资深程序员多年总结:解密Kafka吞吐量高的原因
2021-02-04 分类: 网站建设
众所周知kafka的吞吐量比一般的消息队列要高,号称the fastest,那他是如何做到的,让我们从以下几个方面分析一下原因。
生产者(写入数据)
生产者(producer)是负责向Kafka提交数据的,我们先分析这一部分。
Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度Kafak采用了两个技术,顺序写入和MMFile。
顺序写入
因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最“讨厌”随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。
使用这种方式可以获取很大的I/O提升,省去了用户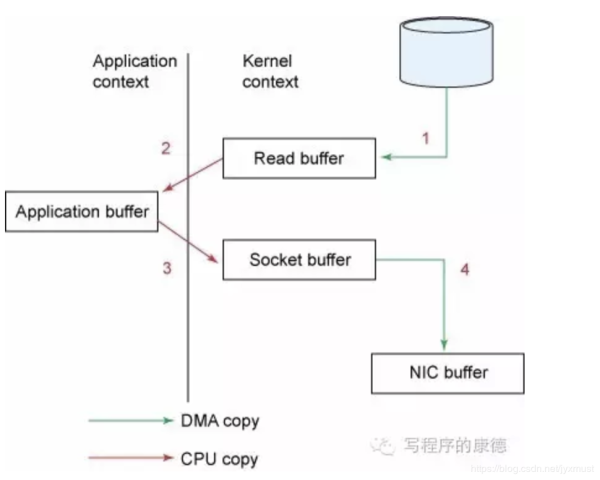
先复制到内核
Zero Copy中直接从内核空间(DMA的)到内核空间(Socket的),然后发送网卡。
这个技术非常普遍,The C10K problem 里面也有很详细的介绍,Nginx也是用的这种技术,稍微搜一下就能找到很多资料。
Java的NIO提供了FileChannle,它的transferTo、transferFrom方法就是Zero Copy。
Kafka是如何耍赖的?
想到了吗?Kafka把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候Kafka直接把“文件”发送给消费者。这就是秘诀所在,比如:10W的消息组合在一起是10MB的数据量,然后Kafka用类似于发文件的方式直接扔出去了,如果消费者和生产者之间的网络非常好(只要网络稍微正常一点10MB根本不是事。。。家里上网都是100Mbps的带宽了),10MB可能只需要1s。所以答案是——10W的TPS,Kafka每秒钟处理了10W条消息。
可能你说:不可能把整个文件发出去吧?里面还有一些不需要的消息呢?是的,Kafka作为一个“高级作弊分子”自然要把作弊做的有逼格。Zero Copy对应的是sendfile这个函数(以Linux为例),这个函数接受
out_fd作为输出(一般及时socket的句柄)
in_fd作为输入文件句柄
off_t表示in_fd的偏移(从哪里开始读取)
size_t表示读取多少个
没错,Kafka是用mmap作为文件读写方式的,它就是一个文件句柄,所以直接把它传给sendfile;偏移也好解决,用户会自己保持这个offset,每次请求都会发送这个offset。(还记得吗?放在zookeeper中的);数据量更容易解决了,如果消费者想要更快,就全部扔给消费者。如果这样做一般情况下消费者肯定直接就被压死了;所以Kafka提供了的两种方式——Push,我全部扔给你了,你死了不管我的事情;Pull,好吧你告诉我你需要多少个,我给你多少个。
总结
Kafka速度的秘诀在于,它把所有的消息都变成一个的文件。通过mmap提高I/O速度,写入数据的时候它是末尾添加所以速度最优;读取数据的时候配合sendfile直接暴力输出。阿里的RocketMQ也是这种模式,只不过是用Java写的。
单纯的去测试MQ的速度没有任何意义,Kafka这种“暴力”、“流氓”、“无耻”的做法已经脱了MQ的底裤,更像是一个暴力的“数据传送器”。所以对于一个MQ的评价只以速度论英雄,世界上没人能干的过Kafka,我们设计的时候不能听信网上的流言蜚语——“Kafka最快,大家都在用,所以我们的MQ用Kafka没错”。在这种思想的作用下,你可能根本不会关心“失败者”;而实际上可能这些“失败者”是更适合你业务的MQ。
文章名称:资深程序员多年总结:解密Kafka吞吐量高的原因
文章来源:https://www.cdcxhl.com/news/99160.html
成都网站建设公司_创新互联,为您提供微信公众号、外贸建站、建站公司、做网站、Google、用户体验
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
猜你还喜欢下面的内容
- 为什么要做小程序?小程序对营销有什么作用? 2021-02-04
- 小程序关乎赚钱的4项功能! 2021-02-04
- 网络营销是什么?网络销售方法你知多少 2021-02-04
- 认养农业应该怎样玩? 2021-02-04
- 小语种建站并不是简单翻译网站! 2021-02-04
- 网站推广能够给企业带来哪些好处 2021-02-04

- 合理运用小程序营销,快速吸引精准用户 2021-02-04
- 现在电商还好不好做了?新手要不要入电商行业? 2021-02-04
- 手机建站,留住客户有技巧! 2021-02-04
- 关于商标注册:什么是商标,商标怎样使用,有效期限是多少? 2021-02-04
- 什么是SSL证书,网站安装SSL证书有什么作用? 2021-02-04
- 数据中心管理人员面临的三大障碍 2021-02-04
- 什么域名可以注册 2021-02-04
- 你清楚品牌策略,营销策略和传播策略之间的区别吗? 2021-02-04
- 这就是Linux在服务器OS市场如此受欢迎的原因 2021-02-04
- 社交电商井喷式发展,社交新零售给个人能带来什么? 2021-02-04
- 45个数字助你认清当前AI技术态势 2021-02-04
- Wireshark解密HTTPS流量的两种方法 2021-02-04
- 零基础,小白WordPress建站完整教程 2021-02-04