大数据HDFS读写数据的过程探究
2021-03-07 分类: 网站建设
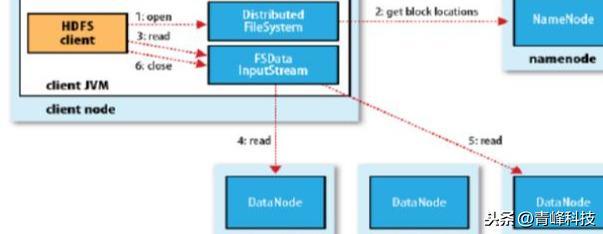
读数据
- 跟namenode通信查询元数据,找到文件块所在的datanode服务器
- 挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
- datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
- 客户端以packet为单位接收,现在本地缓存,然后写入目标文件
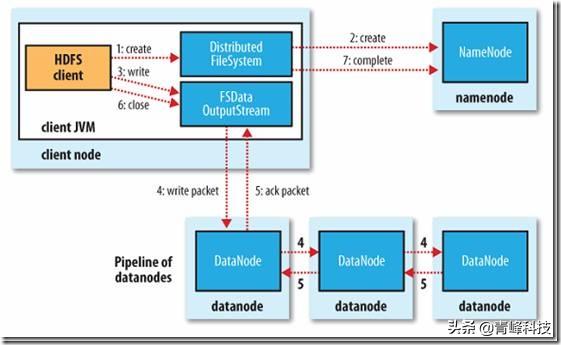
写数据
- 根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
- namenode返回是否可以上传
- client请求第一个 block该传输到哪些datanode服务器上
- namenode返回3个datanode服务器ABC
- client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
- client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
- 当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
网络故障,脏数据如何解决?
DataNode 失效等问题,这些问题 HDFS 在设计的时候都早已考虑到了。下面来介绍一下数据损坏处理流程:
- 当 DataNode 读取 block 的时候,它会计算 checksum。
- 如果计算后的 checksum,与 block 创建时值不一样,说明该 block 已经损坏。
- Client 读取其它 DataNode上的 block。
- NameNode 标记该块已经损坏,然后复制 block 达到预期设置的文件备份数 。
- DataNode 在其文件创建后验证其 checksum。
读写过程,数据完整性如何保持?
通过校验和。因为每个chunk中都有一个校验位,一个个chunk构成packet,一个个packet最终形成block,故可在block上求校验和。
HDFS 的client端即实现了对 HDFS 文件内容的校验和 (checksum) 检查。当客户端创建一个新的HDFS文件时候,分块后会计算这个文件每个数据块的校验和,此校验和会以一个隐藏文件形式保存在同一个 HDFS 命名空间下。当client端从HDFS中读取文件内容后,它会检查分块时候计算出的校验和(隐藏文件里)和读取到的文件块中校验和是否匹配,如果不匹配,客户端可以选择从其他 Datanode 获取该数据块的副本。
HDFS中文件块目录结构具体格式如下:
- ${dfs.datanode.data.dir}/
- ├── current
- │ ├── BP-526805057-127.0.0.1-1411980876842
- │ │ └── current
- │ │ ├── VERSION
- │ │ ├── finalized
- │ │ │ ├── blk_1073741825
- │ │ │ ├── blk_1073741825_1001.meta
- │ │ │ ├── blk_1073741826
- │ │ │ └── blk_1073741826_1002.meta
- │ │ └── rbw
- │ └── VERSION
- └── in_use.lock
in_use.lock表示DataNode正在对文件夹进行操作
rbw是“replica being written”的意思,该目录用于存储用户当前正在写入的数据。
Block元数据文件(*.meta)由一个包含版本、类型信息的头文件和一系列校验值组成。校验和也正是存在其中。
当前文章:大数据HDFS读写数据的过程探究
文章分享:https://www.cdcxhl.com/news32/104632.html
成都网站建设公司_创新互联,为您提供标签优化、关键词优化、自适应网站、虚拟主机、网站营销、网站制作
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
猜你还喜欢下面的内容
- 小微企业互联网营销不玩SEO优化还能做什么? 2021-03-07
- 推广平台那么多,为什么要建立小程序 2021-03-07
- 一名优秀电商运营的日常 2021-03-07
- “互联网+”的时代下,直销企业如何转型,路在何方? 2021-03-07
- 建久安之势 成长治之业 习近平这样推进网络安全建设 2021-03-07

- “云”对我们到底有什么用,计算?服务? 2021-03-07
- ”社交电商赛道上的“弯道超车“,给传统电商来了个“下马威 2021-03-07
- 企业如何利用网站进行网络营销推广 2021-03-07
- COM更通用,域名后缀可以识别 2021-03-07
- 什么是API接口? 2021-03-07
- 为什么选择SSL?使用SSL证书的目的是什么 2021-03-07
- JavaScript编程中常用到的一些小技巧 2021-03-07
- 营销邮件方式如此多,如何脱颖而出? 2021-03-07
- 社交电商最核心的就是社交化裂变模式 2021-03-07
- seo优化怎样做才能够做得更好 2021-03-07
- app域名值不值得投资 2021-03-07
- 企业几乎都在用的管理神器——CRM 2021-03-07
- 用Dreamweaver怎样制作网页模板 2021-03-07
- 如何制作交互组件库 提升工作效率 2021-03-07