Python正则表达式是什么,怎么用
本篇内容介绍了“Python正则表达式是什么,怎么用”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
成都创新互联公司长期为上千客户提供的网站建设服务,团队从业经验10年,关注不同地域、不同群体,并针对不同对象提供差异化的产品和服务;打造开放共赢平台,与合作伙伴共同营造健康的互联网生态环境。为都兰企业提供专业的成都网站制作、成都网站建设、外贸营销网站建设,都兰网站改版等技术服务。拥有10年丰富建站经验和众多成功案例,为您定制开发。
一、re
我们先介绍一下re模块下的方法,这个是我们拿来就可以用的,当然前提是知道一点正则表达式,如果对正则表达式完全不了解,可以先看一下后面正则表达式部分。
1.1 match
match方法从字符串的起始位置匹配一个模式,如果没有匹配成功match就返回None
re.match(pattern, string, flags=0)
pattern:正则表达式 string:待匹配的字符串 flags:匹配模式(是否区分大小写、单行匹配还是多行匹配)
match返回的是一个re.Match对象,后面会详细介绍Match中的方法。
import re content = "Cats are smarter than dogs" # 第一个参数是正则表达式,re.I表示忽略大小写 match = re.match(r'(cats)', content, re.I) print(type(match)) print(match.groups()) match = re.match(r'dogs', content, re.I) print(type(match)) # print(match.groups())
match主要是用于捕获分组,所以尽量使用分组模式,不然匹配了也无法获取结果,flag是re.I表示忽略大小写。
另外非常重要的一点match只会找第一个匹配的分组:
import re content = "aa aa smarter aa dogs" match = re.match(r'(aa)', content, re.I) if match: print(match.groups())
上面输出的是:('aa',)
1.2 search
扫描整个字符串并返回第一个成功的匹配,search和match不同之处在于,search没有强制要求从开始匹配。
re.search(pattern, string, flags=0)
import re content = '+123abc456*def789ghi' # \w能够匹配[a-zA-Z0-9_],+表示至少匹配一次 reg = r"\w+" match = re.search(reg, content) if match: print(match.group())
1.3 sub
替换字符串中的匹配项
re.sub(pattern, repl, string, count=0, flags=0)
pattern: 正则表达式 repl: 替换的字符串,可以是函数 string: 要被查找替换的字符串 count: 模式匹配后替换的最大次数,默认0表示替换所有的匹配,可选 flags: 可选参数,匹配模式,默认为0
替换和谐字符:
import re content = "do something fuck you" rs = re.sub(r'fuck', "*", content) print(rs)
非常简单,把fuck替换为*
现在需求变了,我们需要被屏蔽的单词有几个字符,就替换为几个*,怎么处理?
import re def calcWords(matched): num = len(matched.group()) return str(num * '*') content = "do something fuck you" rs = re.sub(r'fuck', calcWords, content) print(rs)
替换的字符串可以使用函数,我们在函数中就可以非常容易的计算了
1.4 findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
re.findall(pattern, string, flags=0)
pattern:正则表达式 string: 待匹配的字符串 flags: 可选参数,匹配模式,默认为0
import re content = '+123abc456*def789ghi' reg = r"\d+" rs = re.findall(reg, content) # ['123', '456', '789'] print(rs)
findall有一个让人狂躁的地方是,如果正则表达式中有分组,就只会返回分组中的匹配。
import re content = '+123abc456*def789ghi' reg = r"\d+([a-z]+)" rs = re.findall(reg, content) # ['abc', 'ghi'] print(rs)
1.5 finditer
在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回
re.finditer(pattern, string, flags=0)
pattern:正则表达式 string: 待匹配的字符串 flags: 可选参数,匹配模式,默认为0
import re content = '+123abc456*def789ghi' reg = r"\d+" rss = re.finditer(reg, content) # 123 456 789 for rs in rss: print(rs.group(), end=' ')
finditer和findall差不多,但是没有findall的那个令人狂躁的如果有分组只返回分组的问题。
import re content = '+123abc456*def789ghi' reg = r"\d+([a-z]+)" rss = re.finditer(reg, content) # 123abc 789ghi for rs in rss: print(rs.group(), end=' ')
1.6 split
按照匹配的子串将字符串分割后返回列表
re.split(pattern, string, maxsplit=0, flags=0)
import re content = '+123abc456*def789ghi' reg = r"\d+" rs = re.split(reg, content) print(rs)
1.7 compile
编译正则表达式,生成一个正则表达式Pattern对象,前面的方法都会先调用这个方法得到一个Pattern对象,然后再使用Pattern对象的同名方法。
接下来,我们马上就会介绍一下Pattern对象。
re.compile(pattern, flags=0)
二、Pattern
Pattern对象是一个编译好的正则表达式,Pattern不能直接实例化,必须使用re.compile()进行构造。
2.1 属性
| 属性 | 说明 |
|---|---|
| pattern | 编译使用的正则表达式 |
| flags | 编译时用的匹配模式,数字形式 |
| groups | 表达式中分组的数量 |
| groupindex | 字典,键是分组的别名,值是分组的编号 |
import re
pattern = re.compile(r'(\w+)(?P<gname>.*)', re.S)
# pattern: (\w+)(?P<gname>.*)
print("pattern:", pattern.pattern)
# flags: 48
print("flags:", pattern.flags)
# groups: 2
print("groups:", pattern.groups)
# groupindex: {'gname': 2}
print("groupindex:", pattern.groupindex)2.2 方法
前面re模块中介绍的方法对于Pattern都适用,只是少了pattern参数
其实很简单,re模块中的方法使用pattern参数,通过re.compile方法构造了一个Pattern对象
三、Match
Match对象是一次匹配的结果,包含此次匹配的信息,可以使用Match提供的属性或方法来获取这些信息。
3.1 属性
| 属性 | 说明 |
|---|---|
| string | 匹配时使用的文本 |
| re | 获取Pattern的表达式 |
| pos | 文本中正则表达式开始搜索的位置 |
| endpos | 文本中正则表达式结束搜索的位置 |
| lastindex | 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None |
| lastgroup | 最后一个被捕获的分组的别名。如果没有被捕获的分组,将为None |
import re
content = "123456<H1>first</h2>123456"
reg = r'\d+<[hH](?P<num>[1-6])>.*?</[hH](?P=num)>'
match = re.match(reg, content)
# string: 123456<H1>first</h2>123456
print("string:", match.string)
# re: re.compile('\\d+<[hH](?P<num>[1-6])>.*?</[hH](?P=num)>')
print("re:", match.re)
# pos: 0
print("pos:", match.pos)
# endpos: 26
print("endpos:", match.endpos)
# lastindex: 1
print("lastindex:", match.lastindex)
# lastgroup: num
print("lastgroup:", match.lastgroup)感觉Match的属性稍微有些鸡肋。
3.2 方法
| 方法 | 说明 |
|---|---|
| groups() | 获取所有分组匹配的字符串,返回元组 |
| group([group1,……]) | 获取分组匹配到的字符串,返回元组 |
| start(group) | 获取分组在原始字符串中的开始匹配位置 |
| end(group) | 获取分组在原始字符串中的结束匹配位置 |
| span(group) | 获取分组在原始字符串中的开始和结束匹配位置,元组 |
| groupdict() | 获取有别名的分组匹配的字符串,返回字典,别名是键 |
| expand(template) | template字符串中可以通过别名和编号引用匹配字符串 |
注意:无参数group等价于group(0),返回整个匹配到的字符串
import re
match = re.match(r'(\w+) (\w+) (?P<name>.*)', 'You love sun')
# groups(): ('You', 'love', 'sun')
print("groups():", match.groups())
# group(2,3): ('love', 'sun')
print("group(2,3):", match.group(2, 3))
# start(2): 4
print("start(2):", match.start(2))
# end(2): 8
print("end(2):", match.end(2))
# span(2): (4, 8)
print("span(2):", match.span(2))
# groupdict(): {'name': 'sun'}
print("groupdict():", match.groupdict())
# expand(r'I \2 \1!'): I love You!
print(r"expand(r'I \2 \1!'):", match.expand(r'I \2 \1!'))上面Match中的方法还是比较重要的,因为我们基本最后都是通过Match对象中的方法来获取匹配的
四、正则表达式
4.1 常用
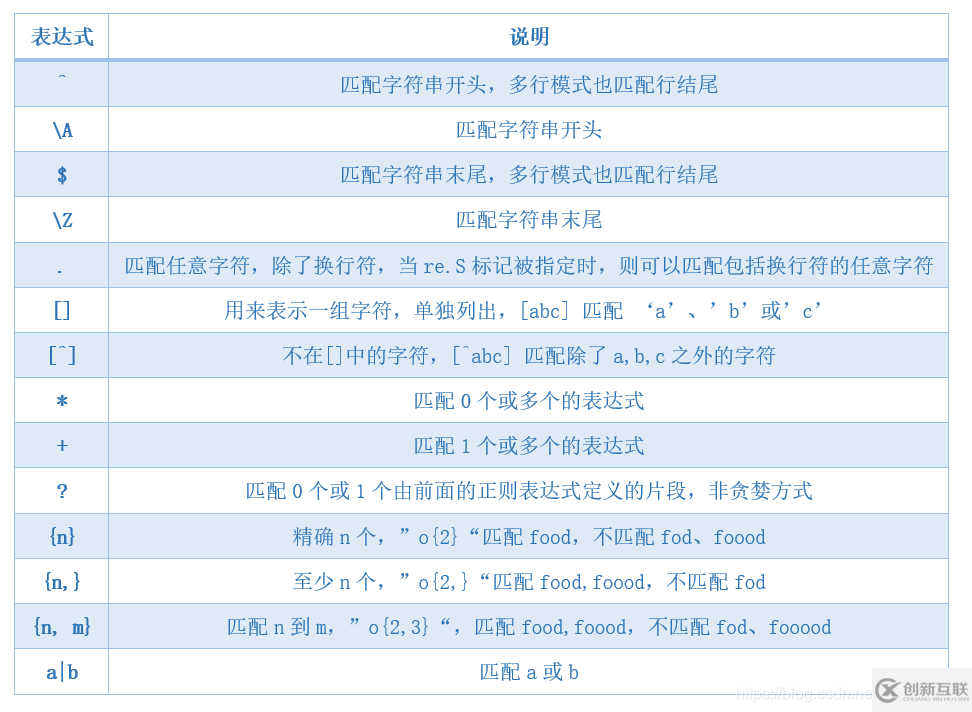
| 表达式 | 说明 |
|---|---|
| . | 匹配任意字符,除了换行符,当re.S标记被指定时,则可以匹配包括换行符的任意字符 |
| ? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| + | 匹配1个或多个的表达式 |
| * | 匹配0个或多个的表达式 |
| [] | 用来表示一组字符,单独列出,[abc] 匹配 'a'、'b'或'c' |
| [^] | 不在[]中的字符,[^abc] 匹配除了a,b,c之外的字符 |
| ^ | 匹配字符串开头,多行模式也匹配行结尾 |
| \A | 匹配字符串开头 |
| $ | 匹配字符串末尾,多行模式也匹配行结尾 |
| \Z | 匹配字符串末尾 |
| {n} | 精确n个,"o{2}"匹配food,不匹配fod、foood |
| {n,} | 至少n个,"o{2,}"匹配food,foood,不匹配fod |
| {n, m} | 匹配n到m,"o{2,3}",匹配food,foood,不匹配fod、fooood |
| | | a|b,匹配a或b |
| - | -可以表示区间,[0-9]表示可以匹配0-9中的任意数字 |
最常用的就是.匹配任意字符,a.b就可以匹配abb、acb、adb、a+b、a8b等等
?表示最多匹配一次:abb?可以匹配ab、abb,但是不能匹配abbabb,因为?只是指前一个片段
+表示至少匹配一次:abb+可以匹配abb、abbb、abbbb等等,当时不能匹配ab
*表示0到多次: abb*可以匹配ab、abb、abbb、abbbb等等
[]中有一组字符,字符间的关系是或
4.2 边界空白
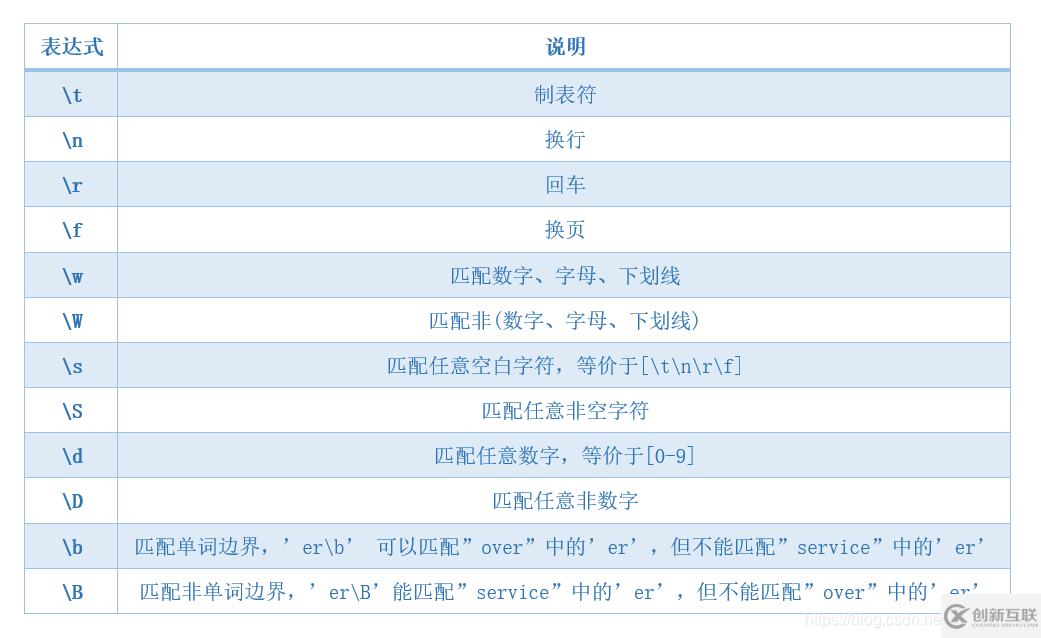
| 表达式 | 说明 |
|---|---|
| \t | 制表符 |
| \n | 换行 |
| \r | 回车 |
| \f | 换页 |
| \w | 匹配数字、字母、下划线,等价于[a-zA-Z0-9_] |
| \W | 匹配非(数字、字母、下划线),等价于[^a-zA-Z0-9_] |
| \s | 匹配空白字符,等价于[\t\n\r\f] |
| \S | 匹配非空字符,等价于[^\t\n\r\f] |
| \d | 匹配数字,等价于[0-9] |
| \D | 匹配非数字,等价于[^0-9] |
| \b | 匹配单词边界,'er\b' 可以匹配"over"中的'er',但不能匹配"service"中的'er' |
| \B | 匹配非单词边界,'er\B'能匹配"service"中的'er',但不能匹配"over"中的'er' |
4.3 分组
| 表达式 | 说明 |
|---|---|
| (re) | 分组匹配,嵌套模式分组计数是从左到右,从外到里 |
| \number | 引用分组,使用\1、\2、\3……访问第1、2、3……分组 |
| (?P<name>) | 指定分组名称,使用name做为分组的别名 |
| (?P=name) | 引用分组名称,通过name应用分组 |

分组最重要的一个作用就是可以回溯,就是引用已经匹配的模式。
思考:html中如何匹配全部h标签?
reg = '<[hH][1-6]>.*?</[hH][1-6]>'
很多朋友可能会写出类似于上面的表达式,有什么问题吗?
看下面的例子:
import re content = ''' <html> <body> <H1>first</h2> <p>p tag</p> <h3>h3</h3> <h4>非法标签</h5> </body> </html> ''' rs = re.findall(r'<[hH][1-6]>.*?</[hH][1-6]>', content) print(rs) rs = re.findall(r'<[hH]([1-6])>.*?</[hH]\1>', content) print(rs) rs = re.findall(r'((<[hH]([1-6])>).*?</[hH]\3>)', content) print(rs) rs = re.findall(r'((<[hH](?P<num>[1-6])>).*?</[hH](?P=num)>)', content) print(rs)
看输出,我们知道:
reg = '<[hH][1-6]>.*?</[hH][1-6]>'
会把'<h4>非法标签</h5>'这一部分也匹配到。
我们可以通过分组,然后引用分组来解决这个问题。
reg1 = '<[hH]([1-6])>.*?</[hH]\1>' reg2 = '((<[hH]([1-6])>).*?</[hH]\3>)'
因为如果有分组,findall之后打印出匹配分组,所以我们使用reg2这个正则表达式。
为什么是\3呢?
因为根据从左到右,从外到里的原则,我们知道([1-6])是第3个分组。
如果觉得不想去数,或者怕数错,那么就可以使用别名的方式。
reg = '((<[hH](?P<num>[1-6])>).*?</[hH](?P=num)>)'
4.4 前后匹配
| 表达式 | 说明 |
|---|---|
| (?=re) | 前向匹配,a(?=\d),匹配数字前面的a |
| (?!re) | 前向反向匹配,a(?!\d),匹配后面不接数字的a |
| (?<=re) | 向后匹配,(?<=\d)a,匹配前面是数字的a |
| (?< !re) | 向后反向匹配,(?< !\d)a,匹配前面不是数字的a |
前后匹配也是一个非要有用的功能,它的一个重要特性是不消费re部分,下面看一个例子帮助理解。
import re content = ''' http://www.mycollege.vip https://mail.mycollege.vip ftp://ftp.mycollege.vip ''' # 向前匹配,匹配:前面的schema,不消费: rs = re.findall(r'.+(?=:)', content) # ['http', 'https', 'ftp'] print(rs) # 向后匹配,匹配//后面的域名,不消费// rs = re.findall(r'(?<=//).+', content) # ['www.mycollege.vip', 'mail.mycollege.vip', 'ftp.mycollege.vip'] print(rs) # 向后匹配,匹配$后面的数字,不消费$ price = ''' item1:$99.9 CX99:$199 ZZ88:$999 ''' rs = re.findall(r'(?<=\$)[0-9.]+', price) # ['99.9', '199', '999'] print(rs) # 前后匹配 title = ''' <head> <title>this is title</title> </head> ''' rs = re.findall(r'(?<=<title>).*(?=</title>)', title) # ['this is title'] print(rs)
4.5 其他匹配
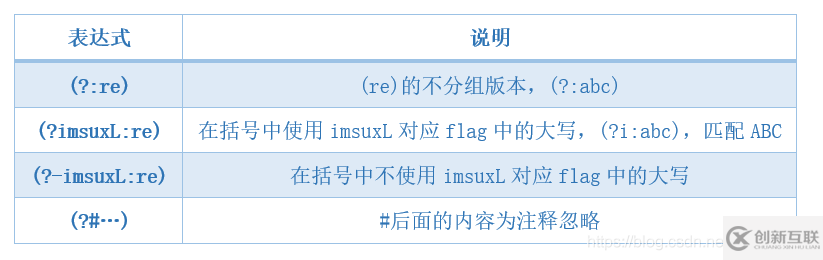
| 表达式 | 说明 |
|---|---|
| (?:re) | (re)的不分组版本,(?:abc){2},匹配abcabc |
| (?imsuxL:re) | 在括号中使用imsuxL对应flag中的大写,(?i:abc),匹配ABC |
| (?-imsuxL:re) | 在括号中不使用imsuxL对应flag中的大写 |
| (?#...) | #后面的内容为注释忽略 |
4.6 flags
| 模式 | 说明 |
|---|---|
| re.I | IGNORECASE,使匹配对大小写不敏感 |
| re.M | MULTILINE,多行匹配,影响^和$ |
| re.S | DOTALL,点任意匹配模式,使.匹配包括换行在内的所有字符 |
| re.X | VERBOSE,详细模式,忽略表达式中的空白和注释,并允许使用#添加注释 |
| re.L | LOCALE |
| re.U | UNICODE |

re.M是多行匹配模式:
^可以匹配字符串开头,也可以匹配行的开头,字符串中换行符\n之后的位置
$可以匹配字符串结尾,也可以匹配行的结尾,字符串中换行符\n之前的位置
单行模式:
^等价于\A
$等价于\Z
import re content = ''' first line second line third line ''' # ['first', 'second', 'third'] rs = re.findall(r'^(.*) line$', content, re.M) # [] # rs = re.findall(r'^(.*) line$', content) # [] # rs = re.findall(r'\A(.*) line\Z', content, re.M) print(rs)
上面的小例子多行模式可以匹配成功,单行模式不能,因为单行模式^不能匹配\n后的位置,所以开头就不匹配。
反过来,我们在决定是否使用re.M的时候,只需要考虑正则表达式中有没有^和$,如果没有肯定是不需要的,如果有,那么思考是否需要匹配\n(换行符)前后的位置,需要则加上re.M。
re.L和re.U比较不好理解,2.x和3.x的变化也很大,基本用不上,有兴趣可以看一下文档。
“Python正则表达式是什么,怎么用”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注创新互联网站,小编将为大家输出更多高质量的实用文章!
文章名称:Python正则表达式是什么,怎么用
文章URL:https://www.cdcxhl.com/article40/jieeeo.html
成都网站建设公司_创新互联,为您提供小程序开发、品牌网站制作、外贸网站建设、Google、App开发、营销型网站建设
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 搜索引擎优化这些关键可以提高网站的排名 2023-04-17
- 郑州网站优化_营销平台如何进行搜索引擎优化 2020-12-19
- 揭晓网站做搜索引擎优化但仍然没有排名的原因 2014-03-06
- 搜索引擎优化之关键词选择 2017-02-27
- 中小型企业网站制作如果不利于搜索引擎优化等于白做 2022-05-22
- 搜索引擎优化 2023-02-15
- 成都网络推广公司,百度搜索引擎优化有什么样比较好的方法 2023-04-26
- 建议初学者SEOER对待搜索引擎优化资料不要照本宣读 2023-04-06
- 标题标签搜索引擎优化:正确使用H1到H6 2013-11-07
- 适合搜索引擎优化的网站 网站建设有啥技巧 2016-04-20
- 您的网站设计会影响其搜索引擎优化 2022-09-01
- 语音搜索和搜索引擎优化B2B营销人员需要关注 2014-12-26