怎么理解Node.js中的Buffer模块
这篇文章主要讲解了“怎么理解Node.js中的Buffer模块”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“怎么理解Node.js中的Buffer模块”吧!
10年积累的网站建设、成都网站制作经验,可以快速应对客户对网站的新想法和需求。提供各种问题对应的解决方案。让选择我们的客户得到更好、更有力的网络服务。我虽然不认识你,你也不认识我。但先建设网站后付款的网站建设流程,更有杨浦免费网站建设让你可以放心的选择与我们合作。

理解Buffer
JavaScript对于字符串的操作十分友好
Buffer是一个像Array的对象,主要用于操作字节。
Buffer结构
Buffer是一个典型的JavaScript和C++结合的模块,将性能相关部分用C++实现,将非性能相关部分用JavaScript实现。
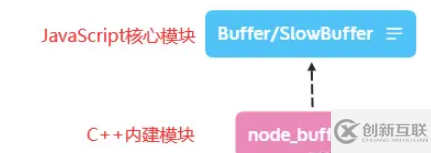
Buffer所占用的内存不是通过V8分配,属于堆外内存。 由于V8垃圾回收性能影响,将常用的操作对象用更高效和专有的内存分配回收政策来管理是个不错的思路。
Buffer在Node进程启动时就已经价值,并且放在全局对象(global)上。所以使用buffer无需require引入
Buffer对象
Buffer对象的元素未16进制的两位数,即0-255的数值
let buf01 = Buffer.alloc(8); console.log(buf01); // <Buffer 00 00 00 00 00 00 00 00>
可以使用fill填充buf的值(默认为utf-8编码),如果填充的值超过buffer,将不会被写入。
如果buffer长度大于内容,则会反复填充
如果想要清空之前填充的内容,可以直接fill()
buf01.fill('12345678910')
console.log(buf01); // <Buffer 31 32 33 34 35 36 37 38>
console.log(buf01.toString()); // 12345678如果填入的内容是中文,在utf-8的影响下,中文字会占用3个元素,字母和半角标点符号占用1个元素。
let buf02 = Buffer.alloc(18, '开始我们的新路程', 'utf-8'); console.log(buf02.toString()); // 开始我们的新
Buffer受Array类型影响很大,可以访问length属性得到长度,也可以通过下标访问元素,也可以通过indexOf查看元素位置。
console.log(buf02); // <Buffer e5 bc 80 e5 a7 8b e6 88 91 e4 bb ac e7 9a 84 e6 96 b0>
console.log(buf02.length) // 18字节
console.log(buf02[6]) // 230: e6 转换后就是 230
console.log(buf02.indexOf('我')) // 6:在第7个字节位置
console.log(buf02.slice(6, 9).toString()) // 我: 取得<Buffer e6 88 91>,转换后就是'我'如果给字节赋值不是0255之间的整数,或者赋值时小数时,赋值小于0,将该值逐次加256.直到得到0255之间的整数。如果大于255,就逐次减去255。 如果是小数,舍去小数部分(不做四舍五入)
Buffer内存分配
Buffer对象的内存分配不是在V8的堆内存中,而是在Node的C++层面实现内存的申请。 因为处理大量的字节数据不能采用需要一点内存就向操作系统申请一点内存的方式。为此Node在内存上使用的是在C++层面申请内存,在JavaScript中分配内存的方式
Node采用了slab分配机制,slab是以中动态内存管理机制,目前在一些*nix操作系统用中有广泛的应用,比如Linux
slab就是一块申请好的固定大小的内存区域,slab具有以下三种状态:
full:完全分配状态
partial:部分分配状态
empty:没有被分配状态
Node以8KB为界限来区分Buffer是大对象还是小对象
console.log(Buffer.poolSize); // 8192
这个8KB的值就额是每个slab的大小值,在JavaScript层面,以它作为单位单元进行内存的分配
分配小buffer对象
如果指定Buffer大小小于8KB,Node会按照小对象方式进行分配
构造一个新的slab单元,目前slab处于empty空状态
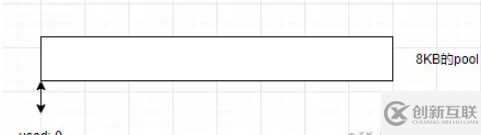
构造小
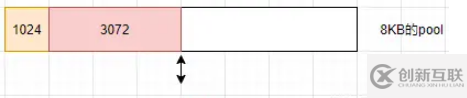
buffer对象1024KB,当前的slab会被占用1024KB,并且记录下是从这个slab的哪个位置开始使用的

这时再创建一个
buffer对象,大小为3072KB。 构造过程会判断当前slab剩余空间是否足够,如果足够,使用剩余空间,并更新slab的分配状态。 3072KB空间被使用后,目前此slab剩余空间4096KB。
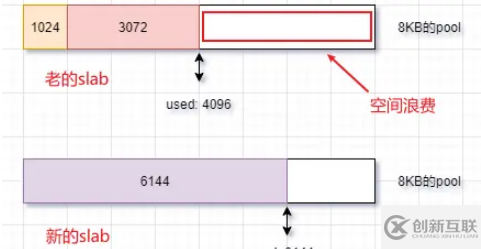
如果此时创建一个6144KB大小的
buffer,当前slab空间不足,会构造新的slab(这会造成原slab剩余空间浪费)
比如下面的例子中:
Buffer.alloc(1) Buffer.alloc(8192)
第一个slab中只会存在1字节的buffer对象,而后一个buffer对象会构建一个新的slab存放
由于一个slab可能分配给多个Buffer对象使用,只有这些小buffer对象在作用域释放并都可以回收时,slab的空间才会被回收。 尽管只创建1字节的buffer对象,但是如果不释放,实际是8KB的内存都没有释放
小结:
真正的内存是在Node的C++层面提供,JavaScript层面只是使用。当进行小而频繁的Buffer操作时,采用slab的机制进行预先申请和时候分配,使得JavaScript到操作系统之间不必有过多的内存申请方面的系统调用。 对于大块的buffer,直接使用C++层面提供的内存即可,无需细腻的分配操作。
Buffer的拼接
buffer在使用场景中,通常是以一段段的方式进行传输。
const fs = require('fs');
let rs = fs.createReadStream('./静夜思.txt', { flags:'r'});
let str = ''
rs.on('data', (chunk)=>{
str += chunk;
})
rs.on('end', ()=>{
console.log(str);
})以上是读取流的范例,data时间中获取到的chunk对象就是buffer对象。
但是当输入流中有宽字节编码(一个字占多个字节)时,问题就会暴露。在str += chunk中隐藏了toString()操作。等价于str = str.toString() + chunk.toString()。
下面将可读流的每次读取buffer长度限制为11.
fs.createReadStream('./静夜思.txt', { flags:'r', highWaterMark: 11});输出得到:

上面出现了乱码,上面限制了buffer长度为11,对于任意长度的buffer而言,宽字节字符串都有可能存在被截断的情况,只不过buffer越长出现概率越低。
encoding
但是如果设置了encoding为utf-8,就不会出现此问题了。
fs.createReadStream('./静夜思.txt', { flags:'r', highWaterMark: 11, encoding:'utf-8'});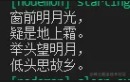
原因:虽然无论怎么设置编码,流的触发次数都是一样,但是在调用setEncoding时,可读流对象在内部设置了一个decoder对象。每次data事件都会通过decoder对象进行buffer到字符串的解码,然后传递给调用者。
string_decoder 模块提供了用于将 Buffer 对象解码为字符串(以保留编码的多字节 UTF-8 和 UTF-16 字符的方式)的 API
const { StringDecoder } = require('string_decoder');
let s1 = Buffer.from([0xe7, 0xaa, 0x97, 0xe5, 0x89, 0x8d, 0xe6, 0x98, 0x8e, 0xe6, 0x9c])
let s2 = Buffer.from([0x88, 0xe5, 0x85, 0x89, 0xef, 0xbc, 0x8c, 0x0d, 0x0a, 0xe7, 0x96])
console.log(s1.toString());
console.log(s2.toString());
console.log('------------------');
const decoder = new StringDecoder('utf8');
console.log(decoder.write(s1));
console.log(decoder.write(s2));
StringDecoder在得到编码之后,知道了宽字节字符串在utf-8编码下是以3个字节的方式存储的,所以第一次decoder.write只会输出前9个字节转码的字符,后两个字节会被保留在StringDecoder内部。
Buffer与性能
buffer在文件I/O和网络I/O中运用广泛,尤其在网络传输中,性能举足轻重。在应用中,通常会操作字符串,但是一旦在网络中传输,都需要转换成buffer,以进行二进制数据传输。 在web应用中,字符串转换到buffer是时时刻刻发生的,提高字符串到buffer的转换效率,可以很大程度地提高网络吞吐率。
如果通过纯字符串的方式向客户端发送,性能会比发送buffer对象更差,因为buffer对象无须在每次响应时进行转换。通过预先转换静态内容为buffer对象,可以有效地减少CPU重复使用,节省服务器资源。
可以选择将页面中动态和静态内容分离,静态内容部分预先转换为buffer的方式,使得性能得到提升。
在文件的读取时,highWaterMark设置对性能影响至关重要。在理想状态下,每次读取的长度就是用户指定的highWaterMark。
highWaterMark大小对性能有两个影响的点:
对buffer内存的分配和使用有一定影响
设置过小,可能导致系统调用次数过多
感谢各位的阅读,以上就是“怎么理解Node.js中的Buffer模块”的内容了,经过本文的学习后,相信大家对怎么理解Node.js中的Buffer模块这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是创新互联,小编将为大家推送更多相关知识点的文章,欢迎关注!
新闻名称:怎么理解Node.js中的Buffer模块
标题链接:https://www.cdcxhl.com/article26/iehjcg.html
成都网站建设公司_创新互联,为您提供Google、网站设计、面包屑导航、商城网站、虚拟主机、动态网站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- ssl证书验证过程是怎样的? 2022-10-02
- “如果可以,我愿意用隐私换一张回家的车票……” 2021-03-04
- 专业的网站建设意见以及方法分享给大家 2023-06-07
- 网站常见的标志设计错误如何避免 2019-06-07
- 微信小程序一年的变化 2023-07-14
- SEO优化图片如何处理? 2013-06-24
- 做好网站优化的内容需要从这几方面进行 2020-09-09
- 外贸人如何接听海外客户的英文电话 2022-06-13
- seo的技术有多大的作用呢? 2023-04-19
- 高端网站建设—企业网站建设的注意事项(高端网站建设公司排名) 2023-12-30
- 成都网站建设中提升网站用户体验的技巧有哪些 2023-05-17
- 网站如何达到预期目标 2017-03-03