_length) )
{
return m_array[i];
}
else
{
THROW_EXCEPTION(IndexOutOfBoundsException, "Parameter i is invalid ...");
}
}
T operator[] (int i) const
{
return (const_cast<SeqList<T>&>(*this))[i];
}
virtual int capacity() const = 0;
};
}
#endif // SEQLIST_HLinkList.h 源码
#ifndef LINKLIST_H
#define LINKLIST_H
#include "List.h"
#include "Exception.h"
namespace DTLib
{
template < typename T >
class LinkList : public List<T>
{
protected:
struct Node : public Object
{
T value;
Node* next;
};
mutable struct : public Object
{
char reserved[sizeof(T)];
Node* next;
} m_header;
int m_length;
Node* position(int i) const
{
Node* ret = reinterpret_cast<Node*>(&m_header);
for(int p=0; p<i; p++)
{
ret = ret->next;
}
return ret;
}
public:
LinkList()
{
m_header.next = NULL;
m_length = 0;
}
bool insert(const T& e)
{
return insert(m_length, e);
}
bool insert(int i, const T& e)
{
bool ret = ((0 <= i) && (i <= m_length));
if( ret )
{
Node* node = new Node();
if( node != NULL )
{
Node* current = position(i);
node->value = e;
node->next = current->next;
current->next = node;
m_length++;
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "No memory to insert new element ...");
}
}
}
bool remove(int i)
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
Node* current = position(i);
Node* toDel = current->next;
current->next = toDel->next;
delete toDel;
m_length--;
}
return ret;
}
bool set(int i, const T& e)
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
position(i)->next->value = e;
}
return ret;
}
T get(int i) const
{
T ret;
if( get(i, ret) )
{
return ret;
}
else
{
THROW_EXCEPTION(IndexOutOfBoundsException, "Invaild parameter i to get element ...");
}
}
bool get(int i, T& e) const
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
e = position(i)->next->value;
}
return ret;
}
int find(const T& e) const
{
int ret = -1;
int i = 0;
Node* node = m_header.next;
while( node )
{
if( node->value == e )
{
ret = i;
break;
}
else
{
node = node->next;
i++;
}
}
return ret;
}
int length() const
{
return m_length;
}
void clear()
{
while( m_header.next )
{
Node* toDel = m_header.next;
m_header.next = toDel->next;
delete toDel;
}
m_length = 0;
}
~LinkList()
{
clear();
}
};
}
#endif // LINKLIST_H那么此时的 main.cpp 就可以写成这样的了
#include <iostream>
#include "LinkList.h"
using namespace std;
using namespace DTLib;
int main()
{
LinkList<int> list;
for(int i=0; i<5; i++)
{
list.insert(0, i);
}
cout << list.find(3) << endl;
return 0;
}我们来看看结果

我们来查找下 -3 呢

我们看到如果查找的元素在里面,则返回 1;如果没有,则返回 -1。那么我们如果查找的是类呢?那程序还会编译通过吗?我们来看看,main.cpp 源码如下
#include <iostream>
#include "LinkList.h"
using namespace std;
using namespace DTLib;
class Test
{
int i;
public:
Test(int v = 0)
{
i = v;
}
};
int main()
{
Test t1(1);
Test t2(3);
Test t3(3);
LinkList<Test> list;
return 0;
}编译结果如下

编译报错了,我们并没有改动 LinkList 中的代码,为什么这块会报错呢?那么此时我们想要让两个类对象进行相等的比较,可是我们并没有定义 == 操作符,此时肯定会出错。那么我们在类 Test 中进行 == 操作符的定义,如下
class Test
{
int i;
public:
Test(int v = 0)
{
i = v;
}
bool operator == (const Test& obj)
{
return true;
}
};我们再来编译下,看看结果

编译是通过的,那么我们此时便觉得奇怪了。我们为什么要在 Test 类中定义 == 操作符呢,此时最好的解决办法是在顶层父类 Object 中添加 == 和 != 操作符,然后将 Test 类继承自 Object 类就可以了。
Object.h 源码
#ifndef OBJECT_H
#define OBJECT_H
namespace DTLib
{
class Object
{
public:
void* operator new (unsigned int size) throw();
void operator delete (void* p);
void* operator new[] (unsigned int size) throw();
void operator delete[] (void* p);
bool operator == (const Object& obj);
bool operator != (const Object& obj);
virtual ~Object() = 0;
};
}
#endif // OBJECT_HObject.cpp 源码
#include "Object.h"
#include <cstdlib>
namespace DTLib
{
void* Object::operator new (unsigned int size) throw()
{
return malloc(size);
}
void Object::operator delete (void* p)
{
free(p);
}
void* Object::operator new[] (unsigned int size) throw()
{
return malloc(sizeof(size));
}
void Object::operator delete[] (void* p)
{
free(p);
}
bool Object::operator == (const Object& obj)
{
return (this == &obj);
}
bool Object::operator != (const Object& obj)
{
return (this != &obj);
}
Object::~Object()
{
}
}此时的 main.cpp 代码如下
#include <iostream>
#include "LinkList.h"
using namespace std;
using namespace DTLib;
class Test : public Object
{
int i;
public:
Test(int v = 0)
{
i = v;
}
bool operator == (const Test& obj)
{
return (i == obj.i);
}
};
int main()
{
Test t1(1);
Test t2(3);
Test t3(3);
LinkList<Test> list;
list.insert(t1);
list.insert(t2);
list.insert(t3);
cout << list.find(t2) << endl;
return 0;
}我们来看看编译输出结果

那么我们在 main.cpp 测试代码中将 t1, t2, t3 对象插入到 list 中,然后查找 t2 是否存在,那么它肯定是存在的,因此会输出 1。那么我们来分析下顺序表和单链表的时间复杂度的对比,如下
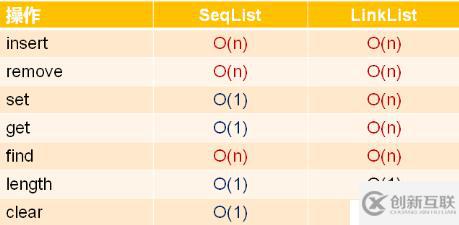
我们看到顺序表只有三个 O(n) ,而单链表几乎是全部是 O(n)。从时间复杂度上来看,似乎顺序表更占优势,那么我们在平时的开发中,为什么经常见到的是单链表而不是顺序表呢?在实际的工程开发中,时间复杂度只是一个参考指标,对于内置基础类型,顺序表和单链表的效率不相上下,而对于自定义类型来说,顺序表在效率上低于单链表。在插入和删除操作中,顺序表涉及大量数据对象的复制操作,而单链表只涉及指针操作,效率与数据对象无关。对于数据访问,顺序表是随机访问,可直接定位数据对象;而对于单链表来说是顺序访问,必须从头访问数据对象,无法直接定位。
一般在工程开发中,顺序表主要用于:数据元素类型相对简单,不涉及深拷贝;数据元素相对稳定,访问操作远多于插入和删除操作。单链表主要用于:数据元素的类型相对复杂,复制操作相对耗时;数据元素不稳定,需要经常插入和删除,访问操作较少的情况。通过今天的学习,总结如下:1、线性表中元素的查找依赖于相等比较操作符(==);2、顺序表适用于访问需求量较大的场合(随机访问);3、单链表适用于数据元素频繁插入删除的场合(顺序访问);4、当数据类型相对简单时,顺序表和单链表的效率不相上下。
本文题目:顺序表和单链表的对比(十二)
网页链接:https://www.cdcxhl.com/article48/jiesep.html
成都网站建设公司_创新互联,为您提供手机网站建设、网站改版、App开发、标签优化、App设计、电子商务
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 成都外贸网站建设为什么选择美国空间? 2022-06-09
- 外贸网站建设值得注意的四个方面 2016-07-25
- 外贸网站建设需要注意什么?这些事情一定要知道! 2016-02-29
- 深圳建设一个外贸网站需要多少钱?外贸网站建设费用 2022-01-21
- 网站托管_外贸网站建设的重点 2016-08-02
- 外贸网站建设改版需要知道的知识 2022-12-22
- 外贸网站建设要做到“快、简、直、细、严” 2013-04-28
- 外贸网站建设优化四大技巧 2022-10-24
- 外贸网站建设如何才能发挥预期作用四大要点要知晓 2022-08-06
- 外贸网站建设-外贸网站如何利用好社交媒体 2016-11-13
- 分享外贸网站建设的一些体会 2016-11-02
- 外贸网站建设为什么价格这么贵 2015-12-25