Rest相比GraphQL有什么好处?
2021-03-13 分类: 网站建设
两种通过HTTP发送数据的方式:有什么区别?
通常情况下,GraphQL被视作一种革命性的对于API查询方式的思考,您可以发送查询,以便在一个请求中准确获取要查找的数据,而无需使用严格的服务器端定义。事实确实如此 - 当组织采用GraphQL时,它可以具有变革性,使前端和后端团队能够比以前更顺利地进行协作。 但实际上,这两种技术都涉及发送HTTP请求并接收一些结果,并且GraphQL包含许多内置的REST模型元素。
那么技术层面上真正发生了什么? 这两个API范例有什么相似之处和不同之处? 本文末尾的声明是,GraphQL和REST其实没有太大的不同,但是GraphQL有一些小的改变,这对开发者构建和使用API的体验产生了很大的影响。
因此,让我们直接进入。我们将定义一些API属性,然后讨论GraphQL和REST如何处理它们。
资源
REST的核心思想是资源。 每个资源都由一个URL标识,并通过向该URL发送GET请求来检索该资源。 你可能会得到一个JSON响应,因为这是大多数API现在使用的。 所以它看起来像这样:
GET /books/1
{ "title": "Black Hole Blues", "author": { "firstName": "Janna", "lastName": "Levin" } // ... more fields here}
Note: 在上面的示例中,一些REST API会将“author”作为单独的资源返回.
在REST中需要注意的一点是,资源的类型或形状以及您获取资源的方式是耦合的。 当您在REST文档中讨论上述内容时,您可能会将其称为“book endpoint”.
GraphQL在这方面完全不同,因为在GraphQL中,这两个概念是完全分离的。 在您的模式中,您可能有Book和Author类型:
type Book { id: ID title: String published: Date price: String author: Author}
type Author { id: ID firstName: String lastName: String books: [Book]}
请注意,我们所描述的各种数据可用,但这种描述不会告诉你任何关于如何在客户端获取这些对象。 这是REST和GraphQL的核心区别 - 特定资源的描述与您检索它的方式不相关。
为了能够实际访问特定的book或author,我们需要在我们的模式中创建一个Query类型:
type Query { book(id: ID!): Book author(id: ID!): Author}
现在,我们可以发送类似于上面的REST请求的请求,但是这次使用GraphQL:
GET /graphql?query={ book(id: "1") { title, author { firstName } } }
{ "title": "Black Hole Blues", "author": { "firstName": "Janna", }}
很好,现在我们到了某一步! 我们可以立即看到有关GraphQL的一些与REST完全不同的内容,即使两者都可以通过URL请求,并且两者都可以返回相同形式的JSON响应。
首先,我们可以看到带有GraphQL查询的URL指定了我们要求的资源以及我们关心的是哪些字段。 另外,API的使用者决定,而不是服务器作者为我们决定需要包含相关author资源。
但最重要的是,资源的标识,book和author的概念,并没有与它们被获取的方式相联系。 我们可以通过许多不同类型的查询以及不同的字段来检索相同的Book。
结论
我们已经确定了一些相似之处和差异:
- 相同点: 两者都有资源的概念,并可以为这些资源指定ID。
- 相同点: 两者都可以通过HTTP GET请求获取URL。
- 相同点: 两者都可以在请求中返回JSON数据。
- 不同: 在REST中,您调用的端点是该对象的标识。 在GraphQL中,标识与获取它的方式是分开的.
- 不同: 在REST中,资源的形状和大小由服务器决定。 在GraphQL中,服务器声明哪些资源可用,客户端询问它需要什么。。
好的,如果你已经使用了非常基础的GraphQL和/或REST, 如果你之前没有使用过GraphQL,你可以在Launchpad里面玩一玩 an example similar to the above ,Launchpad是一款用于在您的浏览器中构建和探索GraphQL示例的工具。
URL路由与GraphQL架构
如果API不可预测,则该API无用。 当你使用一个API时,你通常将它作为某个程序的一部分来执行,并且该程序需要知道它可以调用的内容以及它应该期望得到的结果,以便它可以运行得出结果。
因此,API中最重要的部分之一是对可访问内容的描述。 这是您在阅读API文档时学习的内容,以及使用Graphql自检和Rag API架构系统(如Swagger)时,可以通过编程方式检查此信息。
在当今的REST API中,API通常被描述为一个端点列表:
GET /books/:idGET /authors/:idGET /books/:id/commentsPOST /books/:id/comments
所以你可以说API的“形状”是线性的 - 有一系列你可以访问的东西。 当您检索数据或保存某些内容时,首先要问的问题是“我应该调用哪个端”?
在GraphQL中,如上所述,您不使用URL来标识API中可用的内容。 相反,您使用GraphQL模式:
type Query { book(id: ID!): Book author(id: ID!): Author}
type Mutation { addComment(input: AddCommentInput): Comment}
type Book { ... }type Author { ... }type Comment { ... }input AddCommentInput { ... }
与类似数据集的REST路由相比,这里有一些有趣的地方。 首先,不是将一个不同的HTTP动词发送到相同的URL来区分读取和写入,而是使用不同的 initial type --- Mutation vs. Query。 在GraphQL文档中,您可以选择使用关键字发送哪种类型的操作:
query { ... }mutation { ... }
有关查询语言的所有细节,请阅读我之前的文章, “GraphQL查询的解析”
你可以看到Query类型的字段与我们上面的REST路由很好地匹配。 这是因为这种特殊类型是我们数据的入口点,所以这是GraphQL中与端点URL最相同的概念。
您从GraphQL API获取初始资源的方式与REST非常相似 - 您传递了一个名称和一些参数 - 但主要区别在于您可以从那里开始。 在GraphQL中,您可以发送一个复杂查询,根据模式中定义的关系获取其他数据,但在REST中,您必须通过多个请求来完成此操作,将相关数据构建到初始响应中,或者在 修改响应的URL。
结论
在REST中,可访问数据的空间被描述为一个线性的端点列表,在GraphQL中它是一个包含关系的模式。
- 相同点: REST API中的端点列表与GraphQL API中Query和Mutation类型的字段列表类似。 它们都是数据的入口点。
- 相同点: 这两种方法都可以区分API请求是要读取数据还是写入数据。
- 不同: 在GraphQL中,您可以在单个请求中,按照模式中定义的关系从入口点遍历相关数据。 在REST中,您必须调用多个端点才能获取相关资源。
- 不同:在GraphQL中,Query类型的字段和任何其他类型的字段之间没有区别,只是查询的根目录只能访问查询类型。 例如,您可以在查询的任何字段中拥有参数。 在REST中,没有嵌套URL之类的概念。
- 不同: 在REST中,通过将HTTP动词从GET更改为POST等其他内容来指定写入。 在GraphQL中,您可以更改查询中的关键字。
由于上述相似性列表中的第一点,人们经常开始将Query类型的字段称为GraphQL“端点”或“查询”。 尽管这是一个合理的比较,但它可能会导致误导性的观点,即查询类型与其他类型显着不同,而事实并非如此。
路由处理程序与解析程序
那么当你实际调用API时会发生什么? 那么,通常它会在接收请求的服务器上执行一些代码。 该代码可以执行计算,从数据库加载数据,调用不同的API,或者真的做任何事情。 整个想法是你不需要从外面知道它在做什么。 但是REST和GraphQL都有相当标准的方法来实现该API的内部,并且将它们进行比较以了解这些技术是如何不同的。
在这个比较中,我将使用JavaScript代码,因为这是我最熟悉的,但是当然,您可以在几乎任何编程语言中实现REST和GraphQL API。 我也会跳过设置服务器所需的任何样板文件,因为这对概念并不重要。
让我们来看一下hello world中的一个快速示例,一个用于Node的流行API库:
app.get('/hello', function (req, res) {
res.send('Hello World!')
})
在这里你看到我们已经创建了一个返回字符串'Hello World!'的/hello端点。 从这个例子中,我们可以看到REST API服务器中HTTP请求的生命周期:
- 服务器收到请求并检索HTTP动词(本例中为GET)和URL路径
- API库将动词和路径与由服务器代码注册的函数进行匹配
- 该函数执行一次,并返回一个结果
- API库序列化结果,添加适当的响应代码和标题,并将其发送回客户端
GraphQL的工作方式非常类似,也是相同的hello world example
const resolvers = { Query: { hello: () => { return 'Hello world!';
}, },};
正如你所看到的,我们不是为某个特定的URL提供一个函数,而是提供了一个匹配某个类型的特定字段的函数,在这种情况下,这个函数是Query类型的hello字段。 在GraphQL中,实现字段的这个函数被称为 解析器。
为了发出请求,我们需要一个查询:
query { hello}
因此,当我们的服务器收到一个GraphQL请求时会发生什么情况:
- 服务器接收请求并检索GraphQL查询
- 遍历查询,并为每个字段调用适当的解析器。 在这种情况下,只有一个字段,你好,它在查询类型
- 函数被调用,并返回一个结果
- GraphQL库和服务器将结果附加到与查询形状相匹配的响应
所以你会接收到:
{ "hello": "Hello, world!" }
但是这里有一个技巧,我们实际上可以调用两次这个Query!
query { hello secondHello: hello}
在这种情况下,同样的生命周期发生在上面,但由于我们使用别名请求了两次相同的字段,所以hello解析器实际上称为twice。 这显然是一个人为的例子,但重点是可以在一个请求中执行多个字段,并且可以在查询中的不同点处多次调用同一个字段。
没有“嵌套”解析器的例子,这将是不完整的:
{ Query: { author: (root, { id }) => find(authors, { id: id }), }, Author: { posts: (author) => filter(posts, { authorId: author.id }), },}
这些解析器将能够完成如下查询:
query { author(id: 1) { firstName posts { title } }}
所以即使解析器的集合实际上是平坦的,因为它们被附加到各种类型,您可以将它们构建为嵌套查询。在帖子中阅读更多关于GraphQL执行如何工作的信息 “GraphQL 解释”.
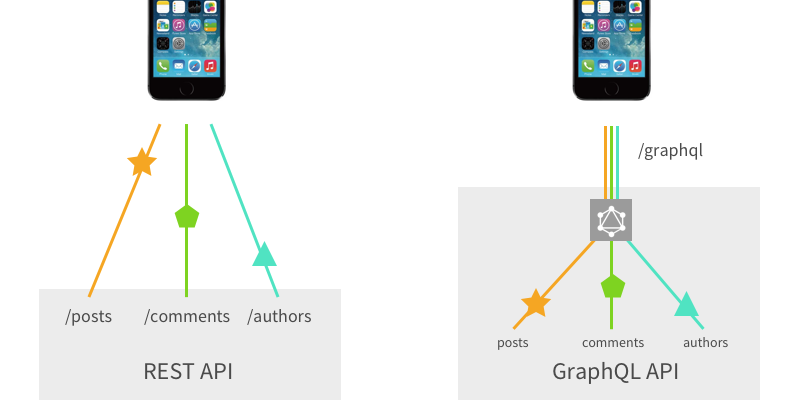
结论
在这一天结束时,REST和GraphQL API都是通过网络调用功能的奇特方式。 如果您熟悉构建REST API,那么实施GraphQL API不会有太大的不同。 但是GraphQL有很大的优势,因为它可以让你调用几个相关的函数而不需要多次往返。
- 相同: REST中的端点和GraphQL中的字段最终都会调用服务器上的函数。
- 相同: REST和GraphQL通常都依赖于框架和库来处理基本的联网样板。
- 不同: 在REST中,每个请求通常只调用一个路由处理函数。 在GraphQL中,一个查询可以调用许多解析器来构造具有多个资源的嵌套响应。
- 不同: 在REST中,您自己构建响应的形状。 在GraphQL中,响应的形状由GraphQL执行库构建,以匹配查询的形状。
从本质上讲,您可以将GraphQL想象成一个在一个请求中调用多个嵌套端点的系统。 几乎就像一个多路复用的REST。
所有的这些都意味着什么呢?
在这篇特别的文章中,我们没有太多空间可以参与。 例如,对象标识,超媒体或高速缓存。 也许这将是以后的一个话题。 但是我希望你们同意,当你看一看基本的知识时,REST和GraphQL正在使用基本相似的概念。
我认为GraphQL有一些差异。 特别是,我认为能够将您的API作为一组小的解析器函数实现是非常酷的,然后有能力发送一个复杂的查询,以可预测的方式一次检索多个资源。 这节省了API实现者不必创建具有特定形状的多个端点,并且使得API消费者能够避免获取他们不需要的额外数据。
另一方面,GraphQL没有REST那么多的工具和集成。 例如,您无法像使用REST结果一样轻松地缓存使用HTTP缓存的GraphQL结果。 但社区正在努力改善工具和基础设施。 例如,您可以使用Apollo Client和Relay在您的前端缓存GraphQL结果,最近也可以在服务器上使用Apollo Engine.缓存GraphQL结果。
文章标题:Rest相比GraphQL有什么好处?
转载注明:https://www.cdcxhl.com/news33/105133.html
成都网站建设公司_创新互联,为您提供营销型网站建设、服务器托管、小程序开发、静态网站、关键词优化、外贸网站建设
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
猜你还喜欢下面的内容
- 一些你经常会用到的redis命令 2021-03-13
- WAF开发之Cookie安全防护 2021-03-13
- 服务器成勒索攻击重灾区 超五成缘于“弱口令” 2021-03-13
- 智能dns解析的真正含义 2021-03-13
- 无服务器架构有什么优缺点? 2021-03-13
- URI和URL的区别 2021-03-13
- 服务器租用qq7459652这家真的好吗? 2021-03-13
- 常见的Web负载均衡方法 2021-03-13

- 双线机房优势和不足 2021-03-13
- 网络性能好坏主要体现在那几方面 2021-03-13
- 视频存储服务器应该多大更加合适? 2021-03-13
- web安全性考虑的几方面 2021-03-13
- bgp和双线的区别,如何鉴定bgp双线? 2021-03-13
- 10种防止网络攻击的方法 2021-03-13
- 你使用过阿里dns吗? 2021-03-13
- 视频服务器价格 2021-03-13
- 附加存储服务器的五个缺点 2021-03-13
- 为何这么多人在搜索框中输入“www.baidu.com”? 2021-03-13
- ERP财务软件常见问题 2021-03-13