Redis为什么这么快?
2021-03-18 分类: 网站建设
Redis 是目前最火爆的内存数据库之一,通过在内存中读写数据,大大提高了读写速度,可以说 Redis 是实现网站高并发不可或缺的一部分。
我们使用 Redis 时,会接触 Redis 的 5 种对象类型(字符串、哈希、列表、集合、有序集合),丰富的类型是 Redis 相对于 Memcached 等的一大优势。
在了解 Redis 的 5 种对象类型的用法和特点的基础上,进一步了解 Redis 的内存模型,对 Redis 的使用有很大帮助,例如:
- 估算 Redis 内存使用量。目前为止,内存的使用成本仍然相对较高,使用内存不能无所顾忌;根据需求合理的评估 Redis 的内存使用量,选择合适的机器配置,可以在满足需求的情况下节约成本。
- 优化内存占用。了解 Redis 内存模型可以选择更合适的数据类型和编码,更好的利用 Redis 内存。
- 分析解决问题。当 Redis 出现阻塞、内存占用等问题时,尽快发现导致问题的原因,便于分析解决问题。
这篇文章主要介绍 Redis 的内存模型(以 3.0 为例),包括 Redis 占用内存的情况及如何查询、不同的对象类型在内存中的编码方式、内存分配器(jemalloc)、简单动态字符串(SDS)、RedisObject 等;然后在此基础上介绍几个 Redis 内存模型的应用。
Redis 内存统计
工欲善其事必先利其器,在说明 Redis 内存之前首先说明如何统计 Redis 使用内存的情况。
在客户端通过 redis-cli 连接服务器后(后面如无特殊说明,客户端一律使用redis-cli),通过 info 命令可以查看内存使用情况:info memory。
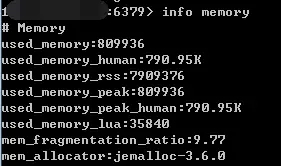
其中,info 命令可以显示 Redis 服务器的许多信息,包括服务器基本信息、CPU、内存、持久化、客户端连接信息等等;Memory 是参数,表示只显示内存相关的信息。
返回结果中比较重要的几个说明如下:
used_memory
Redis 分配器分配的内存总量(单位是字节),包括使用的虚拟内存(即 swap);Redis 分配器后面会介绍。used_memory_human 只是显示更友好。
used_memory_rss
Redis 进程占据操作系统的内存(单位是字节),与 top 及 ps 命令看到的值是一致的。
除了分配器分配的内存之外,used_memory_rss 还包括进程运行本身需要的内存、内存碎片等,但是不包括虚拟内存。
因此,used_memory 和 used_memory_rss,前者是从 Redis 角度得到的量,后者是从操作系统角度得到的量。
二者之所以有所不同,一方面是因为内存碎片和 Redis 进程运行需要占用内存,使得前者可能比后者小,另一方面虚拟内存的存在,使得前者可能比后者大。
由于在实际应用中,Redis 的数据量会比较大,此时进程运行占用的内存与 Redis 数据量和内存碎片相比,都会小得多。
因此 used_memory_rss 和 used_memory 的比例,便成了衡量 Redis 内存碎片率的参数;这个参数就是 mem_fragmentation_ratio。
mem_fragmentation_ratio
内存碎片比率,该值是 used_memory_rss / used_memory 的比值。
mem_fragmentation_ratio 一般大于 1,且该值越大,内存碎片比例越大;mem_fragmentation_ratio<1,说明 Redis 使用了虚拟内存,由于虚拟内存的媒介是磁盘,比内存速度要慢很多。
当这种情况出现时,应该及时排查,如果内存不足应该及时处理,如增加 Redis 节点、增加 Redis 服务器的内存、优化应用等。
一般来说,mem_fragmentation_ratio 在 1.03 左右是比较健康的状态(对于 jemalloc 来说)。
上面截图中的 mem_fragmentation_ratio 值很大,是因为还没有向 Redis 中存入数据,Redis 进程本身运行的内存使得 used_memory_rss 比 used_memory 大得多。
mem_allocator
Redis 使用的内存分配器,在编译时指定;可以是 libc 、jemalloc 或者 tcmalloc,默认是 jemalloc;截图中使用的便是默认的 jemalloc。
Redis 内存划分
Redis 作为内存数据库,在内存中存储的内容主要是数据(键值对);通过前面的叙述可以知道,除了数据以外,Redis 的其他部分也会占用内存。
Redis 的内存占用主要可以划分为以下几个部分:
数据
作为数据库,数据是最主要的部分;这部分占用的内存会统计在 used_memory 中。
Redis 使用键值对存储数据,其中的值(对象)包括 5 种类型,即字符串、哈希、列表、集合、有序集合。
这 5 种类型是 Redis 对外提供的,实际上,在 Redis 内部,每种类型可能有 2 种或更多的内部编码实现。
此外,Redis 在存储对象时,并不是直接将数据扔进内存,而是会对对象进行各种包装:如 RedisObject、SDS 等;这篇文章后面将重点介绍 Redis 中数据存储的细节。
进程本身运行需要的内存
Redis 主进程本身运行肯定需要占用内存,如代码、常量池等等;这部分内存大约几兆,在大多数生产环境中与 Redis 数据占用的内存相比可以忽略。
这部分内存不是由 jemalloc 分配,因此不会统计在 used_memory 中。
补充说明:除了主进程外,Redis 创建的子进程运行也会占用内存,如 Redis 执行 AOF、RDB 重写时创建的子进程。
当然,这部分内存不属于 Redis 进程,也不会统计在 used_memory 和 used_memory_rss 中。
缓冲内存
缓冲内存包括客户端缓冲区、复制积压缓冲区、AOF 缓冲区等;其中,客户端缓冲区存储客户端连接的输入输出缓冲;复制积压缓冲区用于部分复制功能;AOF 缓冲区用于在进行 AOF 重写时,保存最近的写入命令。
在了解相应功能之前,不需要知道这些缓冲的细节;这部分内存由 jemalloc 分配,因此会统计在 used_memory 中。
内存碎片
内存碎片是 Redis 在分配、回收物理内存过程中产生的。例如,如果对数据的更改频繁,而且数据之间的大小相差很大,可能导致 Redis 释放的空间在物理内存中并没有释放。
但 Redis 又无法有效利用,这就形成了内存碎片,内存碎片不会统计在 used_memory 中。
内存碎片的产生与对数据进行的操作、数据的特点等都有关;此外,与使用的内存分配器也有关系:如果内存分配器设计合理,可以尽可能的减少内存碎片的产生。后面将要说到的 jemalloc 便在控制内存碎片方面做的很好。
如果 Redis 服务器中的内存碎片已经很大,可以通过安全重启的方式减小内存碎片:因为重启之后,Redis 重新从备份文件中读取数据,在内存中进行重排,为每个数据重新选择合适的内存单元,减小内存碎片。
Redis 数据存储的细节
关于 Redis 数据存储的细节,涉及到内存分配器(如 jemalloc)、简单动态字符串(SDS)、5 种对象类型及内部编码、RedisObject。在讲述具体内容之前,先说明一下这几个概念之间的关系。
下图是执行 set hello world 时,所涉及到的数据模型:
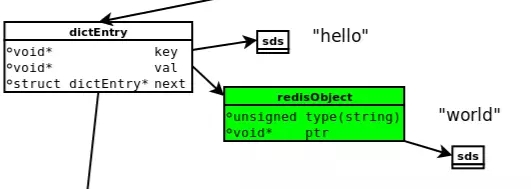
dictEntry:Redis 是 Key-Value 数据库,因此对每个键值对都会有一个 dictEntry,里面存储了指向 Key 和 Value 的指针;next 指向下一个 dictEntry,与本 Key-Value 无关。
Key:图中右上角可见,Key(”hello”)并不是直接以字符串存储,而是存储在 SDS 结构中。
RedisObject:Value(“world”)既不是直接以字符串存储,也不是像 Key 一样直接存储在 SDS 中,而是存储在 RedisObject 中。
实际上,不论 Value 是 5 种类型的哪一种,都是通过 RedisObject 来存储的;而 RedisObject 中的 type 字段指明了 Value 对象的类型,ptr 字段则指向对象所在的地址。
不过可以看出,字符串对象虽然经过了 RedisObject 的包装,但仍然需要通过 SDS 存储。
实际上,RedisObject 除了 type 和 ptr 字段以外,还有其他字段图中没有给出,如用于指定对象内部编码的字段。
jemalloc:无论是 DictEntry 对象,还是 RedisObject、SDS 对象,都需要内存分配器(如 jemalloc)分配内存进行存储。
以 DictEntry 对象为例,有 3 个指针组成,在 64 位机器下占 24 个字节,jemalloc 会为它分配 32 字节大小的内存单元。
下面来分别介绍 jemalloc、RedisObject、SDS、对象类型及内部编码。
jemalloc
Redis 在编译时便会指定内存分配器;内存分配器可以是 libc 、jemalloc 或者 tcmalloc,默认是 jemalloc。
jemalloc 作为 Redis 的默认内存分配器,在减小内存碎片方面做的相对比较好。
jemalloc 在 64 位系统中,将内存空间划分为小、大、巨大三个范围;每个范围内又划分了许多小的内存块单位;当 Redis 存储数据时,会选择大小最合适的内存块进行存储。
jemalloc 划分的内存单元如下图所示:
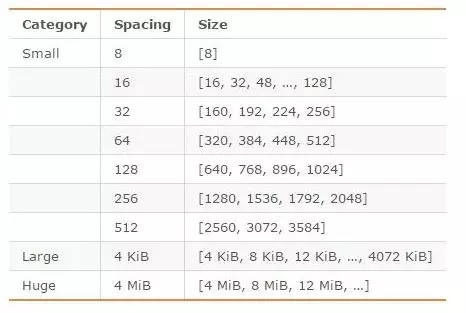
例如,如果需要存储大小为 130 字节的对象,jemalloc 会将其放入 160 字节的内存单元中。
RedisObject
前面说到,Redis 对象有 5 种类型;无论是哪种类型,Redis 都不会直接存储,而是通过 RedisObject 对象进行存储。
RedisObject 对象非常重要,Redis 对象的类型、内部编码、内存回收、共享对象等功能,都需要 RedisObject 支持,下面将通过 RedisObject 的结构来说明它是如何起作用的。
RedisObject 的定义如下(不同版本的 Redis 可能稍稍有所不同):
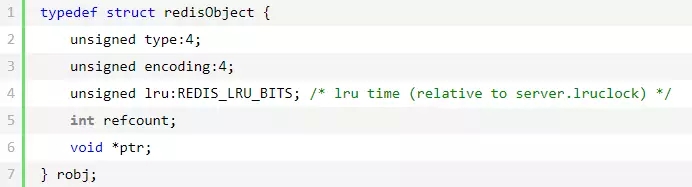
RedisObject 的每个字段的含义和作用如下:
type
type 字段表示对象的类型,占 4 个比特;目前包括 REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
当我们执行 type 命令时,便是通过读取 RedisObject 的 type 字段获得对象的类型;如下图所示:
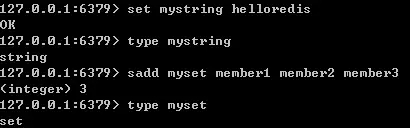
encoding
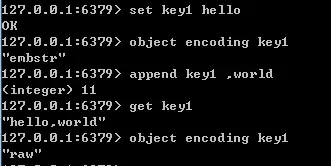
encoding 表示对象的内部编码,占 4 个比特。对于 Redis 支持的每种类型,都有至少两种内部编码,例如对于字符串,有 int、embstr、raw 三种编码。
通过 encoding 属性,Redis 可以根据不同的使用场景来为对象设置不同的编码,大大提高了 Redis 的灵活性和效率。
以列表对象为例,有压缩列表和双端链表两种编码方式;如果列表中的元素较少,Redis 倾向于使用压缩列表进行存储,因为压缩列表占用内存更少,而且比双端链表可以更快载入。
当列表对象元素较多时,压缩列表就会转化为更适合存储大量元素的双端链表。
通过 object encoding 命令,可以查看对象采用的编码方式,如下图所示:
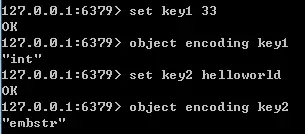
5 种对象类型对应的编码方式以及使用条件,将在后面介绍。
lru
lru 记录的是对象最后一次被命令程序访问的时间,占据的比特数不同的版本有所不同(如 4.0 版本占 24 比特,2.6 版本占 22 比特)。
通过对比 lru 时间与当前时间,可以计算某个对象的空转时间;object idletime 命令可以显示该空转时间(单位是秒)。object idletime 命令的一个特殊之处在于它不改变对象的 lru 值。
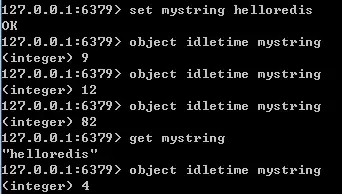
lru 值除了通过 object idletime 命令打印之外,还与 Redis 的内存回收有关系。
如果 Redis 打开了 maxmemory 选项,且内存回收算法选择的是 volatile-lru 或 allkeys—lru,那么当 Redis 内存占用超过 maxmemory 指定的值时,Redis 会优先选择空转时间最长的对象进行释放。
refcount
refcount 与共享对象:refcount 记录的是该对象被引用的次数,类型为整型。refcount 的作用,主要在于对象的引用计数和内存回收。
当创建新对象时,refcount 初始化为 1;当有新程序使用该对象时,refcount 加 1;当对象不再被一个新程序使用时,refcount 减 1;当 refcount 变为 0 时,对象占用的内存会被释放。
Redis 中被多次使用的对象(refcount>1),称为共享对象。Redis 为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。
这个被重复使用的对象,就是共享对象。目前共享对象仅支持整数值的字符串对象。
共享对象的具体实现:Redis 的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和 CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。
对于整数值,判断操作复杂度为 O(1);对于普通字符串,判断复杂度为 O(n);而对于哈希、列表、集合和有序集合,判断的复杂度为 O(n^2)。
虽然共享对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象(如哈希、列表等的元素可以使用)。
就目前的实现来说,Redis 服务器在初始化时,会创建 10000 个字符串对象,值分别是 0~9999 的整数值;当 Redis 需要使用值为 0~9999 的字符串对象时,可以直接使用这些共享对象。
10000 这个数字可以通过调整参数 REDIS_SHARED_INTEGERS(4.0 中是 OBJ_SHARED_INTEGERS)的值进行改变。
共享对象的引用次数可以通过 object refcount 命令查看,如下图所示。命令执行的结果页佐证了只有 0~9999 之间的整数会作为共享对象。
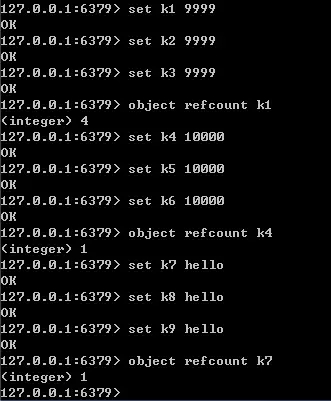
ptr
ptr 指针指向具体的数据,如前面的例子中,set hello world,ptr 指向包含字符串 world 的 SDS。
综上所述,RedisObject 的结构与对象类型、编码、内存回收、共享对象都有关系。
一个 RedisObject 对象的大小为 16 字节:4bit+4bit+24bit+4Byte+8Byte=16Byte。
SDS
Redis 没有直接使用 C 字符串(即以空字符’\0’结尾的字符数组)作为默认的字符串表示,而是使用了 SDS。SDS 是简单动态字符串(Simple Dynamic String)的缩写。
SDS 结构
SDS 的结构如下:
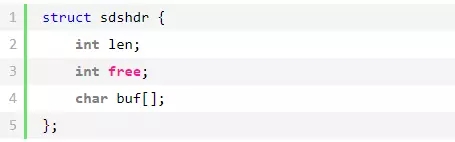
其中,buf 表示字节数组,用来存储字符串;len 表示 buf 已使用的长度;free 表示 buf 未使用的长度。
下面是两个例子:

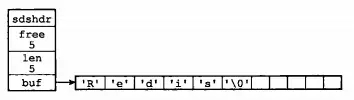
通过 SDS 的结构可以看出,buf 数组的长度=free+len+1(其中 1 表示字符串结尾的空字符)。
所以,一个 SDS 结构占据的空间为:free 所占长度+len 所占长度+ buf 数组的长度=4+4+free+len+1=free+len+9。
SDS 与 C 字符串的比较
SDS 在 C 字符串的基础上加入了 free 和 len 字段,带来了很多好处:
获取字符串长度:SDS 是 O(1),C 字符串是 O(n)。
缓冲区溢出:使用 C 字符串的 API 时,如果字符串长度增加(如 strcat 操作)而忘记重新分配内存,很容易造成缓冲区的溢出。
而 SDS 由于记录了长度,相应的 API 在可能造成缓冲区溢出时会自动重新分配内存,杜绝了缓冲区溢出。
修改字符串时内存的重分配:对于 C 字符串,如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。
而对于 SDS,由于可以记录 len 和 free,因此解除了字符串长度和空间数组长度之间的关联,可以在此基础上进行优化。
空间预分配策略(即分配内存时比实际需要的多)使得字符串长度增大时重新分配内存的概率大大减小;惰性空间释放策略使得字符串长度减小时重新分配内存的概率大大减小。
存取二进制数据:SDS 可以,C 字符串不可以。因为 C 字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等)。
内容可能包括空字符串,因此 C 字符串无法正确存取;而 SDS 以字符串长度 len 来作为字符串结束标识,因此没有这个问题。
此外,由于 SDS 中的 buf 仍然使用了 C 字符串(即以’\0’结尾),因此 SDS 可以使用 C 字符串库中的部分函数。
但是需要注意的是,只有当 SDS 用来存储文本数据时才可以这样使用,在存储二进制数据时则不行(’\0’不一定是结尾)。
SDS 与 C 字符串的应用
Redis 在存储对象时,一律使用 SDS 代替 C 字符串。例如 set hello world 命令,hello 和 world 都是以 SDS 的形式存储的。
而 sadd myset member1 member2 member3 命令,不论是键(“myset”),还是集合中的元素(“member1”、 “member2”和“member3”),都是以 SDS 的形式存储。
除了存储对象,SDS 还用于存储各种缓冲区。只有在字符串不会改变的情况下,如打印日志时,才会使用 C 字符串。
Redis 的对象类型与内部编码
前面已经说过,Redis 支持 5 种对象类型,而每种结构都有至少两种编码。
这样做的好处在于:一方面接口与实现分离,当需要增加或改变内部编码时,用户使用不受影响,另一方面可以根据不同的应用场景切换内部编码,提高效率。
Redis 各种对象类型支持的内部编码如下图所示(图中版本是 Redis3.0,Redis 后面版本中又增加了内部编码,略过不提;本章所介绍的内部编码都是基于 3.0 的):
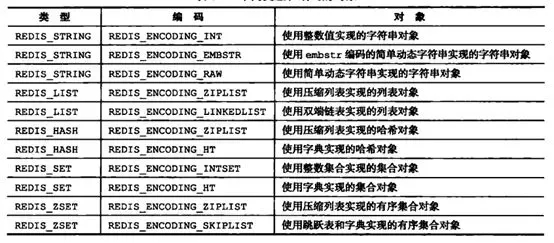
关于 Redis 内部编码的转换,都符合以下规律:编码转换在 Redis 写入数据时完成,且转换过程不可逆,只能从小内存编码向大内存编码转换。
字符串
字符串是最基础的类型,因为所有的键都是字符串类型,且字符串之外的其他几种复杂类型的元素也是字符串,字符串长度不能超过 512MB。
内部编码
字符串类型的内部编码有 3 种,它们的应用场景如下:
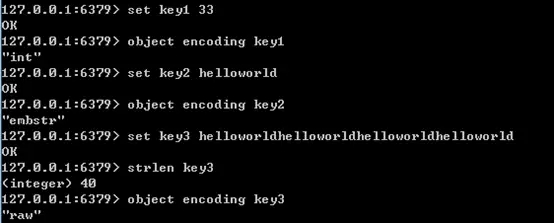
int:8 个字节的长整型。字符串值是整型时,这个值使用 long 整型表示。
embstr:<=39 字节的字符串。embstr 与 raw 都使用 RedisObject 和 sds 保存数据。
区别在于:embstr 的使用只分配一次内存空间(因此 RedisObject 和 sds 是连续的),而 raw 需要分配两次内存空间(分别为 RedisObject 和 sds 分配空间)。
因此与 raw 相比,embstr 的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。
而 embstr 的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个 RedisObject 和 sds 都需要重新分配空间,因此 Redis 中的 embstr 实现为只读。
raw:大于 39 个字节的字符串。
示例如下图所示:
embstr 和 raw 进行区分的长度,是 39;是因为 RedisObject 的长度是 16 字节,sds 的长度是 9+ 字符串长度。
因此当字符串长度是 39 时,embstr 的长度正好是 16+9+39=64,jemalloc 正好可以分配 64 字节的内存单元。
编码转换
当 int 数据不再是整数,或大小超过了 long 的范围时,自动转化为 raw。
而对于 embstr,由于其实现是只读的,因此在对 embstr 对象进行修改时,都会先转化为 raw 再进行修改。
因此,只要是修改 embstr 对象,修改后的对象一定是 raw 的,无论是否达到了 39 个字节。
示例如下图所示:
列表
列表(list)用来存储多个有序的字符串,每个字符串称为元素;一个列表可以存储 2^32-1 个元素。
Redis 中的列表支持两端插入和弹出,并可以获得指定位置(或范围)的元素,可以充当数组、队列、栈等。
内部编码
列表的内部编码可以是压缩列表(ziplist)或双端链表(linkedlist)。
双端链表:由一个 list 结构和多个 listNode 结构组成;典型结构如下图所示:
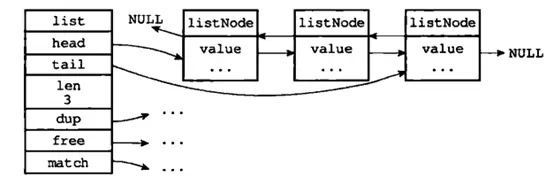
通过图中可以看出,双端链表同时保存了表头指针和表尾指针,并且每个节点都有指向前和指向后的指针。
链表中保存了列表的长度;dup、free 和 match 为节点值设置类型特定函数。
所以链表可以用于保存各种不同类型的值,而链表中每个节点指向的是type为字符串的 RedisObject。
压缩列表:压缩列表是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块(而不是像双端链表一样每
当前题目:Redis为什么这么快?
网页路径:https://www.cdcxhl.com/news/105388.html
成都网站建设公司_创新互联,为您提供定制网站、软件开发、网页设计公司、微信小程序、Google、关键词优化
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
猜你还喜欢下面的内容
- 【故障分析】apache启动失败 2021-03-18
- 托管服务器有哪些优势? 2021-03-18
- RAID3和RAID5的区别,RAID5数据恢复方法 2021-03-17
- 常用的虚拟机软件 2021-03-17
- 企业或个人备案都需要准备什么? 2021-03-17
- 双线服务器响应的不同类型 2021-03-17
- vmware tools 安装失败的原因 2021-03-17

- 数据误删,如何恢复服务器数据 2021-03-18
- 如何成为一名懒惰的系统管理员 2021-03-18
- 如何杀死僵尸进程? 2021-03-18
- 【教程】如何使用ScheduledExecutorService? 2021-03-18
- 如何使用代理服务器上网? 2021-03-17
- 如何选择服务器提供商? 2021-03-17
- 代理服务器的作用是什么,有什么用? 2021-03-17
- 中科曙光液冷服务器实现大规模部署 2021-03-17
- 如何清除DNS服务器缓存 2021-03-17
- 【已解决】IBM X3250 M4部署RID失败 2021-03-17
- DDOS攻击的原理 2021-03-17
- 小微企业如何借助nas服务器建立数据中心? 2021-03-17