PHP+HTML+JavaScript+Css如何实现爬虫开发-创新互联
这篇文章主要介绍了PHP+HTML+JavaScript+Css如何实现爬虫开发,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。

思路。
1、去不同网站。那么我们需要一个url输入框。
2、找特定关键字的文章。那么我们需要一个文章标题输入框。
3、获取文章链接。那么我们需要一个搜索结果的显示容器。
<div class="jumbotron" id="mainJumbotron"> <div class="panel panel-default"> <div class="panel-heading">文章URL抓取</div> <div class="panel-body"> <div class="form-group"> <label for="article_title">文章标题</label> <input type="text" class="form-control" id="article_title" placeholder="文章标题"> </div> <div class="form-group"> <label for="website_url">网站URL</label> <input type="text" class="form-control" id="website_url" placeholder="网站URL"> </div> <button type="submit" class="btn btn-default">抓取</button> </div> </div> <div class="panel panel-default"> <div class="panel-heading">文章URL</div> <div class="panel-body"> <h4></h4> </div> </div> </div>
直接上代码,然后加上自己的一些样式调整,界面就完成啦:
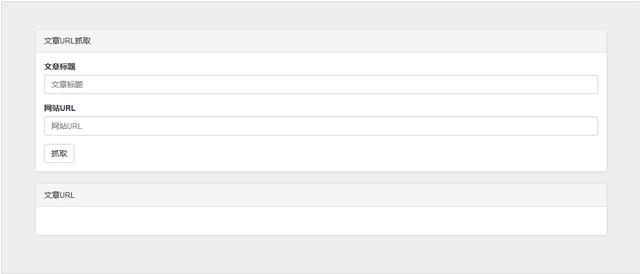
那么接下来就是功能的实现了,我用PHP来写,首先第一步就是获取网站的html代码,获取html代码的方式也有很多,我就不一一介绍了,这里用了curl来获取,传入网站url就能得到html代码啦:
private function get_html($url){
$ch = curl_init();
$timeout = 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
return $html;
}虽然得到了html代码,但是很快你会遇到一个问题,那就是编码问题,这可能让你下一步的匹配无功而返,我们这里统一把得到的html内容转为utf8编码:
$coding = mb_detect_encoding($html); if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8")) $html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
得到网站的html,要获取文章的url,那么下一步就是要匹配该网页下的所有a标签,需要用到正则表达式,经过多次测试,最终得到一个比较靠谱的正则表达式,不管a标签下结构多复杂,只要是a标签的都不放过:(最关键的一步)
$pattern = '|<a[^>]*>(.*)</a>|isU'; preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,它大概是这样的一个多维素组:
array(2) {
[0]=>
array(*) {
[0]=>
string(*) "完整的a标签"
.
.
.
}
[1]=>
array(*) {
[0]=>
string(*) "与上面下标相对应的a标签中的内容"
}
}只要能得到这个数据,其他就完全可以操作啦,你可以遍历这个素组,找到你想要a标签,然后获取a标签相应的属性,想怎么操作就怎么操作啦,下面推荐一个类,让你更方便操作a标签:
$dom = new DOMDocument();
@$dom->loadHTML($a);//$a是上面得到的一些a标签
$url = new DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //这里获取a标签的href属性
}当然,这只是一种方式,你也可以通过正则表达式匹配你想要的信息,把数据玩出新花样。
得到并匹配得出你想要的结果,下一步当然就是传回前端将他们显示出来啦,把接口写好,然后前端用js获取数据,用jquery动态添加内容显示出来:
var website_url = '你的接口地址';
$.getJSON(website_url,function(data){
if(data){
if(data.text == ''){
$('#article_url').html('<div><p>暂无该文章链接</p></div>');
return;
}
var string = '';
var list = data.text;
for (var j in list) {
var content = list[j].url_content;
for (var i in content) {
if (content[i].title != '') {
string += '<div class="item">' +
'<em>[<a href="http://' + list[j].website.web_url + '" target="_blank">' + list[j].website.web_name + '</a>]</em>' +
'<a href=" ' + content[i].url + '" target="_blank" class="web_url">' + content[i].title + '</a>' +
'</div>';
}
}
}
$('#article_url').html(string);
});上最终效果图:
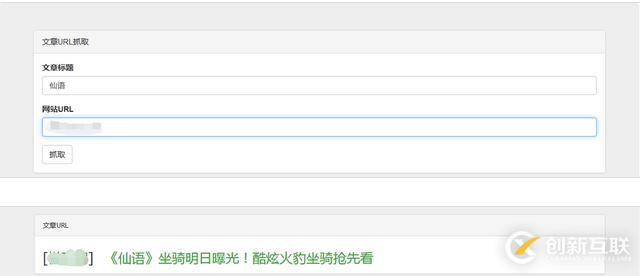
感谢你能够认真阅读完这篇文章,希望小编分享的“PHP+HTML+JavaScript+Css如何实现爬虫开发”这篇文章对大家有帮助,同时也希望大家多多支持创新互联网站建设公司,,关注创新互联行业资讯频道,更多相关知识等着你来学习!
文章名称:PHP+HTML+JavaScript+Css如何实现爬虫开发-创新互联
链接URL:https://www.cdcxhl.com/article20/jgdjo.html
成都网站建设公司_创新互联,为您提供网站制作、网站设计公司、网站设计、企业网站制作、网页设计公司、云服务器
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 你知道全网营销推广具体指的哪些方面吗 2021-09-05
- 为什么要做全网营销?全网营销有哪些好处? 2015-05-14
- 网络营销中全网营销对企业有什么帮助? 2014-08-02
- 新闻营销对于全网营销推广重要吗? 2015-10-20
- 全网营销推广对企业非常重要 2022-12-30
- 常见的全网营销方式都有什么? 2015-08-30
- 不懂全网营销推广怎么办?这里有答案 2022-07-08
- 全网营销的重点是什么? 2015-06-23
- 全网营销推广方案制作流程 2016-11-10
- 中小企业进行全网营销推广方法有哪些? 2015-05-09
- 企业制定全网营销推广方案有哪些方法 2022-07-17
- 网络营销平台有哪些,全网营销推广的方式 2023-04-27