搜索引擎抓取收录的基本原理的研究分析
古语云,“知己知彼百战不殆”,这句流传千古的兵家箴言至今教导着我们,作为一个合格的SEOer或个人站长,不了解搜索引擎蜘蛛抓取收录显然out了。今天,小编就和大家一起来探讨—搜索引擎蜘蛛抓取收录的基本原理。
创新互联公司-专业网站定制、快速模板网站建设、高性价比香坊网站开发、企业建站全套包干低至880元,成熟完善的模板库,直接使用。一站式香坊网站制作公司更省心,省钱,快速模板网站建设找我们,业务覆盖香坊地区。费用合理售后完善,十多年实体公司更值得信赖。
工具/原料
1、搜索引擎爬虫(别名:搜索引擎蜘蛛)
2、网页
方法/步骤
1、什么是搜索引擎蜘蛛?
搜索引擎蜘蛛,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚本。由于互联网具有四通八达的“拓补结构”十分类似蜘蛛网,再加上搜索引擎爬虫无休止的在互联网上“爬行”,因此人家形象的将搜索引擎爬虫称之为蜘蛛。
2、互联网储备了丰富的资源和数据,那么这些资源数据是怎么来的呢?众所周知,搜索引擎不会自己产生内容,借助蜘蛛不间断的从千千万万的网站上面“搜集”网页数据来“填充”自有的页面数据库。这也就是为什么我们使用搜索引擎检索数据时,能够获得大量的匹配资源。
说了这么多,不如贴一张图来的实在。下图是搜索引擎抓取收录的基本原理图:
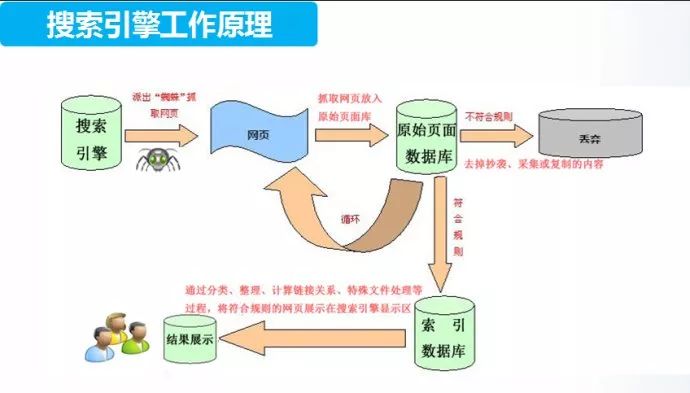
大体工作流程如下:
①搜索引擎安排蜘蛛到互联网上的网站去抓取网页数据,然后将抓取的数据带回搜索引擎的原始页面数据库中。蜘蛛抓取页面数据的过程是无限循环的,只有这样我们搜索出来的结果才是不断更新的。
②原始页面数据库中的数据并不是最终的结果,只是相当于过了面试的“初试”,搜索引擎会将这些数据进行“二次处理”,这个过程中会有两个处理结果:
(1)对那些抄袭、采集或者复制的重复内容,不符合搜索引擎规则及不满足用户体验的垃圾页面从原始页面数据库中清除。
(2)将符合搜索引擎规则的高质量页面添加到索引数据库中,等待进一步的分类、整理等工作。
③搜索引擎对索引数据库中的数据进行分类、整理、计算链接关系、特殊文件处理等过程,将符合规则的网页展示在搜索引擎显示区,以供用户使用和查看。
网站标题:搜索引擎抓取收录的基本原理的研究分析
浏览地址:https://www.cdcxhl.com/article8/scdiip.html
成都网站建设公司_创新互联,为您提供搜索引擎优化、Google、网站建设、ChatGPT、网站设计、用户体验
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 定制营销型网站建设细节要点 2016-04-14
- 成都营销型网站建设找哪家? 2022-08-11
- 创新互联:如何策划企业全网营销型网站建设的方案 2022-11-10
- 营销型网站建设怎样在细节中取胜 2022-05-23
- 佛山营销型网站建设公司哪家好 2022-11-13
- 营销型网站建设基本流程 2022-07-14
- 外贸企业营销型网站建设要求 2016-10-17
- 优质营销型网站建设对企业的影响力 2022-10-24
- 营销型网站建设开发需要多少成本? 2023-02-20
- 浅析营销型网站建设与响应式网站建设有什么区别? 2016-10-27
- 成功的营销型网站建设设计与哪些因素有关? 2015-06-22
- 营销型网站建设的重点应放在哪些方面呢 2021-11-04