Python怎么爬取微博树洞
本篇文章为大家展示了Python 怎么爬取微博树洞,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
网站建设哪家好,找创新互联!专注于网页设计、网站建设、微信开发、微信小程序定制开发、集团企业网站建设等服务项目。为回馈新老客户创新互联还提供了乐山免费建站欢迎大家使用!
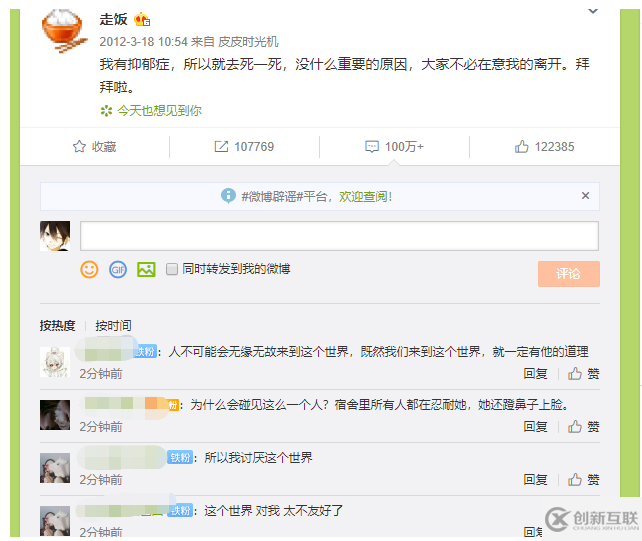
尤其是对于我这种需求量比较大的项目。不过好在最后发现了突破口:“微博树洞”。“微博树洞”是指宣告了自杀行为的过世的人的微博,其留言区成为成千上万的抑郁症或是绝望的人的归属,在其下方发布许多负能量甚至是寻死的宣言。
比如走饭的微博:
1.找到微博评论数据接口
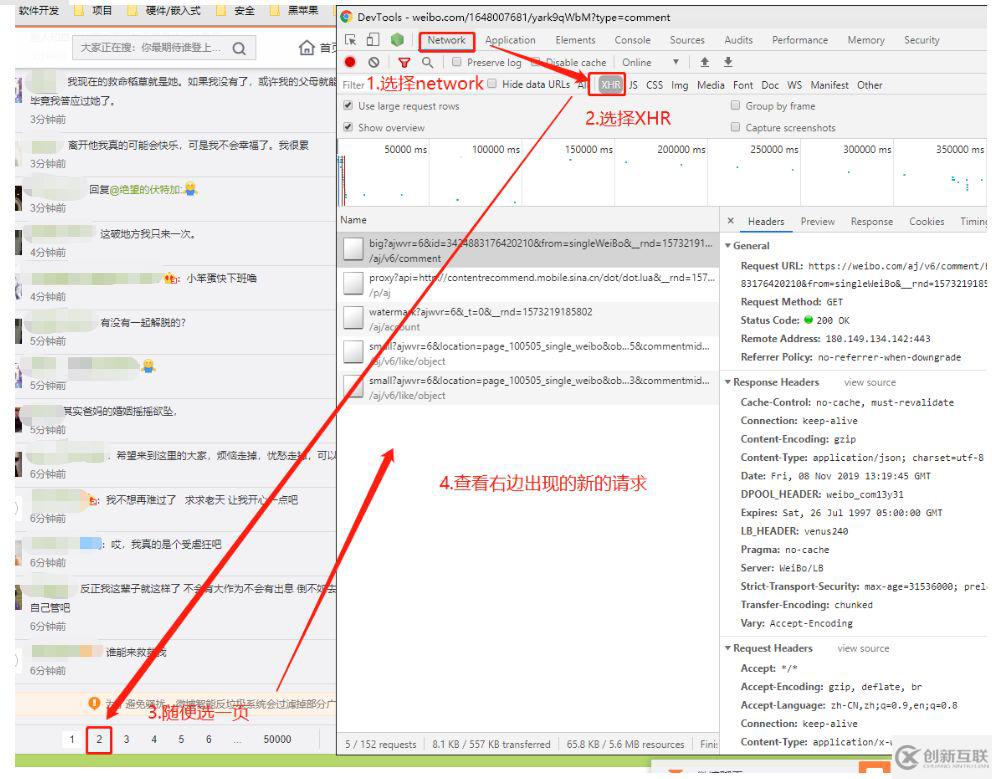
微博评论的数据接口有两种,一种是手机版、一种是PC版。手机版能爬到的数据仅仅只有十五页,因此我们从PC版入手,先来看看PC版的接口怎么找,长啥样儿。
首先,在当前微博的页面右键—检查(F12)打开开发者工具,然后按照下图的步骤进行操作(选择NetWork—选择XHR—随便点击另一个评论页—查看右侧新增的请求):
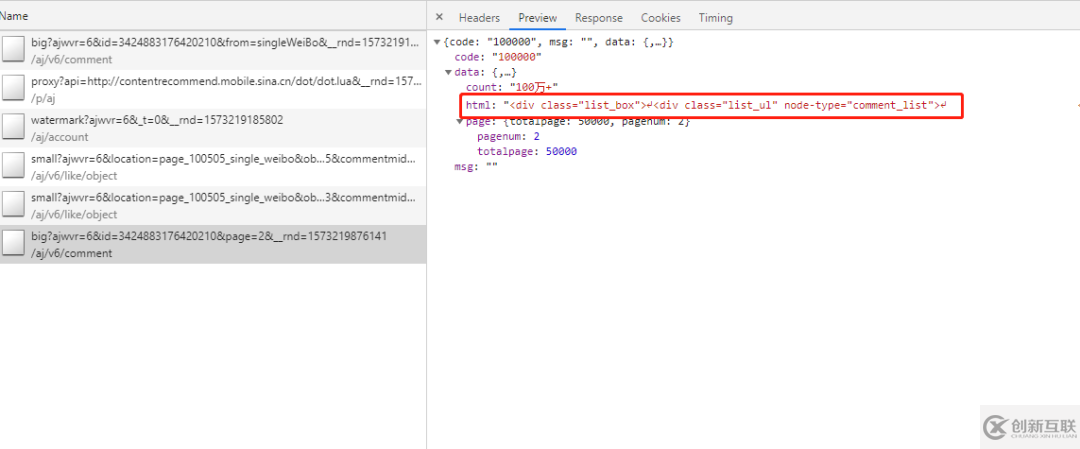
然后我们看新增的请求,你会发现在Preview中能看到格式化后的数据,而且里面有个html,仔细观察这个html你会发现这个就是评论列表的数据。我们仅需要将这个html解析出来即可。
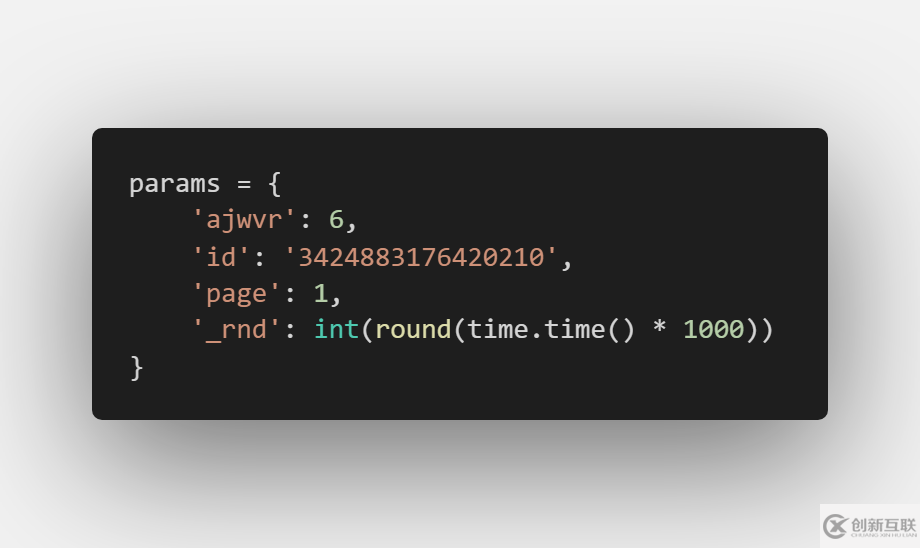
再看看get请求的URL:
https://weibo.com/aj/v6/comment/big?ajwvr=6&id=3424883176420210&page=2&__rnd=1573219876141
ajwvr是一个固定值为6、id是指想要爬取评论的微博id、page是指第几页评论、_rnd是请求时的毫秒级时间戳。
不过微博是要求登录才能看更多评论的,因此我们需要先访问微博,拿到cookie的值才能开始爬。
2.编写爬虫
关注文章最下方的Python实用宝典,回复微博评论爬虫即可获得本项目的完整源代码。
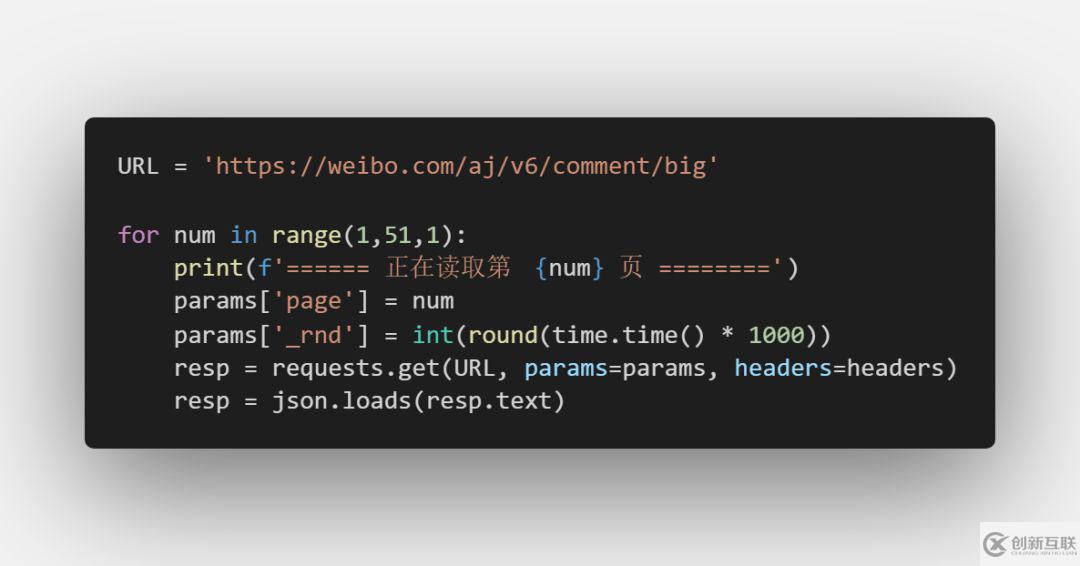
设定四个参数:
设定cookie:

发送请求并解析数据:
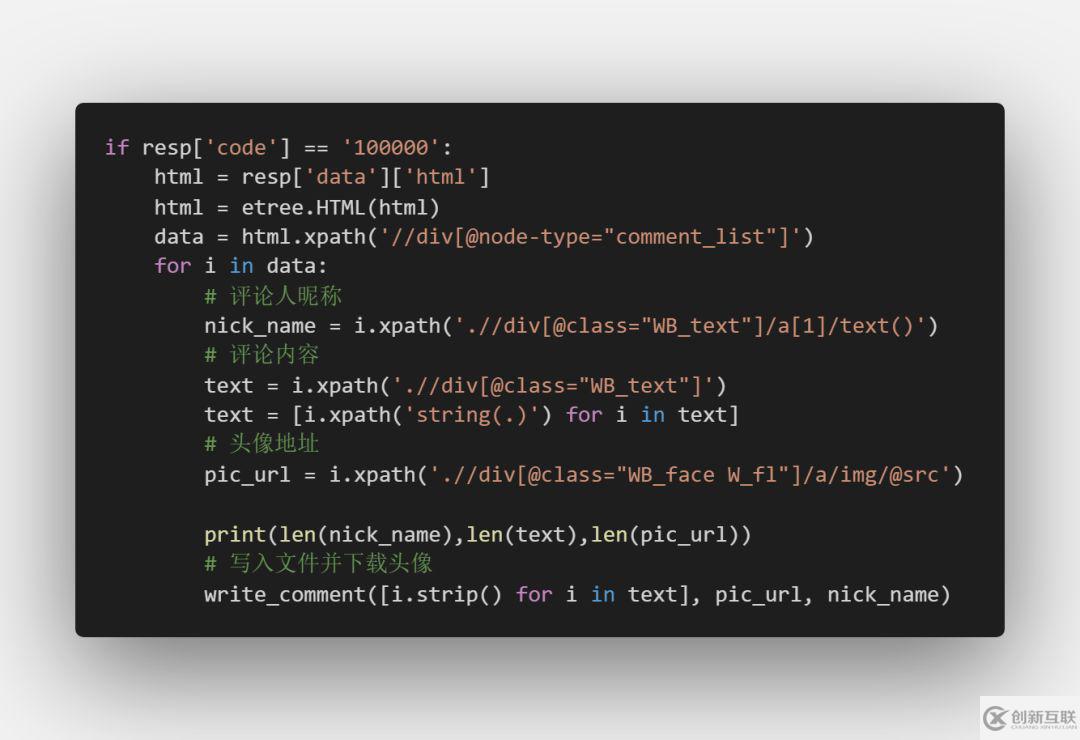
解析这串HTML中我们所需要的数据,这里用到了XPATH,如果你还不了解XPATH,可以看这篇文章《学爬虫利器XPath,看这一篇就够了》:
https://zhuanlan.zhihu.com/p/29436838
其中写入文件的函数和下载图片的函数如下:
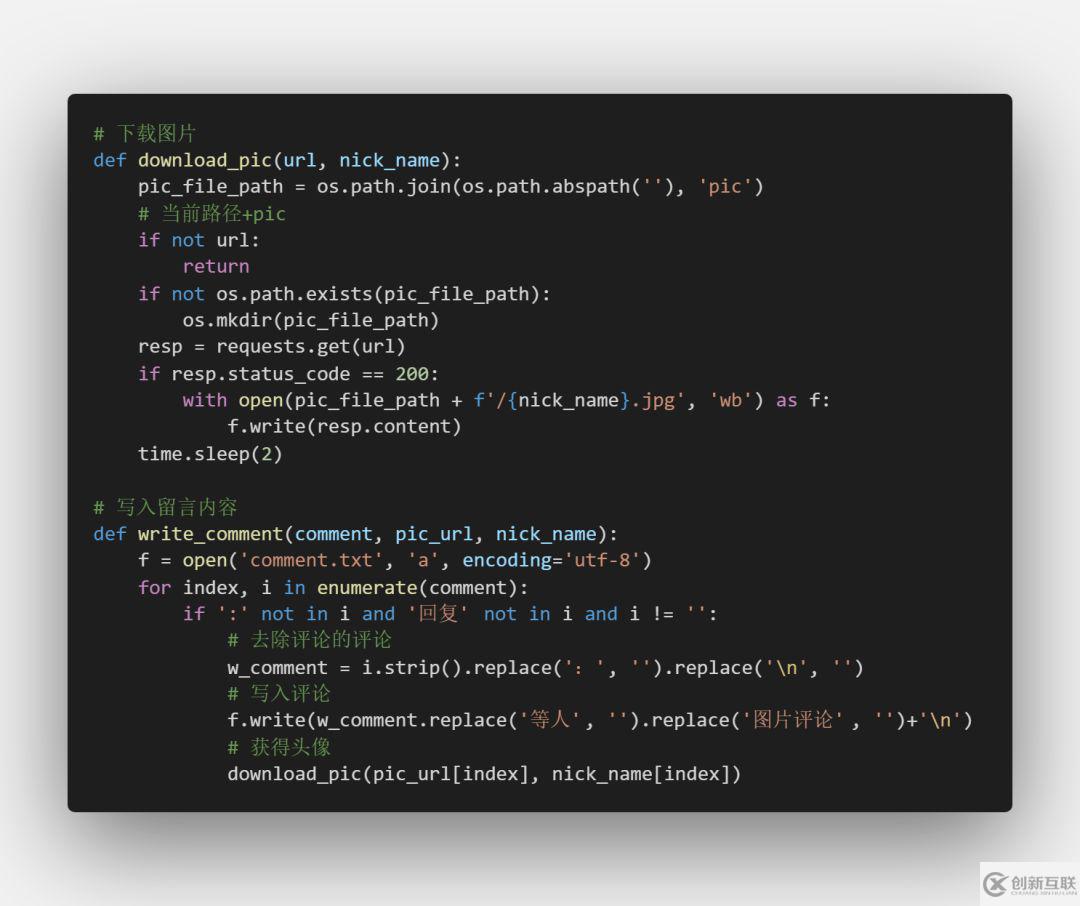
以上就是我们所用到的代码。在公众号后台回复 微博评论爬虫即可下载完整源代码(附手机版爬虫)。
3.定时爬虫
尽管如此,我们得到的数据还是不够,PC版的微博评论页面也仅仅支持爬到第五十页,第五十一页后就拿不到数据了,如图:
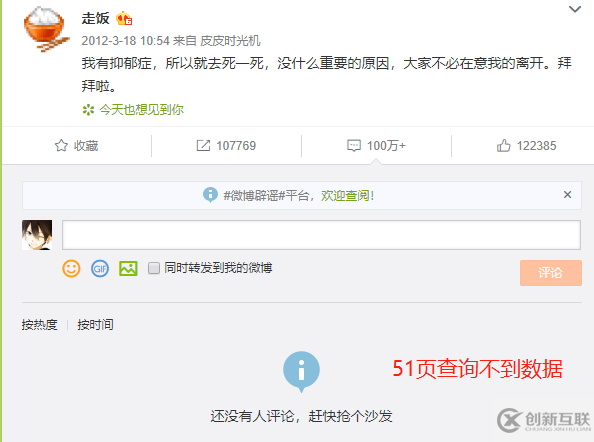
不过,走饭这个微博真的很多人回复,一天的数据就差不多50页了,我们可以通过每天定时爬50页来获取数据。linux系统可以使用crontab定时脚本实现,windows系统可以通过计划任务实现:
https://blog.csdn.net/wwy11/article/details/51100432
这里讲讲crontab实现方法。
假设你的Python存放在/usr/bin/且将脚本命名为weibo.py 存放在home中,在终端输入crontab -e后,在最后面增加上这一条语句即可:
0 0 * * * /usr/bin/python /home/weibo.py
上述内容就是Python 怎么爬取微博树洞,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注创新互联行业资讯频道。
标题名称:Python怎么爬取微博树洞
当前链接:https://www.cdcxhl.com/article2/ghdjoc.html
成都网站建设公司_创新互联,为您提供网站导航、网页设计公司、营销型网站建设、定制网站、定制开发、关键词优化
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 深圳网站建设定制网站优化策略? 2022-06-01
- 成都定制网站开发流程 2022-08-05
- 网站开发有哪几种?定制网站开发多少钱? 2023-02-12
- 为什么越来越多的公司开始选择定制网站 2020-11-13
- 网页设计公司为教育定制网站的作用 2016-10-22
- 网站建设如何选择企业模板网站和定制网站? 2022-04-18
- 定制网站和模板建站的区别 2018-01-26
- 企业如何做好定制网站开发的准备工作 2021-03-20
- 定制网站优于模板建设的五个点 2021-04-12
- 模板网站和定制网站有什么区别 2014-12-01
- 想要定制网站有思路但是没有界面和程序的实现 2022-02-26
- 企业定制网站的好处和必要性分析 2014-12-07