lucene倒排索引的存储方式介绍
这篇文章主要讲解了“lucene倒排索引的存储方式介绍”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“lucene倒排索引的存储方式介绍”吧!
创新互联是一家专业提供浈江企业网站建设,专注与成都做网站、成都网站制作、H5开发、小程序制作等业务。10年已为浈江众多企业、政府机构等服务。创新互联专业网站建设公司优惠进行中。
在谈谈lucene倒排索引的存储方式中只说明了倒排索引位置相关信息的存储,并没有详细说明如果需要对位置信息进行随机访问,那么它的索引该如何设计。lucene采用的是多级跳跃链表的方式,先说说跳跃链表基本思想(其实在前面文中也提过),假设给定一堆排过序的数字,并且数据量很大以至于在内存中放不下,如果要快速随机访问其中的某个数值,一种方法是对这些数字每隔一定的条数如1000条就记录相应的数值以及对应的文件指针,然后把这些数值以及对应的文件指针加载到内存中采用二分查找法找到欲查找数值所在数据块的起始地址,然后将1000条记录依次遍历比较或者加载到内存中采用二分查找都可以,这些数值和文件指针又叫一级跳跃表。
如果说一级跳跃表的数据量依然很大,那么又要在此基础上再建立一层跳跃表,依此类推就会有多级跳跃表了。值得一提的是级数并不是越多越好,因为层级越多,查找的次数也越多,lucene默认最大层级为10。
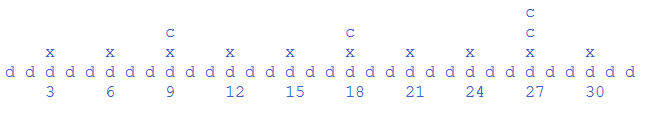
上图是lucene官方给出的示图(一个词代表的倒排位置索引),d代表文档,x代表每隔128个文档进行压缩的文件指针也是第一层级的索引记录了相应的文档ID和所在文件的指针,c分别为第二层级和第三层级。这样感觉在代码实现上较复杂的索引结构确在lucene实现的时候显得非常讨巧,因为总的层级可以预先算出来,然后可以边写边计算出文档所在层级。有兴趣滴还是看代码吧。
感谢各位的阅读,以上就是“lucene倒排索引的存储方式介绍”的内容了,经过本文的学习后,相信大家对lucene倒排索引的存储方式介绍这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是创新互联,小编将为大家推送更多相关知识点的文章,欢迎关注!
分享文章:lucene倒排索引的存储方式介绍
当前URL:https://www.cdcxhl.com/article8/gheiip.html
成都网站建设公司_创新互联,为您提供做网站、面包屑导航、手机网站建设、移动网站建设、微信小程序、定制网站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- ChatGPT是什么?ChatGPT是聊天机器人吗? 2023-05-05
- 爆红的ChatGPT,谁会丢掉饭碗? 2023-02-20
- 马云回国,首谈ChatGPT。又是新一个风口? 2023-05-28
- 火爆的ChatGPT,来聊聊它的热门话题 2023-02-20
- 怎样利用chatGPT快速赚钱? 2023-05-05
- ChatGPT的应用ChatGPT对社会的利弊影响 2023-02-20
- ChatGPT的发展历程 2023-02-20
- ChatGPT是什么 2023-02-20