「图像分类」关于图像分类中类别不平衡那些事
作者&编辑 | 郭冰洋
网站的建设创新互联建站专注网站定制,经验丰富,不做模板,主营网站定制开发.小程序定制开发,H5页面制作!给你焕然一新的设计体验!已为成都围栏护栏等企业提供专业服务。
1 简介
小伙伴们在利用公共数据集动手搭建图像分类模型时,有没有注意到这样一个问题呢——每个数据集不同类别的样本数目几乎都是一样的。这是因为不同类别的样例数目差异较小,对分类器的性能影响不大,可以在避免其他因素的影响下,充分反映分类模型的性能。反之,如果类别间的样例数目相差过大,会对学习过程造成一定的影响,从而导致分类模型的性能变差。这就是本篇文章将要讨论的类别不平衡问题(Class Imbalance)。
类别不平衡是指分类任务中不同类别的训练样本数目相差较大的情况,通常是由于样本较难采集或样本示例较少而引起的,经常出现在疾病类别诊断、欺诈类型判别等任务中。
尽管在传统机器学习领域内,有关类别不平衡的问题已经得到了详尽的研究,但在深度学习领域内,其相关探索随着深度学习的发展,经历了一个先抑后扬的过程。
在反向传播算法诞生初期,有关深度学习的研究尚未成熟,但仍有相关科研人员研究过类别样例的数目对梯度传播的影响,并得出样例数目较多的类别在反向传播时对权重占主导地位。这一现象会使网络训练初期,快速的降低数目较多类别的错误率,但随着训练的迭代次数增加,数目较少类的错误率会随之上升[1]。
随后的十余年里,由于深度学习受到计算资源的限制、数据集采集的难度较大等影响,相关研究并没有得到进一步的探索,直到近年来才大放异,而深度学习领域内的类别不平衡问题,也得到了更加深入的研究。
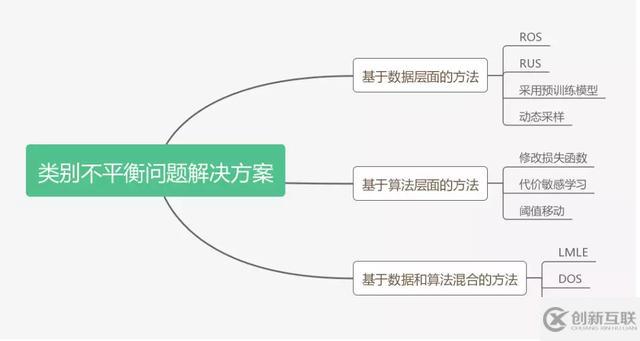
本篇文章将对目前涉及到的相关解决方案进行汇总,共分为数据层面、算法层面、数据和算法混合层面三个方面,仅列举具有代表性的方案阐述,以供读者参考。
2 方法汇总
1、基于数据层面的方法
基于数据层面的方法主要对参与训练的数据集进行相应的处理,以减少类别不平衡带来的影响。
Hensman等[2]提出了 提升样本(over sampling)的方法,即对于类别数目较少的类别,从中随机选择一些图片进行复制并添加至该类别包含的图像内,直到这个类别的图片数目和最大数目类的个数相等为止。通过实验发现,这一方法对最终的分类结果有了非常大的提升。
Lee等[3]提出了一种 两阶段(two-phase)训练法。首先根据数据集分布情况设置一个阈值N,通常为最少类别所包含样例个数。随后对样例个数大于阈值的类别进行随机抽取,直到达到阈值。此时根据阈值抽取的数据集作为第一阶段的训练样本进行训练,并保存模型参数。最后采用第一阶段的模型作为预训练数据,再在整个数据集上进行训练,对最终的分类结果有了一定的提升.
Pouyanfar等[4]则提出了一种 动态采样(dynamic sampling)的方法。该方法借鉴了提升样本的思想,将根据训练结果对数据集进行动态调整,对结果较好的类别进行随机删除样本操作,对结果较差的类别进行随机复制操作,以保证分类模型每次学习都能学到相关的信息。
2、基于算法层面的方法
基于算法层面的方法主要对现有的深度学习算法进行改进,通过修改损失函数或学习方式的方法来消除类别不平衡带来的影响。
Wang等[5]提出 mean squared false error (MSFE) loss。这一新的损失函数是在mean false error (MFE) loss的基础上进行改进,具体公式如下图所示:

MSFE loss能够很好地平衡正反例之间的关系,从而实现更好的优化结果。
Buda等[6]提出 输出阈值(output thresholding)的方法,通过调整网络结果的输出阈值来改善类别不平衡的问题。模型设计者根据数据集的构成和输出的概率值,人工设计一个合理的阈值,以降低样本数目较少的类别的输出要求,使得其预测结果更加合理。
3、基于数据和算法的混合方法
上述两类层面的方法均能取得较好的改善结果,如果将两种思想加以结合,能否有进一步的提升呢?
Huang等[7]提出 Large Margin Local Embedding (LMLE)的方法,采用五倍抽样法(quintuplet sampling )和tripleheader hinge loss函数,可以更好地提取样本特征,随后将特征送入改进的K-NN分类模型,能够实现更好的聚类效果。除此之外,Dong等[8]则融合了难例挖掘和类别修正损失函数的思想,同样是在数据和损失函数进行改进。
由于篇幅和时间有限,本文只列取了每个类别的典型解决方案。同时也搜集了关于解决类别不平衡问题的相关综述文献,截图如下:
具体名称可以借鉴参考文献[9]。
3 参考文献
[1] Anand R, Mehrotra KG, Mohan CK, Ranka S. An improved algorithm for neural network classification of imbalanced training sets. IEEE Trans Neural Netw. 1993;4(6):962–9.
[2] Hensman P, Masko D. The impact of imbalanced training data for convolutional neural networks. 2015.
[3] Lee H, Park M, Kim J. Plankton classification on imbalanced large scale database via convolutional neural networks with transfer learning. In: 2016 IEEE international conference on image processing (ICIP). 2016. p. 3713–7.
[4] Pouyanfar S, Tao Y, Mohan A, Tian H, Kaseb AS, Gauen K, Dailey R, Aghajanzadeh S, Lu Y, Chen S, Shyu M. Dynamic sampling in convolutional neural networks for imbalanced data classification. In: 2018 IEEE conference on multimedia information processing and retrieval (MIPR). 2018. p. 112–7.
[5] Wang S, Liu W, Wu J, Cao L, Meng Q, Kennedy PJ. Training deep neural networks on imbalanced data sets. In: 2016 international joint conference on neural networks (IJCNN). 2016. p. 4368–74.
[6] Buda M, Maki A, Mazurowski MA. A systematic study of the class imbalance problem in convolutional neural
networks. Neural Netw. 2018;106:249–59.
[7] Huang C, Li Y, Loy CC, Tang X. Learning deep representation for imbalanced classification. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR). 2016. p. 5375–84.
[8] Dong Q, Gong S, Zhu X. Imbalanced deep learning by minority class incremental rectification. In: IEEE transactions on pattern analysis and machine intelligence. 2018. p. 1–1
[9] Justin M. Johnson and Taghi M. Khoshgoftaar.Survey on deep learning with class imbalance.Johnson and Khoshgoftaar J Big Data.(2019) 6:27
总结
以上就是关于类别不平衡问题的相关解决方案,详细内容可以阅读参考文献综述9,相信通过更加详细的文章阅读,你会收获更多的经验!
https://www.toutiao.com/a6727841366342107655/
网站栏目:「图像分类」关于图像分类中类别不平衡那些事
网页URL:https://www.cdcxhl.com/article30/gooeso.html
成都网站建设公司_创新互联,为您提供App设计、网站建设、外贸网站建设、品牌网站设计、网站改版、全网营销推广
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 『微信公众号运营技巧』这些技巧你得知道 2022-06-18
- 微信公众号粉丝的粘性怎么提高? 2014-05-26
- 微信公众号文章标题制作有什么技巧 2022-11-07
- 微信公众号商城如何运营? 2022-05-20
- 微信公众号文章标题制作有什么技巧-大连微信开发 2022-07-12
- 微信公众号平台开发运营,刚好你需要,刚好我专业,考虑考虑! 2022-08-17
- 企业微信公众号运营的10个准则是什么? 2014-01-23
- 微信公众号运营怎么进行布局? 2015-01-10
- 淘宝卖家怎样运营微信公众号? 2014-07-27
- 微信公众号推送内容应该避免那些错误? 2014-05-18
- 微信公众号文章修改错别字需要注意什么? 2014-05-20
- 微信公众号叕改版了,这里有最全改版信息汇总,还有微信官方改版解答! 2022-05-21