在flink中如何进行keyby窗口数据倾斜的优化
今天就跟大家聊聊有关在flink中如何进行keyby窗口数据倾斜的优化,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
创新互联公司专注于企业成都营销网站建设、网站重做改版、灵山网站定制设计、自适应品牌网站建设、H5技术、商城网站制作、集团公司官网建设、成都外贸网站建设公司、高端网站制作、响应式网页设计等建站业务,价格优惠性价比高,为灵山等各大城市提供网站开发制作服务。
在大数据处理领域,数据倾斜是一个非常常见的问题,我们就简单讲讲在flink中如何处理流式数据倾斜问题。
我们先来看一个可能产生数据倾斜的sql.
select TUMBLE_END(proc_time, INTERVAL '1' MINUTE) as winEnd,plat,count(*) as pv from source_kafka_table
group by TUMBLE(proc_time, INTERVAL '1' MINUTE) ,plat
在这个sql里,我们统计一个网站各个端的每分钟的pv,从kafka消费过来的数据首先会按照端进行分组,然后执行聚合函数count来进行pv的计算。如果某一个端产生的数据特别大,比如我们的微信小程序端产生数据远远大于其他app端的数据,那么把这些数据分组到某一个算子之后,由于这个算子的处理速度跟不上,就会产生数据倾斜。
查看flink的ui,会看到如下的场景。
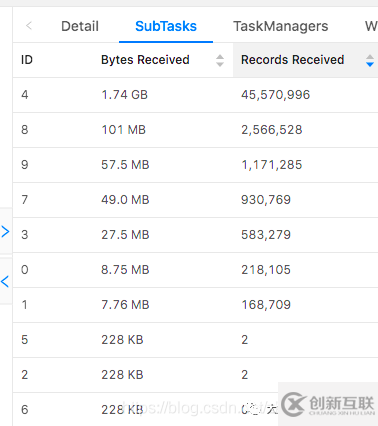
对于这种简单的数据倾斜,我们可以通过对分组的key加上随机数,再次打散,分别计算打散后不同的分组的pv数,然后在最外层再包一层,把打散的数据再次聚合,这样就解决了数据倾斜的问题。
优化后的sql如下:
select winEnd,split_index(plat1,'_',0) as plat2,sum(pv) from (
select TUMBLE_END(proc_time, INTERVAL '1' MINUTE) as winEnd,plat1,count(*) as pv from (
-- 最内层,将分组的key,也就是plat加上一个随机数打散
select plat || '_' || cast(cast(RAND()*100 as int) as string) as plat1 ,proc_time from source_kafka_table
) group by TUMBLE(proc_time, INTERVAL '1' MINUTE), plat1
) group by winEnd,split_index(plat1,'_',0)
在这个sql的最内层,将分组的key,也就是plat加上一个随机数打散,然后求打散后的各个分组(也就是sql中的plat1)的pv值,然后最外层,将各个打散的pv求和。
注意:最内层的sql,给分组的key添加的随机数,范围不能太大,也不能太小,太大的话,分的组太多,增加checkpoint的压力,太小的话,起不到打散的作用。在我的测试中,一天大概十几亿的数据量,5个并行度,随机数的范围在100范围内,就可以正常处理了。
修改后我们看到各个子任务的数据基本均匀了。
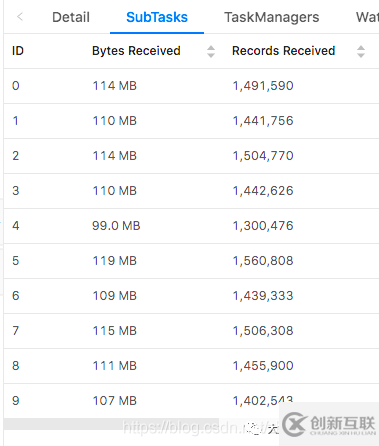
看完上述内容,你们对在flink中如何进行keyby窗口数据倾斜的优化有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注创新互联行业资讯频道,感谢大家的支持。
文章名称:在flink中如何进行keyby窗口数据倾斜的优化
URL标题:https://www.cdcxhl.com/article16/iehogg.html
成都网站建设公司_创新互联,为您提供虚拟主机、外贸网站建设、网页设计公司、网站制作、网站设计、外贸建站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 企业网站维护到底有多重要? 2016-09-02
- 成都网站维护公司告诉您—为什么要维护好你的网站 2016-09-23
- 手机端跟PC端的有哪些区别 2016-08-11
- 如何鉴别一个建站公司是否为一家专业建站公司 2015-01-14
- 网站维护交接注意事项? 2023-02-14
- 网络SEO推广时网站维护的重要内容有哪些? 2020-09-17
- 如何选择网站维护公司 这几点很关键 2021-04-27
- 你知道,小程序这5个带客方法吗? 2016-10-15
- 成都外贸网站建设市场价格一般在多少钱范围内 2015-01-25
- 了解什么是网站维护 2021-01-09
- 网站维护是做什么的? 2016-10-07
- app开发时需要注意的方面 2016-08-28