网站数据抓取与页面流量排名深度分析
2022-12-23 分类: 网站建设
从关键词,到内容和页面,完成了需求分析和生产。内容在页面上如何布局,如果处理好内容的结构化,从而更符合搜索引擎的口味,还有很多细致的工作要做,这里不展开。
抓取与收录
搜索结果页是站点之间竞争用户的战场,要想在竞争中获胜,首先你得站到战场上去。根据之前说到的搜索引擎的原理,我们知道,要在搜索结果页中出现,首先生产的页面要被搜索引擎的蜘蛛抓取。蜘蛛发现网页,正常情况下是通过站内的链接,和站外的链接,按照广度优先的原则,提取页面中导出的URL。一般来说,站长还可以通过提交Sitemap,Ping通知蜘蛛,手动提交等方式,帮助蜘蛛发现有效的URL。
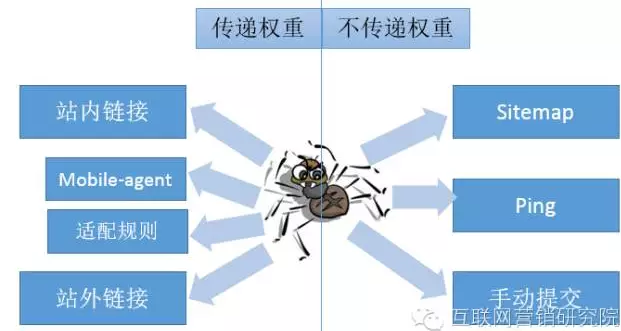
前面说到,通过链接抓取网页,按照广度优先的原则。一般的小站,搜索引擎从起点页抓取三四层的深度也就不错了,一般这个起点页都是网站首页。所以SEO要将网站整体设计成扁平的结构,有些时候需要为蜘蛛搭一些梯子,帮助它在较短路径上接触到更多的URL。举个例子,

一般情况下,一个页面内导出链接不能过多,超过某个值蜘蛛就不抓了。之前的经验是100,但是这个数值还是跟网站和具体页面有关。在网站层级和单页导出链接总量两个约束条件下,还有一点文章可做,那就是时间。单个页面导出链接最多是100,如果我每天换掉其中的50个呢? 一个最简单的实现方式是借助于缓存机制,固定的取50个,另外再在全集中随机取50个,这50个设置缓存时间1天,1天后失效,再随机取50个,这样可以大化导出链接的时效性,就像广告的分时段轮播一样。这里的数字可以根据实效进行调整。站内如此,对于批量交换的外链,也可以按照类似的方式实现。
对于移动页面,有两种主要的机制通知到蜘蛛PC页与移动页的对应关系,一是在PC页头部加上mobile-agent的meta属性,二是在站长工具提交PC/移动页对应关系的正则(也可以提交全量的URL地址对)。
抓取这个环节至关重要,站长平台的抓取频次,和通过accesslog分析得到的抓取明细,都需要时刻监控。小站的log文件,市面上有些一些日志分析工具,自己写也OK。对于大站的log,很多都存储于hadoop这样的分布式存储上,一般需要定制程序去分析处理。为了即时分析处理,快速反馈,可能需要接入流式计算框架。
对于蜘蛛抓取行为数据的使用,可以用来评估蜘蛛对于站内页面价值的评定,可以用来反馈辅助抓取所做的一些优化的效果,可以预估新生成页面被搜索引擎接受的程度,等等。没有使用价值的数据是没用的,数据跟具体的应用场景结合起来,才能体现其价值。
对于抓取的页面,蜘蛛建立倒排索引后,会进行价值判定,按照价值高低,存储在分级索引库中。高级别的索引库才会参与最终的搜索排序。
前段时间,圈子里流出了百度的一个搜索参数,tn=json,以seo这个词为例,查询百度搜索前50条结果,查询URL为,
http://www.baidu.com/s?wd=seo&pn=0&rn=50&tn=json
对于有程序基础的同学们,json格式比网页更易于处理。
这个方法只适用于PC端,对于移动端的收录情况的判断,还是要老老实实的拼接搜索地址URL,解析相应结果文档。
一般SEO开始学的时候,都会接触到site语法,基本上所有常见的搜索引擎也都支持site语法去查询域名或者目录级的收录量查询。在site查询语句的后面加上一个词,可以查询得到该域名与这个词相关的页面。比较有价值的是,site语法查出来的结果,按照网页的价值倒序排列。这个特征便使得依据相关性内链,提升第二页/第三页落地页的排名成为可能。
排名与流量
对于有搜索量的词,获得好的排名,几乎确定了能获得流量。这里说几乎,因为还有一个点展比(点击量除以曝光量)的概念。按照谷歌的规律,PC搜索结果中,前四位获得点击的几率是42%,12%,9%,6%。
先说排名。说到搜索排序,有很多场景下可以用到,比如在搜索结果页中的推广链接区域有个排序;在淘宝里面搜索,商品返回的结果列表有个默认的排序;App Store中搜索也会按照一定的规则返回结果列表;同样的,在广告投放中候选广告创意去竞争一个展示机会时也有一个排序。这些排序与自然搜索的排序有一个共同点,即为了用户体验,将好的,最符合用户需求的排在前面,从而提升用户体验。
影响自然搜索排序的因子应该很多,众所周知的,如网站自身的权威性与价值,网页的导入链接权重,网页结构/速度,网页内容的原创性,以及最重要的,用户搜索词的出现频次,页面Title与H标签中出现搜索词的频次,等等。这是事前的因素。
有一点特别要提及的,搜索引擎为了构建良好的搜索竞争生态,对新站有个补偿机制。这也是实际有效的排序因子。
还有一点事后的因素,获得排名,用户点击,之后是否还点击了别的搜索结果。如果你的页面排在某个词的搜索结果第一位,搜索用户点击了你以后,还总会点击第二位的结果,那显然第二位的结果更符合用户需求,排序如何变化可想而知。这点可以从百度公开的专利中找到依据,点击器也是利用这个原理来实现的。
获得排名的搜索结果,展现给用户的信息包括,页面Title,Description或者页面内提取的信息摘要,缩略图,首页的子链接。后面两者可能有,也可能没有。还有一个相对次要的因素,搜索结果的域名/链接摘要。如何在获得曝光的情况下,吸引用户点击? 除了让自己的排名尽量靠前外,可以做的事情还包括,优化Title/Description的文案,在页面主体区域提供合适尺寸的图片增加被作为缩略图的几率等。搜索结果条目示例如下:
百度自己的产品虽然有被提权的嫌疑,但是从SEO的角度看,仍然有很多值得学习的地方。对于一些如果不确定,可以研究百度自己的产品,看具体的实现方式。
经过了关键词,内容,页面,抓取,索引/收录,排名,流量,这个漫长的链条,我们再回头来看封面上的漏斗模型,可以从中反思,我们的短板在哪里,机会又在哪里。如果将这些数据汇集在一起,随时利用这个数据链去监控网站的SEO状况,利用数据对一些优化操作进行效果监控,甚至通过定义一些自动化的策略,使得系统自己可以实施一些优化操作,并利用数据反馈,再调整,再优化,实现智能优化,真正发挥数据的威力。
网页题目:网站数据抓取与页面流量排名深度分析
当前网址:https://www.cdcxhl.com/news/224904.html
成都网站建设公司_创新互联,为您提供微信公众号、网站建设、外贸网站建设、网站维护、网页设计公司、用户体验
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
猜你还喜欢下面的内容
- 鄞州微信网页开发:在网络教育中,人工智能+教育的缺点是什么 2022-12-23
- 域名为什么每年都要续费?域名到期忘记续费怎么办? 2022-12-23
- 营销网站必须要有有力的行动号召 2022-12-23
- 创新互联的互联网服务有哪些特点? 2022-12-23
- 怎么提高网站的权重?网站SEO主要是从哪些方面做起? 2022-12-23
- 网络营销(网络推广)的前景如何? 2022-12-23
- 网站搭建完成之后如何增加流量 2022-12-23
- 金融营销型企业网站怎么做? 2022-12-23

- 做成都网站建设的一些实用妙招! 2022-12-23
- 成都网站制作公司怎样才能做好一个网站? 2022-12-23
- SEO网站优化的步骤和技巧有哪些? 2022-12-23
- 一份详细的网站SEO优化方案,排名就这么简单 2022-12-23
- 企业怎样认识网络品牌推广 2022-12-23
- 公司新闻,为何网络推广公司技术厂家不给同行做SEO优化 2022-12-23
- Netconcepts:SEO文案撰写规范 2022-12-23
- 成都企业为什么要建网站? 2022-12-23
- 移动端转化效果不好?手机网站占一半责任! 2022-12-23
- 营销型网站的标准是什么? 2022-12-23
- 广州市网站建设的周期大概需要多长时间? 2022-12-23