Java基于JDK1.8的LinkedList源码怎么用
这篇文章给大家分享的是有关Java基于JDK 1.8的LinkedList源码怎么用的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
成都创新互联公司主营上城网站建设的网络公司,主营网站建设方案,重庆APP开发公司,上城h5小程序制作搭建,上城网站营销推广欢迎上城等地区企业咨询
前言
Collection里面重要的接口和类
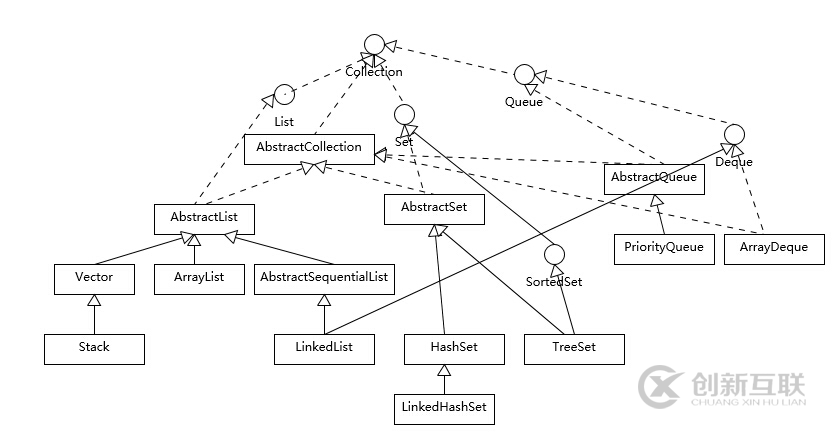
2,记得首次接触LinkedList还是在大学Java的时候,当时说起LinkedList的特性和应用场景:LinkedList基于双向链表适用于增删频繁且查询不频繁的场景,线程不安全的且适用于单线程(这点和ArrayList很像)。然后还记得一个很深刻的是可以用LinkedList来实现栈和队列,那让我们一起看一看源码到底是怎么来实现这些特点的
2.1 构造函数
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
}首先我们知道常见的构造是LinkedList()和LinkedList(Collection<? extends E> c)两种,然后再来看看我们继承的类和实现的接口
LinkedList 集成AbstractSequentialList抽象类,内部使用listIterator迭代器来实现重要的方法
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
可以看到,相对于ArrayList,LinkedList多实现了Deque接口而少实现了RandomAccess接口,且LinkedList继承的是AbstractSequentialList类,而ArrayList继承的是AbstractList类。那么我们现在有一个疑问,这些多实现或少实现的接口和类会对我们LinkedList的特点产生影响吗?这里我们先将这个疑问放在心里,我们先走正常的流程,先把LinkedList的源码看完(主要是要解释这些东西看Deque的源码,还要去看Collections里面的逻辑,我怕扯远了)
第5-7行:定义记录元素数量size,因为我们之前说过LinkedList是个双向链表,所以这里定义了链表链表头节点first和链表尾节点last
第60-70行:定义一个节点Node类,next表示此节点的后置节点,prev表示侧节点的前置节点,element表示元素值
第22行:检查当前的下标是否越界,因为是在构造函数中所以我们这边的index为0,且size也为0
第24-29行:将集合c转化为数组a,并获取集合的长度;定义节点pred、succ,pred用来记录前置节点,succ用来记录后置节点
第70-89行:node()方法是获取LinkedList中第index个元素,且根据index处于前半段还是后半段 进行一个折半,以提升查询效率
第30-36行:如果index==size,则将元素追加到集合的尾部,pred = last将前置节点pred指向之前结合的尾节点,如果index!=size表明是插入集合,通过node(index)获取当前要插入index位置的节点,且pred = succ.prev表示将前置节点指向于当前要插入节点位置的前置节点
第38-46行:链表批量增加,是靠for循环遍历原数组,依次执行插入节点操作,第40行以前置节点 和 元素值e,构建new一个新节点;第41行如果前置节点是空,说明是头结点,且将成员变量first指向当前节点,如果不是头节点,则将上一个节点的尾节点指向当前新建的节点;第45行将当前的节点为前置节点了,为下次添加节点做准备。这些走完基本上我们的新节点也都创建出来了,可能这块代码有点绕,大家多看看
第48-53行:循环结束后,判断如果后置节点是null, 说明此时是在队尾添加的,设置一下队列尾节点last,如果不是在队尾,则更新之前插入位置节点的前节点和当前要插入节点的尾节点
第55-56行:修改当前集合数量、修改modCount记录值
ok,虽然说是分析的构造函数的源码,但是把node(int index)、addAll(int index, Collection<? extends E> c)方法也都看了,所以来小结一下:链表批量增加,是靠for循环遍历原数组,依次执行插入节点操作;通过下标index来获取节点Node是采用的折半法来提升效率的
2.2 增加元素
常见的方法有以下三种
linkedList.add(E e) linkedList.add(int index, E element) linkedList.addAll(Collection<? extends E> c)
来看看具体的源码
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}第2、6-16行:创建一个newNode它的prev指向之前队尾节点last,并记录元素值e,之前的队尾节点last的next指向当前节点,size自增,modcount自增
第18-20,27-38行:首先去检查下标是否越界,然后判断如果加入的位置刚好位于队尾就和我们add(E element)的逻辑一样了,如果不是则需要通过 node(index)函数定位出当前位于index下标的node,再通过linkBefore()函数创建出newNode将其插入到原先index位置
第40-42行:就是我们在构造函数中看过的批量加入元素的方法
OK,添加元素也很简单,如果是在队尾进行添加的话只需要创建一个新Node将其前置节点指向之前的last,如果是在队中添加节点,首选拆散原先的index-1、index、index+1之间的联系,新建节点插入进去即可。
2.3 删除元素
常见方法有以下这几个方法
linkedList.remove(int index) linkedList.remove(Object o) linkedList.remove(Collection<?> c)
源码如下
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
boolean modified = false;
Iterator<?> it = iterator();
while (it.hasNext()) {
if (c.contains(it.next())) {
it.remove();
modified = true;
}
}
return modified;
}第1-4,6-30行:首先根据index通过方法值node(index)来确定出集合中的下标是index的node,咋们主要看unlink()方法,代码感觉很多,其实只是将当前要删除的节点node的头结点的尾节点指向node的尾节点、将node的尾结点的头节点指向node的头节点,可能有点绕(哈哈),看一下代码基本上就可以理解了,然后将下标为index的node置空,供GC回收
第32-49行:首先判断一下当前要删除的元素o是否为空,然后进行for循环定位出当前元素值等于o的节点node,然后再走的逻辑就是上面我们看到过的unlink()方法,也很简单,比remove(int index) 多了一步
第51-62行:这一块因为涉及到迭代器Iterator,而我们LinkedList使用的是ListItr,这个后面我们将迭代器的时候一起讲,不过大致的逻辑是都可以看懂的,和我们的ArrayList的迭代器方法的含义一样的,可以先那样理解
ok,小结一下, 按下标删,也是先根据index找到Node,然后去链表上unlink掉这个Node。 按元素删,会先去遍历链表寻找是否有该Node,考虑到允许null值,所以会遍历两遍,然后再去unlink它。
2.5 修改元素
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}只有这一种方法,首先检查下标是否越界,然后根据下标获取当前Node,然后修改节点中元素值item,超级简单
2.6 查找元素
public E get(int index) {
checkElementIndex(index);//判断是否越界 [0,size)
return node(index).item; //调用node()方法 取出 Node节点,
}
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}获取元素的源码也很简单,主要是通过node(index)方法获取节点,然后获取元素值,indexOf和lastIndexOf方法的区别在于一个是从头向尾开始遍历,一个是从尾向头开始遍历
2.7 迭代器
public Iterator<E> iterator() {
return listIterator();
}
public ListIterator<E> listIterator() {
return listIterator(0);
}
public ListIterator<E> listIterator(final int index) {
rangeCheckForAdd(index);
return new ListItr(index);
}
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public E previous() {
checkForComodification();
try {
int i = cursor - 1;
E previous = get(i);
lastRet = cursor = i;
return previous;
} catch (IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor-1;
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
AbstractList.this.set(lastRet, e);
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
AbstractList.this.add(i, e);
lastRet = -1;
cursor = i + 1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}可以看到,其实最后使用的迭代器是使用的ListIterator类,且集成自Itr,而Itr类就是我们昨天ArrayList内部使用的类,hasNext()方法和我们之前的一样,判断不等于size大小,然后next()获取元素主要也是E next = get(i);这行代码,这样就又走到我们之前的获取元素的源码当中,获得元素值。
OK,这样我们上面的基本方法都看完了,再来看看我们上面遗留的问题,首先来看Deque接口有什么作用,我们来一起看看
Deque 是 Double ended queue (双端队列) 的缩写,读音和 deck 一样,蛋壳。
Deque 继承自 Queue,直接实现了它的有 LinkedList, ArayDeque, ConcurrentLinkedDeque 等。
Deque 支持容量受限的双端队列,也支持大小不固定的。一般双端队列大小不确定。
Deque 接口定义了一些从头部和尾部访问元素的方法。比如分别在头部、尾部进行插入、删除、获取元素。
public interface Deque<E> extends Queue<E> {
void addFirst(E e);//插入头部,异常会报错
boolean offerFirst(E e);//插入头部,异常不报错
E getFirst();//获取头部,异常会报错
E peekFirst();//获取头部,异常不报错
E removeFirst();//移除头部,异常会报错
E pollFirst();//移除头部,异常不报错
void addLast(E e);//插入尾部,异常会报错
boolean offerLast(E e);//插入尾部,异常不报错
E getLast();//获取尾部,异常会报错
E peekLast();//获取尾部,异常不报错
E removeLast();//移除尾部,异常会报错
E pollLast();//移除尾部,异常不报错
}Deque也就是一个接口,上面是接口里面的方法,然后了解Deque就必须了解Queue
public interface Queue<E> extends Collection<E> {
//往队列插入元素,如果出现异常会抛出异常
boolean add(E e);
//往队列插入元素,如果出现异常则返回false
boolean offer(E e);
//移除队列元素,如果出现异常会抛出异常
E remove();
//移除队列元素,如果出现异常则返回null
E poll();
//获取队列头部元素,如果出现异常会抛出异常
E element();
//获取队列头部元素,如果出现异常则返回null
E peek();
}然后我们知道LinkedList实现了Deque接口,也就是说可以使用LinkedList实现栈和队列的功能,让写写看
package com.ysten.leakcanarytest;
import java.util.Collection;
import java.util.LinkedList;
/**
* desc : 实现栈
* time : 2018/10/31 0031 19:07
*
* @author : wangjitao
*/
public class Stack<T>
{
private LinkedList<T> stack;
//无参构造函数
public Stack()
{
stack=new LinkedList<T>();
}
//构造一个包含指定collection中所有元素的栈
public Stack(Collection<? extends T> c)
{
stack=new LinkedList<T>(c);
}
//入栈
public void push(T t)
{
stack.addFirst(t);
}
//出栈
public T pull()
{
return stack.remove();
}
//栈是否为空
boolean isEmpty()
{
return stack.isEmpty();
}
//打印栈元素
public void show()
{
for(Object o:stack)
System.out.println(o);
}
}测试功能
public static void main(String[] args){
Stack<String> stringStack = new Stack<>();
stringStack.push("1");
stringStack.push("2");
stringStack.push("3");
stringStack.push("4");
stringStack. show();
}打印结果如下:
4
3
2
1
队列的实现类似的,大家可以下来自己写一下,然后继续我们的问题,实现Deque接口和实现RandomAccess接口有什么区别,我们上面看了Deque接口,实现Deque接口可以拥有双向链表功能,那我们再来看看RandomAccess接口
public interface RandomAccess {
}发现什么都没有,原来RandomAccess接口是一个标志接口(Marker),然而实现这个接口有什么作用呢?
答案是只要List集合实现这个接口,就能支持快速随机访问,然而又有人问,快速随机访问是什么东西?有什么作用?
google是这样定义的:给可以提供随机访问的List实现去标识一下,这样使用这个List的程序在遍历这种类型的List的时候可以有更高效率。仅此而已。
这时候看一下我们Collections类中的binarySearch方法
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}可以看到这时候去判断了如果当前集合实现了RandomAccess接口就会走Collections.indexedBinarySearch方法,那么我们来看一下Collections.indexedBinarySearch()方法和Collections.iteratorBinarySearch()的区别是什么呢?
int indexedBinarySearch(List<? extends Comparable<? super T>> list, T key) {
int low = 0;
int high = list.size()-1;
while (low <= high) {
int mid = (low + high) >>> 1;
Comparable<? super T> midVal = list.get(mid);
int cmp = midVal.compareTo(key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found
}
int iteratorBinarySearch(List<? extends Comparable<? super T>> list, T key)
{
int low = 0;
int high = list.size()-1;
ListIterator<? extends Comparable<? super T>> i = list.listIterator();
while (low <= high) {
int mid = (low + high) >>> 1;
Comparable<? super T> midVal = get(i, mid);
int cmp = midVal.compareTo(key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found
}通过查看源代码,发现实现RandomAccess接口的List集合采用一般的for循环遍历,而未实现这接口则采用迭代器
,那现在让我们以LinkedList为例子看一下,通过for循环、迭代器、removeFirst和removeLast来遍历的效率(之前忘记写这一块了,顺便一块先写了对于LinkedList那种访问效率要高一些)
迭代器遍历
LinkedList linkedList = new LinkedList();
for(int i = 0; i < 100000; i++){
linkedList.add(i);
}
// 迭代器遍历
long start = System.currentTimeMillis();
Iterator iterator = linkedList.iterator();
while(iterator.hasNext()){
iterator.next();
}
long end = System.currentTimeMillis();
System.out.println("Iterator:"+ (end - start) +"ms");打印结果:Iterator:28ms
for循环get遍历
// 顺序遍历(随机遍历)
long start = System.currentTimeMillis();
for(int i = 0; i < linkedList.size(); i++){
linkedList.get(i);
}
long end = System.currentTimeMillis();
System.out.println("for :"+ (end - start) +"ms");打印结果 for :6295ms
使用增强for循环
long start = System.currentTimeMillis();
for(Object i : linkedList);
long end = System.currentTimeMillis();
System.out.println("增强for :"+ (end - start) +"ms");输出结果 增强for :6ms
removeFirst来遍历
long start = System.currentTimeMillis();
while(linkedList.size() != 0){
linkedList.removeFirst();
}
long end = System.currentTimeMillis();
System.out.println("removeFirst :"+ (end - start) +"ms");输出结果 removeFirst :3ms
综上结果可以看到,遍历LinkedList时,使用removeFirst()或removeLast()效率最高,而for循环get()效率最低,应避免使用这种方式进行。应当注意的是,使用removeFirst()或removeLast()遍历时,会删除原始数据,若只单纯的读取,应当选用迭代器方式或增强for循环方式。
ok,上述的都是只针对LinkedList而言测试的,然后我们接着上面的RandomAccess接口来讲,看看通过对比ArrayList的for循环和迭代器遍历看看访问效率
ArrayList的for循环
long start = System.currentTimeMillis();
for (int i = 0; i < arrayList.size(); i++) {
arrayList.get(i);
}
long end = System.currentTimeMillis();
System.out.println("for :"+ (end - start) +"ms");输出结果 for :3ms
ArrayList的迭代遍历
long start = System.currentTimeMillis();
Iterator iterable = arrayList.iterator() ;
while (iterable.hasNext()){
iterable.next();
}
long end = System.currentTimeMillis();
System.out.println("for :"+ (end - start) +"ms");输出结果 for :6ms
所以让我们来综上对比一下
ArrayList
普通for循环:3ms
迭代器:6ms
LinkedList
普通for循环:6295ms
迭代器:28ms
从上面数据可以看出,ArrayList用for循环遍历比iterator迭代器遍历快,LinkedList用iterator迭代器遍历比for循环遍历快,所以对于不同的List实现类,遍历的方式有所不用,RandomAccess接口这个空架子的存在,是为了能够更好地判断集合是否ArrayList或者LinkedList,从而能够更好选择更优的遍历方式,提高性能!
(在这里突然想起在去年跳槽的时候,有家公司的面试官问我,list集合的哪一种遍历方式要快一些,然后我说我没有每个去试过,结果那位大佬说的是for循环遍历最快,还叫我下去试试,现在想想,只有在集合是ArrayList的时候for循环才最快,对于LinkedList来说for循环反而是最慢的,那位大佬,你欠我一声对不起(手动斜眼微笑))
3,上面把我们该看的点都看了,那么我们再来总结总结:
LinkedList 是双向列表,链表批量增加,是靠for循环遍历原数组,依次执行插入节点操作。
ArrayList基于数组, LinkedList基于双向链表,对于随机访问, ArrayList比较占优势,但LinkedList插入、删除元素比较快,因为只要调整指针的指向。针对特定位置需要遍历时,所以LinkedList在随机访问元素的话比较慢。
LinkedList没有实现自己的 Iterator,使用的是 ListIterator。
LinkedList需要更多的内存,因为 ArrayList的每个索引的位置是实际的数据,而 LinkedList中的每个节点中存储的是实际的数据和前后节点的位置。
LinkedList也是非线程安全的,只有在单线程下才可以使用。为了防止非同步访问,Collections类里面提供了synchronizedList()方法。
感谢各位的阅读!关于“Java基于JDK 1.8的LinkedList源码怎么用”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
本文名称:Java基于JDK1.8的LinkedList源码怎么用
URL标题:https://www.cdcxhl.com/article32/gooesc.html
成都网站建设公司_创新互联,为您提供标签优化、虚拟主机、做网站、App开发、服务器托管、电子商务
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 品牌网站设计的流程有哪些 2023-02-13
- 好的品牌网站设计两大要点必知 2022-06-10
- 品牌网站设计定制解决方案 2021-08-16
- 金融网站建设竞争力,品牌网站设计新趋势 2014-06-08
- 品牌网站设计有哪些问题要注意? 2020-12-26
- 4个消费电子产品的品牌网站设计 2021-09-28
- 品牌网站设计怎样做更加高端? 2016-10-05
- 品牌网站设计怎样做更加高端? 2022-11-15
- 品牌网站设计四大核心制作要素 2022-08-15
- 品牌网站设计对企业来说有什么意义? 2016-02-09
- 优秀品牌网站设计欣赏 2014-06-25
- 品牌网站设计制作-是企业对外的名片和形象 2020-11-28