分布式架构下的负载均衡简单易懂
2021-02-01 分类: 网站建设
百度词条里的解释是:负载均衡,英文叫Load Balance,意思就是将请求或者数据分摊到多个操作单元上进行执行,共同完成工作任务。
它的目的就通过调度集群,达到好化资源使用,大化吞吐率,最小化响应时间,避免单点过载的问题。
负载均衡分类
负载均衡可以根据网络协议的层数进行分类,我们这里以ISO模型为准,从下到上分为:
物理层,数据链路层,网络层,传输层,会话层,表示层,应用层。
当客户端发起请求,会经过层层的封装,发给服务器,服务器收到请求后经过层层的解析,获取到对应的内容。
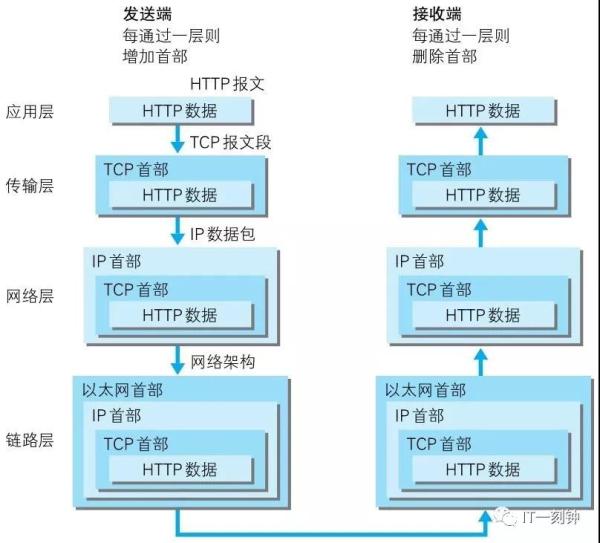
HTTP协议
二层负载均衡
二层负债均衡是基于数据链路层的负债均衡,即让负债均衡服务器和业务服务器绑定同一个虚拟IP(即VIP),客户端直接通过这个VIP进行请求,那么如何区分相同IP下的不同机器呢?没错,通过MAC物理地址,每台机器的MAC物理地址都不一样,当负载均衡服务器接收到请求之后,通过改写HTTP报文中以太网首部的MAC地址,按照某种算法将请求转发到目标机器上,实现负载均衡。
这种方式负载方式虽然控制粒度比较粗,但是优点是负载均衡服务器的压力会比较小,负载均衡服务器只负责请求的进入,不负责请求的响应(响应是有后端业务服务器直接响应给客户端),吞吐量会比较高。
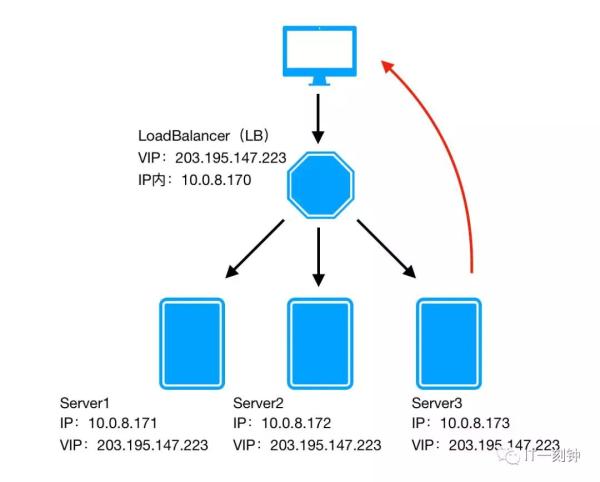
两层负载
三层负载均衡
三层负载均衡是基于网络层的负载均衡,通俗的说就是按照不同机器不同IP地址进行转发请求到不同的机器上。
这种方式虽然比二层负载多了一层,但从控制的颗粒度上看,并没有比二层负载均衡更有优势,并且,由于请求的进出都要经过负载均衡服务器,会对其造成比较大的压力,性能也比二层负载均衡要差。
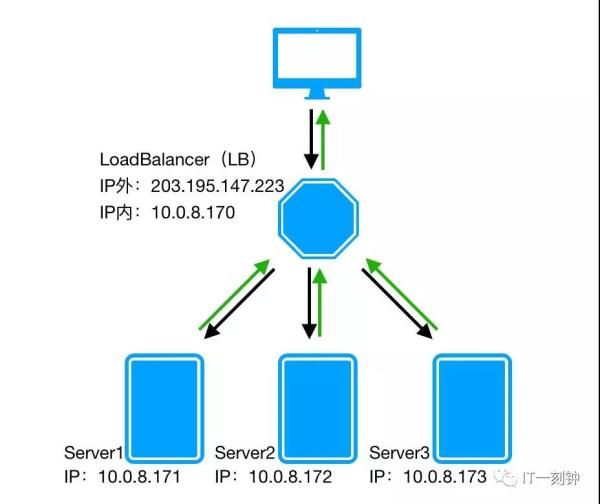
三层负载
四层负载均衡
四层负载均衡是基于传输层的负载均衡,传输层的代表协议就是TCP/UDP协议,除了包含IP之外,还有区分了端口号,通俗的说就是基于IP+端口号进行请求的转发。相对于上面两种,控制力度缩小到了端口,可以针对同一机器上的不用服务进行负载。
这一层以LVS为代表。

无图
七层负载均衡
七层负载均衡是基于应用层的负载均衡,应用层的代表协议有HTTP,DNS等,可以根据请求的url进行转发负载,比起四层负载,会更加的灵活,所控制到的粒度也是最细的,使得整个网络更"智能化"。例如访问一个网站的用户流量,可以通过七层的方式,将对图片类的请求转发到特定的图片服务器并可以使用缓存技术;将对文字类的请求可以转发到特定的文字服务器并可以使用压缩技术。可以说功能是非常强大的负载。

独自骄傲
这一层以Nginx为代表。
在普通的应用架构中,使用Nginx完全可以满足需求,对于一些大型应用,一般会采用DNS+LVS+Nginx的方式进行多层次负债均衡,以上这些说明都是基于软件层面的负载均衡,在一些超大型的应用中,还会在前面多加一层物理负载均衡,比如知名的F5。
负载均衡算法负载均衡算法分为两类:
一种是静态负载均衡,一种是动态负载均衡。
静态均衡算法:
1、轮询法
将请求按顺序轮流地分配到每个节点上,不关心每个节点实际的连接数和当前的系统负载。
优点:简单高效,易于水平扩展,每个节点满足字面意义上的均衡;
缺点:没有考虑机器的性能问题,根据木桶最短木板理论,集群性能瓶颈更多的会受性能差的服务器影响。
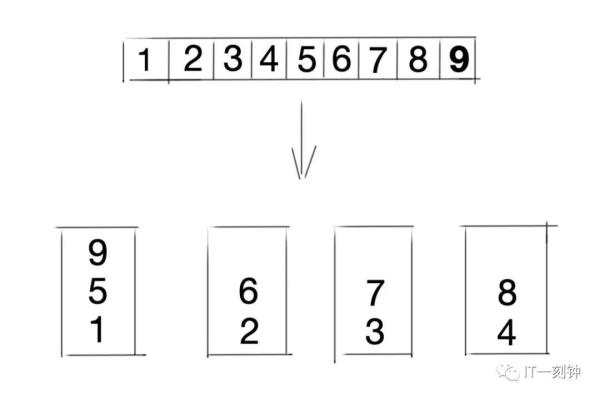
轮询
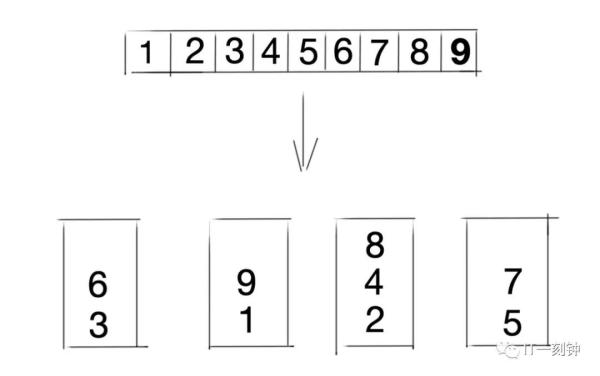
2、随机法
将请求随机分配到各个节点。由概率统计理论得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配,也就是轮询的结果。
优缺点和轮询相似。
随机
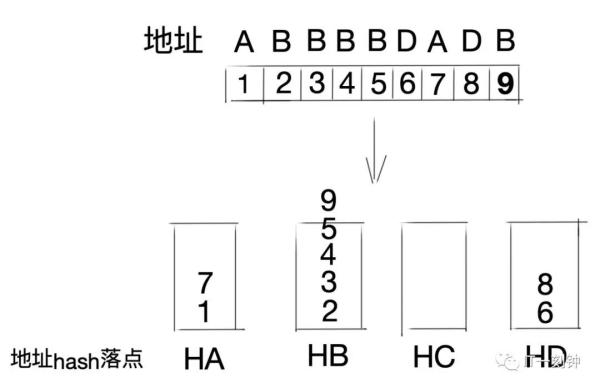
3、源地址哈希法
源地址哈希的思想是根据客户端的IP地址,通过哈希函数计算得到一个数值,用该数值对服务器节点数进行取模,得到的结果便是要访问节点序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会落到到同一台服务器进行访问。
优点:相同的IP每次落在同一个节点,可以人为干预客户端请求方向,例如灰度发布;
缺点:如果某个节点出现故障,会导致这个节点上的客户端无法使用,无法保证高可用。当某一用户成为热点用户,那么会有巨大的流量涌向这个节点,导致冷热分布不均衡,无法有效利用起集群的性能。所以当热点事件出现时,一般会将源地址哈希法切换成轮询法。
哈希法
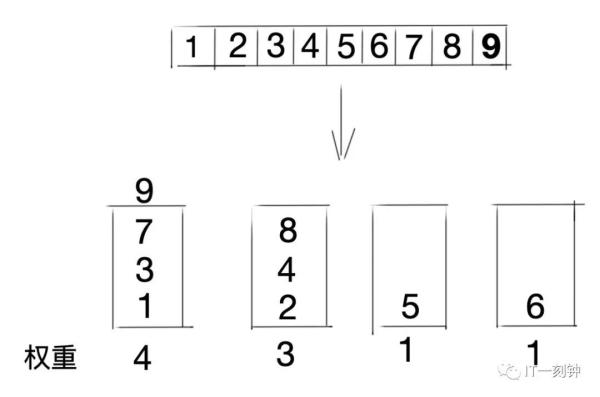
4、加权轮询法
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
加权轮询算法要生成一个服务器序列,该序列中包含n个服务器。n是所有服务器的权重之和。在该序列中,每个服务器的出现的次数,等于其权重值。并且,生成的序列中,服务器的分布应该尽可能的均匀。比如序列{a, a, a, a, a, b, c}中,前五个请求都会分配给服务器a,这就是一种不均匀的分配方法,更好的序列应该是:{a, a, b, a, c, a, a}。
优点:可以将不同机器的性能问题纳入到考量范围,集群性能最优大化;
缺点:生产环境复杂多变,服务器抗压能力也无法精确估算,静态算法导致无法实时动态调整节点权重,只能粗糙优化。
加权轮询
5、加权随机法
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
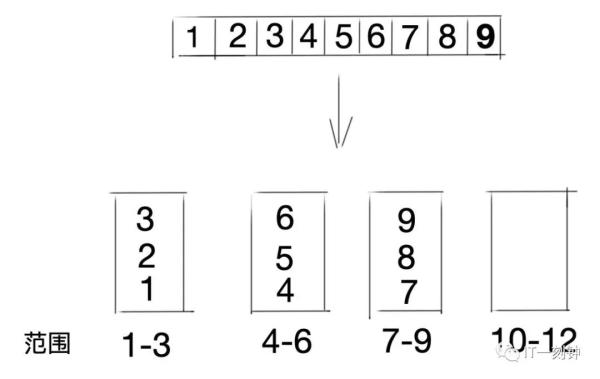
6、键值范围法
根据键的范围进行负债,比如0到10万的用户请求走第一个节点服务器,10万到20万的用户请求走第二个节点服务器……以此类推。
优点:容易水平扩展,随着用户量增加,可以增加节点而不影响旧数据;
缺点:容易负债不均衡,比如新注册的用户活跃度高,旧用户活跃度低,那么压力就全在新增的服务节点上,旧服务节点性能浪费。而且也容易单点故障,无法满足高可用。
键值范围法
(注:以上所提到的单点故障,都可以用主从方式来解决,从节点监听主节点心跳,当发现主节点死亡,从节点切换成主节点顶替上去。这里可以思考一个问题,怎么设计集群主从可以大程度上降低成本)
动态负债均衡算法:
1、最小连接数法
根据每个节点当前的连接情况,动态地选取其中当前积压连接数最少的一个节点处理当前请求,尽可能地提高后端服务的利用效率,将请求合理地分流到每一台服务器。俗称闲的人不能闲着,大家一起动起来。
优点:动态,根据节点状况实时变化;
缺点:提高了复杂度,每次连接断开需要进行计数;
实现:将连接数的倒数当权重值。
2、最快响应速度法
根据请求的响应时间,来动态调整每个节点的权重,将响应速度快的服务节点分配更多的请求,响应速度慢的服务节点分配更少的请求,俗称能者多劳,扶贫救弱。
优点:动态,实时变化,控制的粒度更细,跟灵敏;
缺点:复杂度更高,每次需要计算请求的响应速度;
实现:可以根据响应时间进行打分,计算权重。
3、观察模式法
观察者模式是综合了最小连接数和最快响应度,同时考量这两个指标数,进行一个权重的分配。
分享题目:分布式架构下的负载均衡简单易懂
文章路径:https://www.cdcxhl.com/news/98579.html
成都网站建设公司_创新互联,为您提供域名注册、搜索引擎优化、网站排名、手机网站建设、关键词优化、网页设计公司
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
猜你还喜欢下面的内容
- 弄清社交电商与社群电商的四大核心差异 2021-02-01
- 线下门店的价值,没那么简单 2021-02-01
- 企业网站SEO优化推广的重要性 2021-02-01
- 当今社会域名呈现无与伦比的新价值 2021-02-01
- 没程序没美工中小微企业应当如何快速建站? 2021-02-01
- API网关:API 网关从入门到放弃 2021-02-01
- SEO风格和跨境电商独立站流量增长 2021-02-01

- 企业现在做seo优化效果到底怎么样? 2021-02-01
- 网络营销推广渠道数据修炼内功缺一不可 2021-02-01
- 大数据要学习什么知识?大数据学习的内容有哪些? 2021-02-01
- 有一种隐形的财富叫商标,你手里的商标价值多少? 2021-02-01
- 如何搭建自己的云平台 2021-02-01
- 企业开发小程序需要哪些前提条件 2021-02-01
- 传统企业中需不需要云计算?云计算场景应用大解读 2021-02-01
- 外贸网站该如何为自己的业务选择一个好的域名? 2021-02-01
- 企业网站SEO这样优化效果惊人 2021-02-01
- 小程序对传统行业有哪些作用 2021-02-01
- 要怎样设计网站的页脚 2021-02-01
- 企业使用云服务,安全问题如何保障 2021-02-01