Shuffle原理及对应的Consolidation优化机制是怎样的
这篇文章给大家介绍Shuffle原理及对应的Consolidation优化机制是怎样的,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
网站设计制作过程拒绝使用模板建站;使用PHP+MYSQL原生开发可交付网站源代码;符合网站优化排名的后台管理系统;成都网站设计、网站建设收费合理;免费进行网站备案等企业网站建设一条龙服务.我们是一家持续稳定运营了10年的创新互联网站建设公司。
一、什么是Shuffle?
Shuffle是连接MapTask和ReduceTask过程的桥梁,MapTask的输出必须要经过Shuffle过程才能变成ReduceTask的输入,在分布式集群中,ReduceTask需要跨节点去拉取MapTask的输出结果,这中间涉及到数据的网络传输和磁盘IO,所以Shuffle的好坏将直接影响整个应用程序的性能,通常我们将Shuffle过程分成两部分:MapTask端的结果输出成为ShuffleWrite,ReduceTask端的数据拉取称为ShuffleRead。
Spark 的 Shuffle 过程与MapReduce的 Shuffle 过程原理基本相似,一些概念可直接套用,例如,Shuffle 过程中,提供数据的一端,被称作 Map 端,Map 端每个生成数据的任务称为 Mapper,对应的,接收数据的一端,被称作 Reduce 端,Reduce 端每个拉取数据的任务称为 Reducer,Shuffle 过程本质上都是将 Map 端获得的数据使用分区器进行划分,并将数据发送给对应的 Reducer 的过程。
前面的文章我们已经讲过了Spark任务中Stage的划分依据是RDD的宽窄依赖;在窄依赖中父RDD和子RDD partition之间的关系是一对一的。或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的。不会有shuffle的产生。父RDD的一个分区去到子RDD的一个分区。而在宽依赖中,父RDD与子RDD partition之间的关系是一对多。会有shuffle的产生。父RDD的一个分区的数据去到子RDD的不同分区里面。
在现实场景中,百分之九十的调优情况都是发生在shuffle阶段,所以此类调优非常重要。
二、普通的Spark HashShuffle原理
这里先看一张图,普通的Shuffle原理是怎么样的运行的,下面我会结合这个图给大家讲解基本的Shuffle原理:
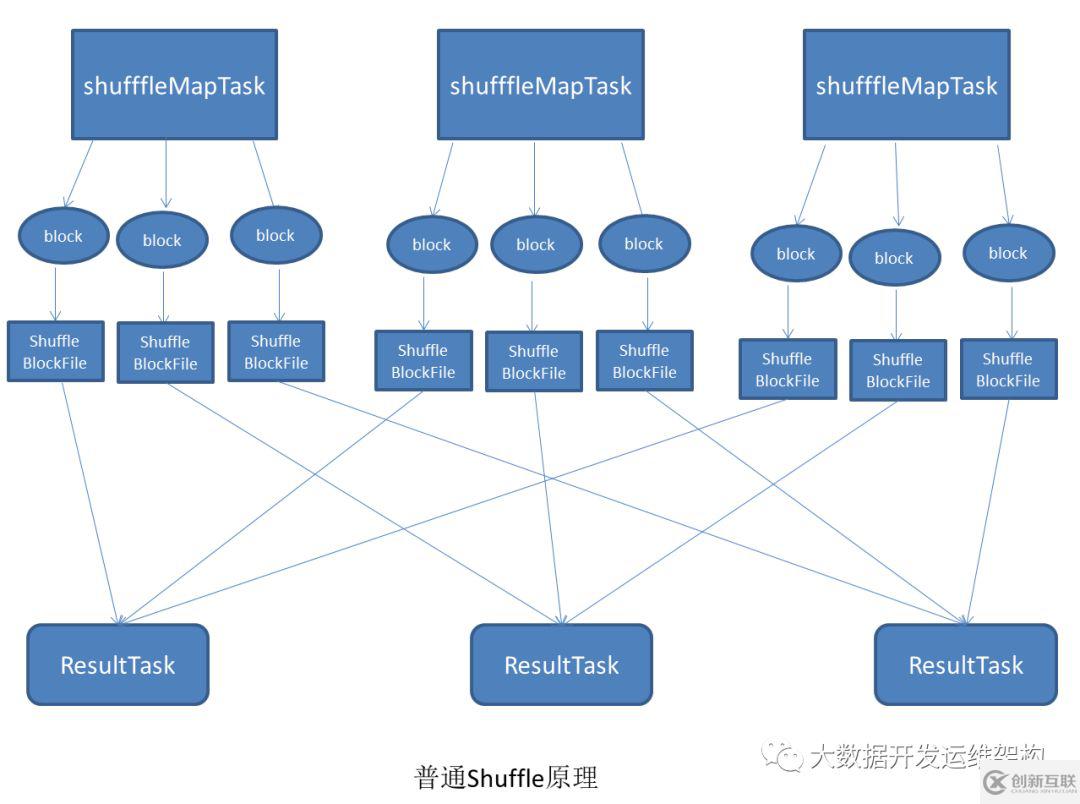
普通Shuffle执行过程:
1.上面有三个ShuffleMapTask和两个ResultTask,ShuffleMapTask会根据ResultTask的数量创建出相应的bucket,bucket的数量是3×3。
2. 其次ShuffleMapTask产生的结果会根据设置的partition算法填充到每个bucket中去。这里的partition算法是可以自定义的,当然默认的算法是根据key哈希到不同的bucket中去,最后落地的话就是ShuffleBlockFIle。
3.ShuffleMapTask的输出的ShuffleBlockFIle位置信息作作为MapStatus发送到DAGScheduler的MapOutputTracker的Master中。
3.当ShuffleMapTask启动时,它会根据自己task的id和所依赖的ShuffleMapTask的id,然后去MapOutputTracker中读取ShuffleBlockFIle位置信息,最后从远端或是本地的blockmanager中取得相应的ShuffleBlockFIle作为ResultTask的输入进行处理。
如果ShuffleMapTask和ResultTask数量过多就会产生N*N的小文件,导致ShuffleWrite要耗费大量性能在磁盘文件的创建以及磁盘的IO上,给系统造成很大压力,上面我画的图有点不太好,这里我文字表述下:
一种情形A: 如果有4个ShuffleMapTask和4个ResultTask,我的机器只有2个cpu核数,而每个task默认是需要一个cpu来运行的,这样我的4个ShuffleMapTask就分了两个批次运行,同时只有两个Task运行,第一批Task会生成2*4个ShuffleBlockFIle文件,第二批Task运行仍然会生成2*4的ShuffleBlockFIle文件,这样会产生16个小文件。
另一种情形B:我还是有4个ShuffleMapTask和4个ResultTask,我的机器只有4个cpu或者更多的cpu核数,我的4个ShuffleMapTask就会在同一个批次运行,还是会产生4*4=16个小文件。
存在的问题:
1.Shuffle前在磁盘上会产生海量的小文件,分布式模式ResultTask去拉取数据时,会产生大量会有过多的小文件创建和磁盘IO操作。
2.可能导致OOM,大量耗时低效的 IO 操作 ,导致写磁盘时的对象过多,读磁盘时候的对象也过多,这些对象存储在堆内存中,会导致堆内存不足,相应会导致频繁的GC,GC会导致OOM。由于内存中需要保存海量文件操作句柄和临时信息,如果数据处理的规模比较庞大的话,内存不可承受,会出现 OOM 等问题。
二、开启Consolidation机制的Spark HashShuffle原理
鉴于上面基本Shuffle存在的不足, 在后面的Spark0.81版本开始就引入了Consolidation机制,由参数spark.shuffle.consolidateFiles控制。将其设置为true即可开启优化机制,下面我们就看下优化后的Shuffle是如何处理的:
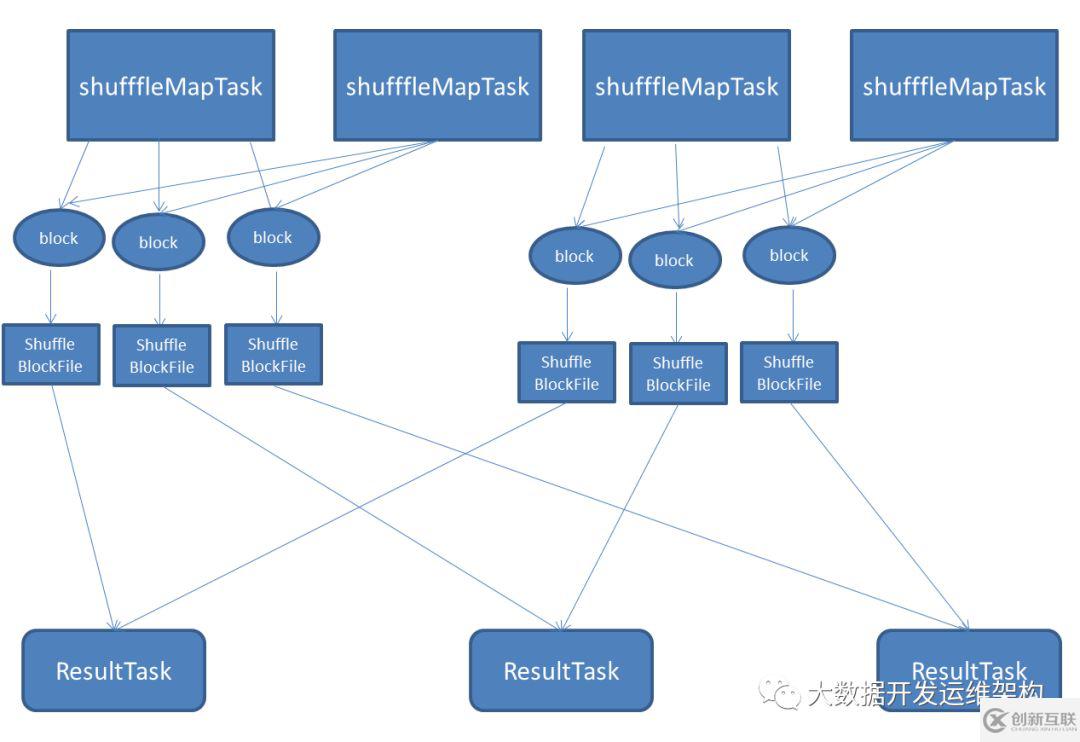
优化的Shuffle原理:
相当于对于上面的“情形B”做了优化,把在同一core上运行的多个ShuffleMapTask输出的合并到同一个文件,这样文件数目就变成了 cores*ResultTask个ShuffleBlockFile文件了,这里一定要注意同一个批次运行的ShuffleMapTask一定是写的不同的文件,只有不同批次的ShuffleMapTask才会写相同的文件,当第一批ShuffleMapTask运行完成后,后面在同一个cpu core上运行的TShuffleMapTask才会去写上一个在这个cpu core上运行ShuffleMapTask写的那个ShuffleBlockFile文件。
至此Spark HashShuffle原理及其Consolidation机制讲解完毕,但是如果 Reducer 端的并行任务或者是数据分片过多的话则 Core * Reducer Task 依旧过大,也会产生很多小文件。
上面的原理都是基于的HashShuffleManager。而Spark1.2.x以后,HashShuffleManager不再是Spark默认的Shuffle Manager,Spark1.2.x以后,Spark默认的Shuffle Manager是SortShuffleManager。在Spark2.0以后 HashShuffleManager已经被弃用。
关于Shuffle原理及对应的Consolidation优化机制是怎样的就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
网站题目:Shuffle原理及对应的Consolidation优化机制是怎样的
URL分享:https://www.cdcxhl.com/article8/ijjhop.html
成都网站建设公司_创新互联,为您提供服务器托管、自适应网站、网站内链、虚拟主机、品牌网站制作、网站改版
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 网站推广中新闻动态网络爬虫扫描 2016-10-29
- 动态网页的工作方式 2016-11-09
- 什么叫动态网站,是不是网站上有会动的东西就是动态呀? 2015-04-21
- 百度快照推广关于静态网站优于动态网站做seo优化的正确表明 2023-01-17
- 成都SEO优化:动态URL和静态URL那种更利于网站优 2016-11-14
- 什么是动态网站建设 2016-11-04
- 浅谈关于网站的动态URL和静态URL 2014-03-13
- seo技术要学什么?及时了解动态很重要。 2017-09-02
- 动态网站与静态网站哪种有助于排名 2016-11-11
- 无论静态还是动态网站建设开发应该满足实际需求 2022-05-15
- 动态网站开发的特点有哪些? 2019-03-10
- 为什么静态/伪静态网页比动态网页好做优化?介 2014-02-04