Unity中DOTS要实现的特点有哪些
小编给大家分享一下Unity中DOTS要实现的特点有哪些,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
专注于为中小企业提供网站设计、做网站服务,电脑端+手机端+微信端的三站合一,更高效的管理,为中小企业丹江口免费做网站提供优质的服务。我们立足成都,凝聚了一批互联网行业人才,有力地推动了数千家企业的稳健成长,帮助中小企业通过网站建设实现规模扩充和转变。
DOTS 要实现的特点有:
性能的准确性。我们希望的效果是:如果循环因为某些原因无法向量化(Vectorization,可以参考 StackOverflow 的问题),它应该会出现编译器错误,而不是使代码运行速度慢8倍,并得到正确结果,完全不报错。
跨平台架构特性。我们编写的输入代码无论是面向 iOS 系统还是 Xbox,都应该是相同的。
我们应该有不错的迭代循环。在修改代码时,可以轻松查看为所有架构生成的机器代码。机器代码“查看器”应该很好地说明或解释所有机器指令的行为。
安全性。大多数游戏开发者不把安全性放在很高的优先级,但我们认为,解决Unity出现内存损坏问题是关键特性之一。在运行代码时应该有一个特别模式,如果读取或写入到内存界限外或取消引用Null时,它能够提供我们明确的错误信息。
高性能 C
当我们使用 C# 语言时,仍然无法控制数据在内存中如何进行分布,但这是我们提升性能的关键点。
除此之外,标准库面向的是“堆上的对象”和“具有其它对象指针引用的对象”。
也就是意味着,当处理性能敏感代码时,我们可以放弃使用大部分标准库,例如:Linq、StringFormatter、List、Dictionary。禁止内存分配,即不使用类,只使用结构、映射、垃圾回收器和虚拟调用,并添加可使用的部分新容器,例如:NativeArray 和其他集合类型。
我们可以在越界访问时得到错误和错误信息,以及使用 C++ 代码时的调试器支持和编译速度。我们通常把该子集称为高性能 C# 或 HPC#。
它可以被总结为:
大部分的原始类型(float、int、uint、short、bool…),enums,structs 和其他类型的指针
集合:用
NavtiveArray<T>代替T[]所有的控制流语句(除了 try、finally、foreach、using)
对
throw new XXXException(...)给予基础支持
Burst
Unity 构建了名为 Burst 的代码生成器和编译器。
Burst 有时运行速度比 C++ 快,有时也会比 C++ 慢。后面的情况源于性能问题,Unity 已经开始着手解决。
当使用 C# 时,我们对整个流程有完整的控制,包括从源代码编译到机器代码生成,如果有我们不想要的部分,我们会找到并修复它。我们会逐渐把 C++ 语言的性能敏感代码移植为 HPC# 代码,这样会更容易得到想要的性能,更难出现 Bug,更容易进行处理。
如果 Asset Store 资源插件的开发者在资源中使用 HPC# 代码,资源插件在运行时代码会运行得更快。除此之外,高级用户也会通过使用 HPC# 编写出自定义高性能代码而受益。
ECS Track: Deep Dive into the Burst Compiler - Unite LA
Burst 对于 HPC# 更详细的支持可以在下面找到:
Burst User Guide
解决的多线程问题
C++ 和 C# 都无法为开发者编写线程安全代码提供太多帮助。即使在今天,拥有多个核心游戏消费级硬件发展至今已经过去了十年,但依旧很难有效处理使用多个核心的程序。
数据冲突,不确定性和死锁是使多线程代码难以编写的挑战。Unity 想要的特性是“确保代码调用的函数和所有内容不会在全局状态下读取或写入”。Unity 希望应该让编译器抛出错误来提醒,而不是属于“程序员应遵守的准则”,Burst 则会提供编译器错误。
Unity 鼓励 Unity 用户编写 “Jobified” 代码:将所有需要发生的数据转换划分为 Job。
每个 Job 都具有“功能性”,因为 Job 没有副作用。 Job 会明确指定使用的只读缓冲区和读写缓冲区,尝试访问其它数据会出现编译器错误。
Job 调度程序会确保在 Job 运行时,任何程序都不会写入只读缓冲区。我们会确保在 Job 运行时,任何程序都不会读取读写缓冲区。
如果调度的 Job 违反了这些规则,我们会得到运行时错误。这种错误不仅在竞态条件下得到,错误信息会说明,你正在尝试调度的 Job 想要读取缓冲区 A,但你之前已经调度了会写入缓冲区 A 的 Job ,所以如果想要执行该操作,需要把之前的 Job 指定为依赖。
深入栈
由于能够处理所有组件,我们可以使这些组件了解各自的存在。例如:向量化(Vectorization)无法进行的常见情况是,编译器无法确保二个指针不指向相同的内存,即混淆情况(Alias)。
而两个集合库中的 NativeArray 从不会混淆,我们可以在 Burst 中运用这个知识,使它不会由于害怕两个数组指针指向相同内存而放弃优化(Alias)。Alias 的问题在 Unity GDC 中也有一个演讲提到过:Unity at GDC - C# to Machine Code
Unity 还编写了 Unity.Mathemetics 数学库,提供了很多像 Shader 代码的数据结构。Burst 也能和这数学库很好的工作,未来 Burst 将能够为 math.sin() 等计算作出牺牲精度的优化。
对于 Burst 而言,math.sin() 不仅是要编译的 C# 方法,Burst 还能理解出 sin() 的三角函数属性,同时知道 x 值较小时会出现 sin(x) 等于 x 的情况,并了解它能替换为泰勒级数展开,以便牺牲特定精度。
跨平台和架构的浮点准确性是 Burst 未来的目标。
Entity Component System
Unity 一直以组件的概念为中心,例如:我们可以添加 Rigidbody 组件到游戏对象上,使对象能够向下掉落。我们也可以添加 Light 组件到游戏对象上,使它可以发射光线。我们添加 AudioEmitter 组件,可以使游戏对象发出声音。
我们实现组件系统的方法并没有很好地演变。我们过去使用面向对象的思维编写组件系统。组件和游戏对象都是“大量使用 C++ 代码”的对象,创建或销毁它们需要使用互斥锁修改“id 到对象指针”的全局列表。
通过使用面向数据的思维方式,我们可以更好地处理这种情况。我们可以保留用户眼中的优良特性,即只需添加组件就可以实现功能,而同时通过新组件系统取得出色的性能和并行效果。
这个全新的组件系统就是实体组件系统 ECS。简单来说,如今我们对游戏对象进行的操作可用于处理新系统的实体,组件仍称作组件。那么区别是什么?区别在于数据布局。
class Orbit : MonoBehaviour{ public Transform _objectToOrbitAround; void Update() { var currentPos = GetComponent<Transform>().position; var targetPos = _objectToOrbitAround.position; GetComponent<RigidBody>().velocity += SomehowSteerTowards(currentPos, targetPos) }} 这种模式会被反复使用:组件必须找到相同游戏对象上的一个或多个组件,然后给它读取或写入数值。
这种方法存在很多问题:
Update()方法被一个单独的 Orbit 组件调用,下次调用Update()的会是完全不同的组件,它很可能造成代码从缓存移出。Update()必须使用GetComponent()来找到 Rigidbody 组件。该组件也可以被缓存起来,但必须保证 Rigidbody 组件不被销毁。我们要处理的其它组件位于内存中完全不同的位置。
ECS 使用的数据布局会把这些情况看作一种非常常见的模式,并优化内存布局,使类似操作更加快捷。
传统内存布局
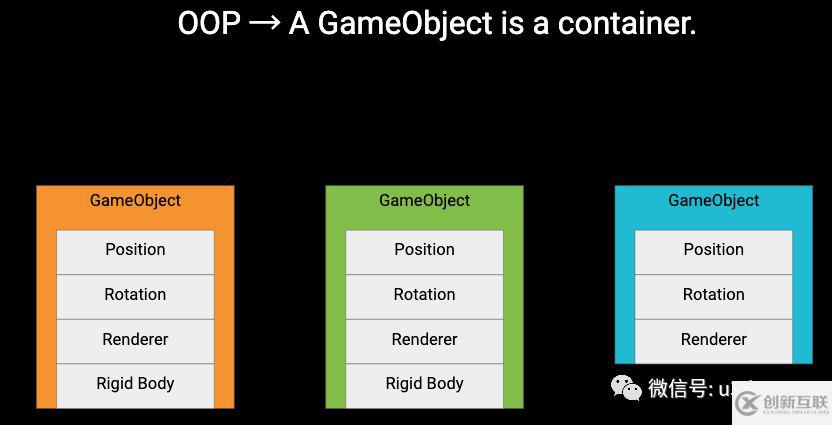

离散的数据导致搜索效率十分低下,还有 Cache Miss 的问题,这个问题可以参考:ECS的泛泛之谈
ECS 数据布局
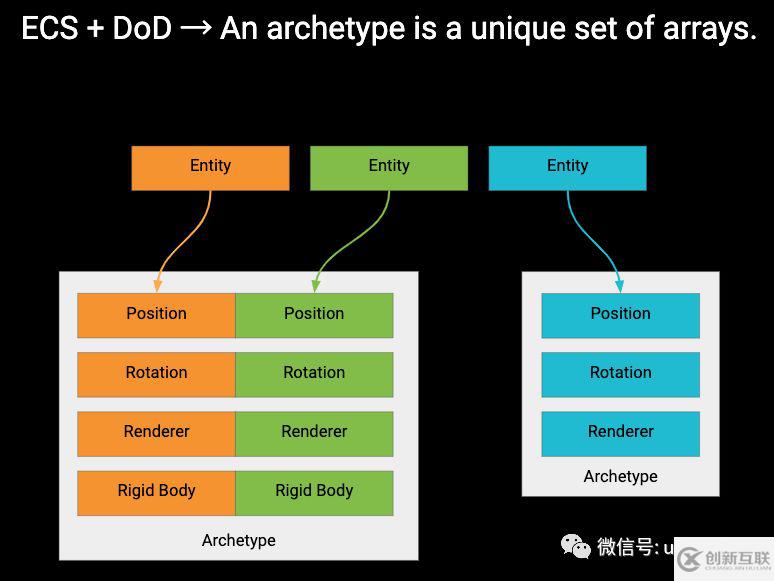
原型(Archetype)
ECS 会在内存中对带有相同组件(Component)集的所有实体(Entity)进行组合。ECS 把这类组件集称为原型(Archetype)。
下图的原型就是由 Position 组件、Velocity 组件、Rigidbody 组件和 Renderer 组件组成的。
如果一个实体只有三个组件(不同于前面提到的原型),那么那三个组件就组成了一个新的原型。
下面的图来自 Unite LA 的一次演讲的讲义, 很遗憾那次演讲没有录制下来。讲义可以在这里找到。
ECS 以 16k 大小的块(Chunk)来分配内存,每个块仅包含单个原型中所有实体的组件数据。
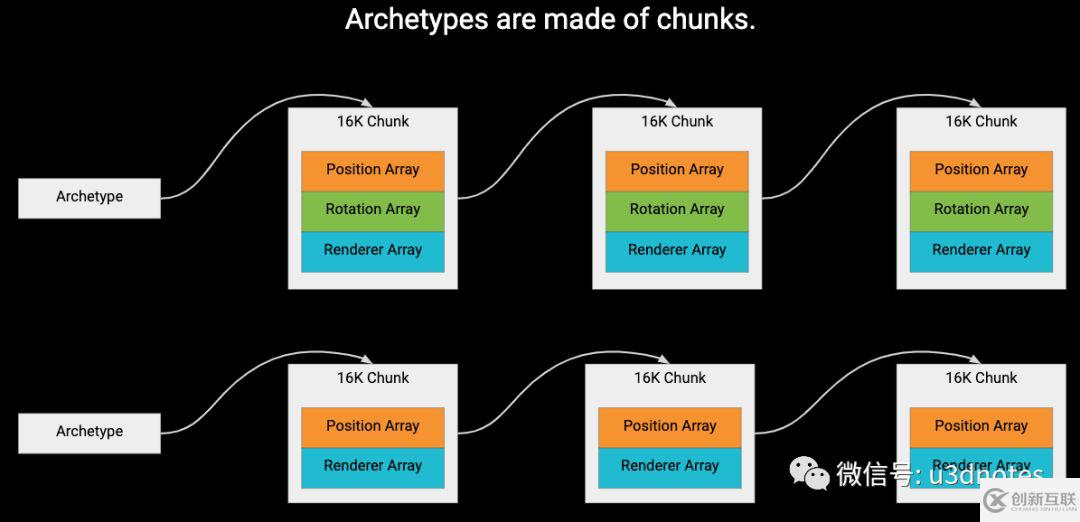
一个帖子中有人提供了更加形象的内存布局图,例如上半部分的原型由 Position 组件和 Rock 组件组成,其中整个原型占了一个块(Chunk),两个组件的数据分别存在两个数组中,里面还带着组件数据对应的实体的信息。
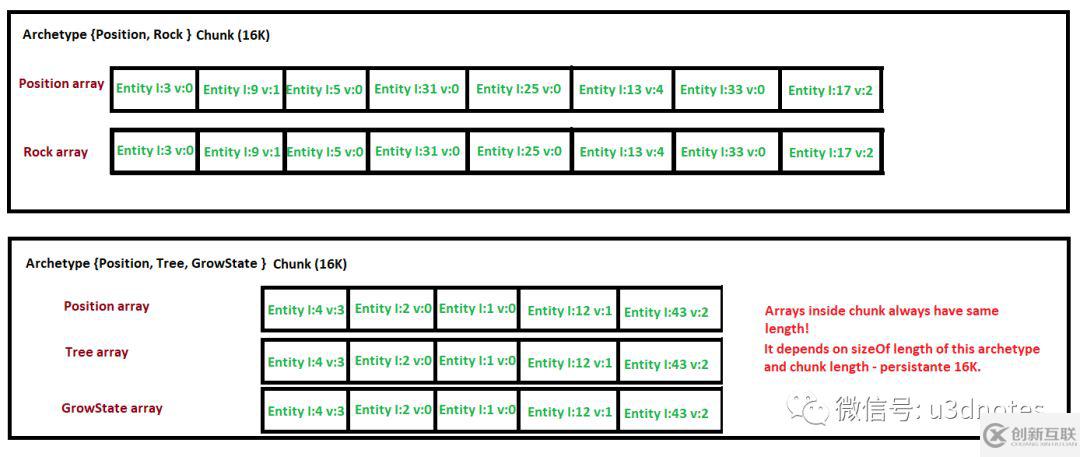
每个原型都有一个 Chunks 块列表,用来保存原型的实体。我们会循环所有块,并在每个块中,对紧凑的内存进行线性循环处理,以读取或写入组件数据。该线性循环会对每个实体运行相同的代码,同时为 Burst 创造向量化(Vectorization)处理的机会。
每个块会被安排好内存中的位置,以便于快速从内存得到想要的数据,详情可以参考下面的文章。
Unity2018 ECS框架Entities源码解析(二)组件与Chunk的内存布局 - 大鹏的专栏 - CSDN博客
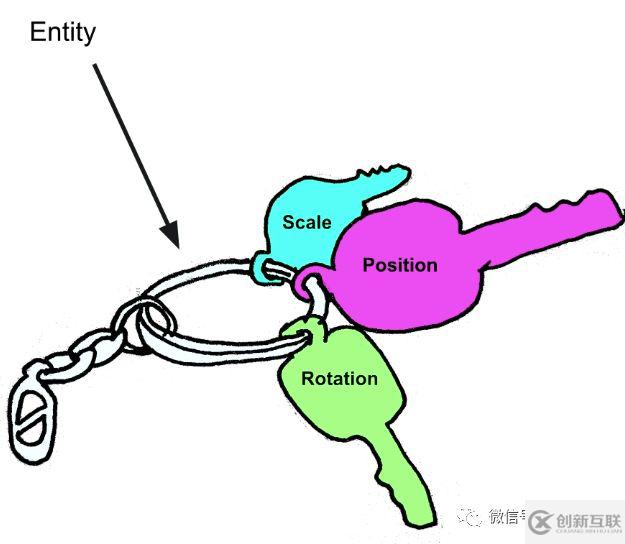
实体(Entity)
实体是什么?实体只是一个 32 位的整数 key (和一些额外的数据例如 index 和 version 实体版本,不过在这里不重要),所以除了实体的组件数据外,不必为实体保存或分配太多内存。实体可以实现游戏对象的所有功能,甚至更多功能,因为实体非常轻量。
实体的性能消耗很低,所以我们可以把实体用在不适合游戏对象的情况,例如:为粒子系统内的每个单独粒子使用一个实体。
实体本身不是对象,也不是一个容器,它的作用是把其组件的数据关联到一起。
系统(System)
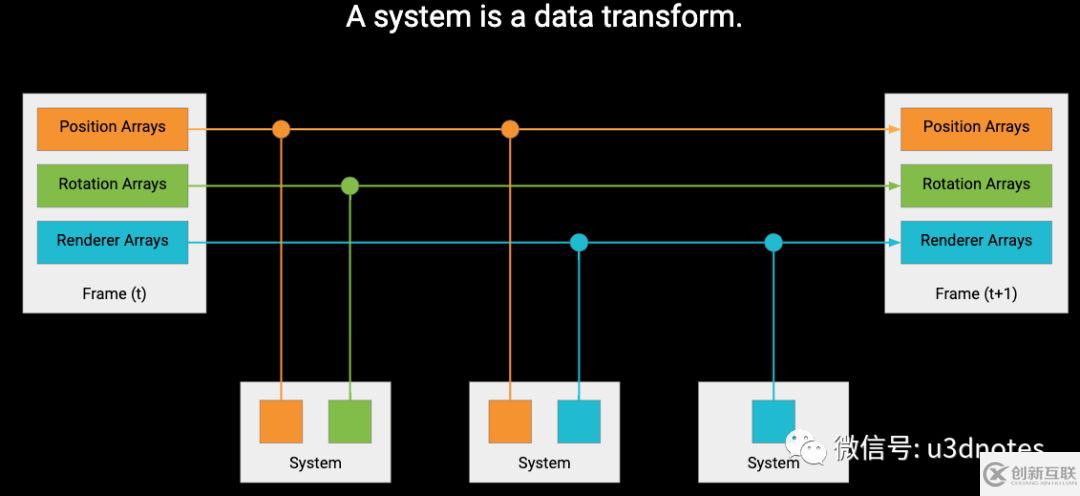
我们不必使用用户的 Update 方法搜索组件,然后在运行时对每个实例进行操作,使用 ECS 时我们只需静态地声明:我想对同时附带 Velocity 组件和 Rigidbody 组件的所有实体进行操作。为了找到所有实体,我们只需找到所有符合特定“组件搜索查询”的原型即可,而这个过程就是由系统(System)来完成的。
很多情况下,这个过程会分成多个 Job ,使处理ECS组件的代码达到几乎100%的核心利用率。ECS 会完成所有工作,我们只需要提供对每个实体运行的代码即可。我们也可以手动处理块迭代过程(IJobChunk)。
当我们从实体添加或移除组件时,ECS会切换原型。我们会把它从当前块移动到新原型的块,然后交换之前块的最后实体来“填补空缺”。
在 ECS 中,我们还要静态声明要对组件数据进行什么处理,是 ReadOnly 只读还是 ReadWrite 读写。通过确定仅对 Position 组件进行读取,ECS 可以更高效地调度 Job ,其它需要读取 Position 组件的 Job 不必进行等待。
这种数据布局也处理了 Unity 长期以来的困扰,即:加载时间和序列化的性能。为大型场景加载或流式处理 ECS 数据时,主要的操作是从硬盘加载和使用原始字节。
API 可用性和样板代码
对 ECS 的常见观点是:ECS 需要编写很多代码。因此,实现想要的功能需要处理很多样板代码。现在针对移除多数样板代码需求的大量改进即将推出,这些改进会使开发者更简单地表达自己的目的。
我们暂时没有实现太多这类改进,因为我们现在正专注于处理基础性能,但我们知道:太多样板代码对 ECS 游戏代码没有好处,我们不能让编写 ECS 代码比编写 MonoBehaviour 更麻烦。
Project Tiny 已经实现了部分改进,例如:基于 lambda 函数的迭代 API。
以上是“Unity中DOTS要实现的特点有哪些”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注创新互联行业资讯频道!
当前标题:Unity中DOTS要实现的特点有哪些
当前链接:https://www.cdcxhl.com/article28/jieecp.html
成都网站建设公司_创新互联,为您提供营销型网站建设、网站维护、小程序开发、网站收录、、软件开发
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
