没看这篇干货,别说你会使用“缓存”
2021-02-02 分类: 网站建设
在互联网高速发展的今天,缓存技术被广泛地应用。无论业内还是业外,只要是提到性能问题,大家都会脱口而出“用缓存解决”。
图片来自 Unsplash
这种说法带有片面性,甚至是一知半解,但是作为专业人士的我们,需要对缓存有更深、更广的了解。
缓存技术存在于应用场景的方方面面。从浏览器请求,到反向代理服务器,从进程内缓存到分布式缓存。其中缓存策略,算法也是层出不穷,今天就带大家走进缓存。
处处皆缓存
缓存对于每个开发者来说是相当熟悉了,为了提高程序的性能我们会去加缓存,但是在什么地方加缓存,如何加缓存呢?
假设一个网站,需要提高性能,缓存可以放在浏览器,可以放在反向代理服务器,还可以放在应用程序进程内,同时可以放在分布式缓存系统中。
负载均衡缓存工作简图
以 Nginx 为例,我们看看它是如何工作的:
- 用户请求在达到应用服务器之前,会先访问 Nginx 负载均衡器,如果发现有缓存信息,直接返回给用户。
- 如果没有发现缓存信息,Nginx 回源到应用服务器获取信息。
- 另外,有一个缓存更新服务,定期把应用服务器中相对稳定的信息更新到 Nginx 本地缓存中。
进程内缓存
通过了客户端,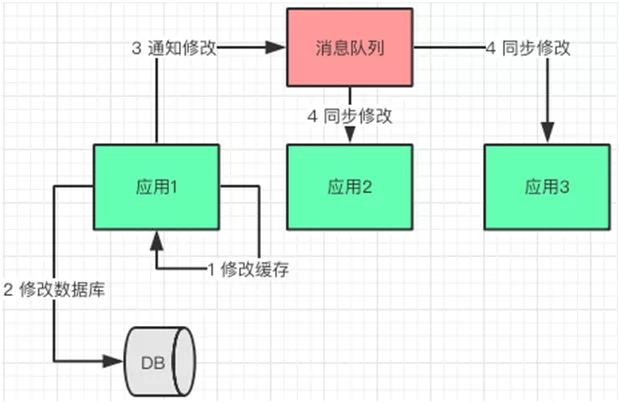
消息队列修改方案简图
Timer 修改方案
为了避免耦合,降低复杂性,对“实时一致性”不敏感的情况下。每个应用都会启动一个 Timer,定时从数据库拉取最新的数据,更新缓存。
不过在有的应用更新数据库后,其他节点通过 Timer 获取数据之间,会读到脏数据。这里需要控制好 Timer 的频率,以及应用与对实时性要求不高的场景。
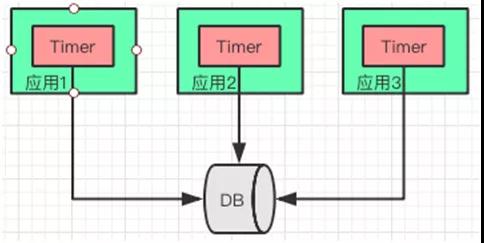
Timer 修改方案简图
进程内缓存有哪些使用场景呢?
- 场景一:只读数据,可以考虑在进程启动时加载到内存。当然,把数据加载到类似 Redis 这样的进程外缓存服务也能解决这类问题。
- 场景二:高并发,可以考虑使用进程内缓存,例如:秒杀。
分布式缓存
说完进程内缓存,自然就过度到进程外缓存了。与进程内缓存不同,进程外缓存在应用运行的进程之外,它拥有更大的缓存容量,并且可以部署到不同的物理节点,通常会用分布式缓存的方式实现。
分布式缓存是与应用分离的缓存服务,大的特点是,自身是一个独立的应用/服务,与本地应用隔离,多个应用可直接共享一个或者多个缓存应用/服务。
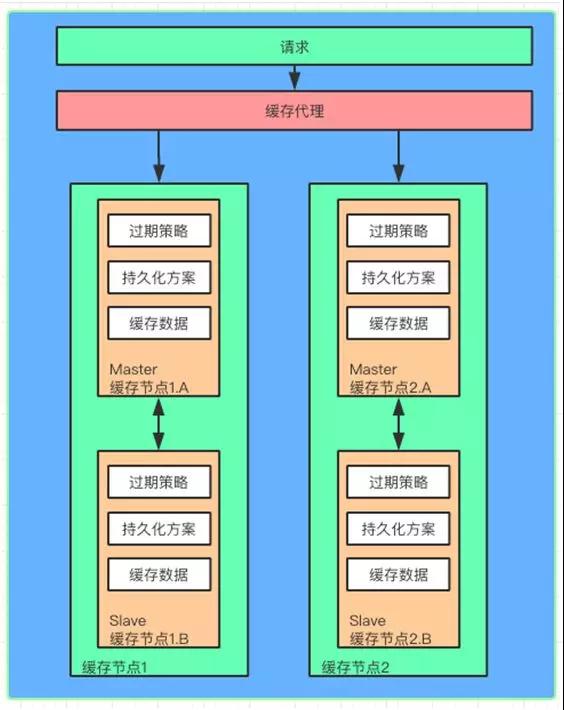
分布式缓存简图
既然是分布式缓存,缓存的数据会分布到不同的缓存节点上,每个缓存节点缓存的数据大小通常也是有限制的。
数据被缓存到不同的节点,为了能方便的访问这些节点,需要引入缓存代理,类似 Twemproxy。他会帮助请求找到对应的缓存节点。
同时如果缓存节点增加了,这个代理也会只能识别并且把新的缓存数据分片到新的节点,做横向的扩展。
为了提高缓存的可用性,会在原有的缓存节点上加入 Master/Slave 的设计。当缓存数据写入 Master 节点的时候,会同时同步一份到 Slave 节点。
一旦 Master 节点失效,可以通过代理直接切换到 Slave 节点,这时 Slave 节点就变成了 Master 节点,保证缓存的正常工作。
每个缓存节点还会提供缓存过期的机制,并且会把缓存内容定期以快照的方式保存到文件上,方便缓存崩溃之后启动预热加载。
高性能
当缓存做成分布式的时候,数据会根据一定的规律分配到每个缓存应用/服务上。
如果我们把这些缓存应用/服务叫做缓存节点,每个节点一般都可以缓存一定容量的数据,例如:Redis 一个节点可以缓存 2G 的数据。
如果需要缓存的数据量比较大就需要扩展多个缓存节点来实现,这么多的缓存节点,客户端的请求不知道访问哪个节点怎么办?缓存的数据又如何放到这些节点上?
缓存代理服务已经帮我们解决这些问题了,例如:Twemproxy 不但可以帮助缓存路由,同时可以管理缓存节点。
这里有介绍三种缓存数据分片的算法,有了这些算法缓存代理就可以方便的找到分片的数据了。
①哈希算法
Hash 表是最常见的数据结构,实现方式是,对数据记录的关键值进行 Hash,然后再对需要分片的缓存节点个数进行取模得到的余数进行数据分配。
例如:有三条记录数据分别是 R1,R2,R3。他们的 ID 分别是 01,02,03,假设对这三个记录的 ID 作为关键值进行 Hash 算法之后的结果依旧是 01,02,03。
我们想把这三条数据放到三个缓存节点中,可以把这个结果分别对 3 这个数字取模得到余数,这个余数就是这三条记录分别放置的缓存节点。
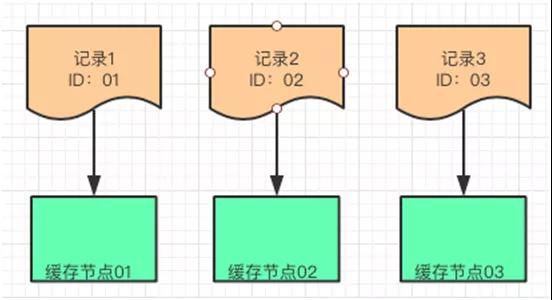
Hash 算法是某种程度上的平均放置,策略比较简单,如果要增加缓存节点,对已经存在的数据会有较大的变动。
②一致性哈希算法
一致性 Hash 是将数据按照特征值映射到一个首尾相接的 Hash 环上,同时也将缓存节点映射到这个环上。
如果要缓存数据,通过数据的关键值(Key)在环上找到自己存放的位置。这些数据按照自身的 ID 取 Hash 之后得到的值按照顺序在环上排列。
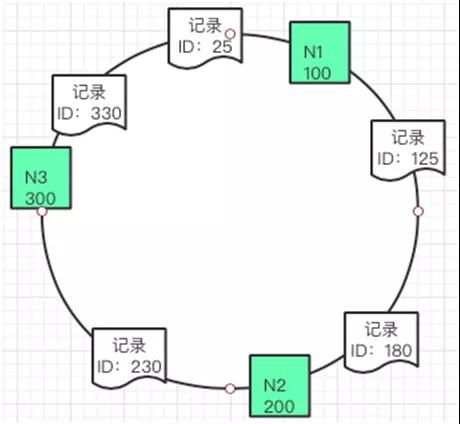
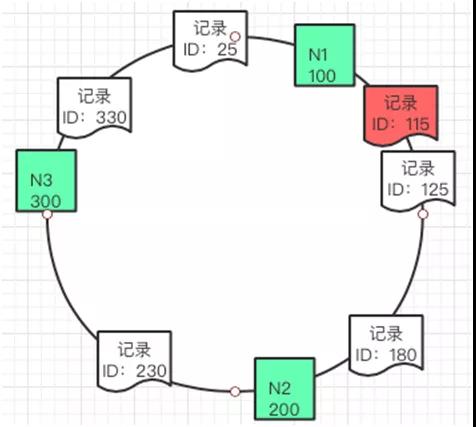
如果这个时候要插入一条新的数据其 ID 是 115,那么就应该插入到如下图的位置。
同理如果要增加一个缓存节点 N4 150,也可以放到如下图的位置。
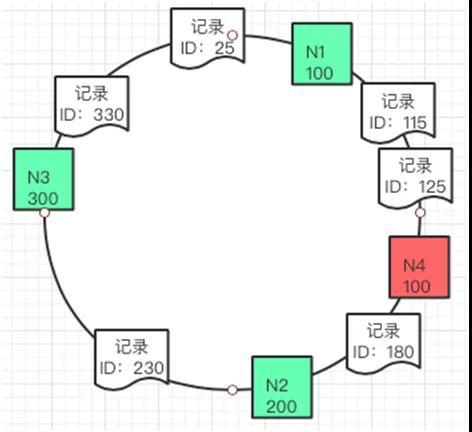
这种算法对于增加缓存数据,和缓存节点的开销相对比较小。
③Range Based 算法
这种方式是按照关键值(例如 ID)将数据划分成不同的区间,每个缓存节点负责一个或者多个区间。跟一致性哈希有点像。
例如:存在三个缓存节点分别是 N1,N2,N3。他们用来存放数据的区间分别是,N1(0, 100], N2(100, 200], N3(300, 400]。
那么数据根据自己 ID 作为关键字做 Hash 以后的结果就会分别对应放到这几个区域里面了。
可用性
根据事物的两面性,在分布式缓存带来高性能的同时,我们也需要重视它的可用性。那么哪些潜在的风险是我们需要防范的呢?
①缓存雪崩
当缓存失效,缓存过期被清除,缓存更新的时候。请求是无法命中缓存的,这个时候请求会直接回源到数据库。
如果上述情况频繁发生或者同时发生的时候,就会造成大面积的请求直接到数据库,造成数据库访问瓶颈。我们称这种情况为缓存雪崩。
从如下两方面来思考解决方案:
- 缓存方面
- 设计方面
缓存方面:
- 避免缓存同时失效,不同的 key 设置不同的超时时间。
- 增加互斥锁,对缓存的更新操作进行加锁保护,保证只有一个线程进行缓存更新。缓存一旦失效可以通过缓存快照的方式迅速重建缓存。对缓存节点增加主备机制,当主缓存失效以后切换到备用缓存继续工作。
设计方面,这里给出了几点建议供大家参考:
- 熔断机制:某个缓存节点不能工作的时候,需要通知缓存代理不要把请求路由到该节点,减少用户等待和请求时长。
- 限流机制:在接入层和代理层可以做限流(之前的文章讲到过),当缓存服务无法支持高并发的时候,前端可以把无法响应的请求放入到队列或者丢弃。
- 隔离机制:缓存无法提供服务或者正在预热重建的时候,把该请求放入队列中,这样该请求因为被隔离就不会被路由到其他的缓存节点。
如此就不会因为这个节点的问题影响到其他节点。当缓存重建以后,再从队列中取出请求依次处理。
②缓存穿透
缓存一般是 Key,Value 方式存在,一个 Key 对应的 Value 不存在时,请求会回源到数据库。
假如对应的 Value 一直不存在,则会频繁的请求数据库,对数据库造成访问压力。如果有人利用这个漏洞攻击,就麻烦了。
解决方法:如果一个 Key 对应的 Value 查询返回为空,我们仍然把这个空结果缓存起来,如果这个值没有变化下次查询就不会请求数据库了。
将所有可能存在的数据哈希到一个足够大的 Bitmap 中,那么不存在的数据会被这个 Bitmap 过滤器拦截掉,避免对数据库的查询压力。
③缓存击穿
在数据请求的时候,某一个缓存刚好失效或者正在写入缓存,同时这个缓存数据可能会在这个时间点被超高并发请求,成为“热点”数据。
这就是缓存击穿问题,这个和缓存雪崩的区别在于,这里是针对某一个缓存,前者是针对多个缓存。
解决方案:导致问题的原因是在同一时间读/写缓存,所以只有保证同一时间只有一个线程写,写完成以后,其他的请求再使用缓存就可以了。
比较常用的做法是使用 mutex(互斥锁)。在缓存失效的时候,不是立即写入缓存,而是先设置一个 mutex(互斥锁)。当缓存被写入完成以后,再放开这个锁让请求进行访问。
总结
今天内容有点多,让我们一起来回顾一下。缓存设计有五大策略,从用户请求开始依次是:
- HTTP 缓存
- CDN 缓存
- 负载均衡缓存
- 进程内缓存
- 分布式缓存
前两种缓存静态数据,后三种缓存动态数据:
- HTTP 缓存包括强制缓存和对比缓存。
- CDN 缓存和 HTTP 缓存是好搭档。
- 负载均衡器缓存相对稳定资源,需要服务协助工作。
- 进程内缓存,效率高,但容量有限制,有两个方案可以应对缓存同步的问题。
- 分布式缓存容量大,能力强,牢记三个性能算法并且防范三个缓存风险。
网站栏目:没看这篇干货,别说你会使用“缓存”
转载源于:https://www.cdcxhl.com/news4/98754.html
成都网站建设公司_创新互联,为您提供Google、App设计、搜索引擎优化、定制网站、定制开发、微信公众号
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
猜你还喜欢下面的内容
- 小程序浪潮下,各大平台的路该如何走? 2021-02-02
- 无服务器架构的三个重要意义 2021-02-02
- 香港服务器的优点 2021-02-02
- 5分钟搞清楚云计算的三种服务模式! 2021-02-02
- 商标与域名之间的不同之处 2021-02-02
- 企业网站安装SSL证书优势在哪里? 2021-02-02
- 智慧城市大数据可视化系统设计心得 2021-02-02

- SEO入门到精通需要这5个技巧 2021-02-02
- 企业网站被降权都有哪些原因? 2021-02-02
- 小程序:移动互联网的下一波浪潮 2021-02-02
- 互联网背景下商标使用困惑及解决路径 2021-02-02
- 如何做好容器安全 2021-02-02
- HTTPS:初识SSL 2021-02-02
- 六个js页面跳转的基本方法 2021-02-02
- 为什么现在的互联网起名字像动物园? 2021-02-02
- 云计算、大数据、人工智能是如何改变传统零售的? 2021-02-02
- 普通的小程序与定制版有哪些区别 2021-02-02
- 对ssl证书的六大常见错误 2021-02-02
- 怎么建一个高流量的网站 2021-02-02