SparkWordCount案例-创新互联
- Spark WordCount 案例
- 1、程序连接 Spark
- 2、WordCount 案例示例
- 3、复杂版 WordCount
- 4、Spark 框架Wordcount

首先这个Scala spark程序和spark的链接,跟sql编程类似。首先new 一个新的val context = SparkContext()对象,然后还要用到val conf = SparkConf.setMaster("local").setAppName("WordCount")这个是配置信息,比如这个是本地连接所以里面是local,然后后面那个是程序的名字,这个写完之后,吧这个conf对象放在SparkContext(conf)这里面。然后在程序的最后,用完了要关闭连接,context.stop(),使用stop方法关闭
先在D盘,把要测试的文件数据准备好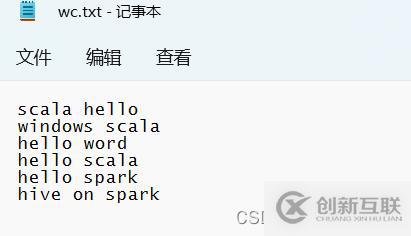
思路:首先连接之后,第一步是读取文件,使用textFile()方法,里面的参数是要读取的文件的路径,然后把文件一行一行的读取出来。第二步是使用flatMap(_.split(" "))方法,进行map映射和扁平化,把单词按照空格分割开。第三步是groupBy(word =>word)按照单词进行分组,一样的单词分到一组。第四步map()映射进行模式匹配,取去key和他的集合的size也就是单词出现的次数。然后使用collect()方法将结果采集打印,最后使用foreach(println)进行遍历。
package com.atguigu.bigdata.spark.core.wc
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class spark01_WordCount {}
object spark01_WordCount{def main(args: Array[String]): Unit = {// Application 我们自己写的应用程序
// Spark 框架
//用我们的应用程序去连接spark 就跟那个sql 编程一样
//TODD建立和Spark 框架的连接
//1、Java里面是Conntection 进行连接
//2、Scala 里有个类似的,SparkContext()
//2.1 SparkConf()配置不然不晓得连的哪个. setMaster() 里面是本地连接,setAppName() 里面是app的名称
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val context = new SparkContext(sparkConf)
println(context)
//TODD 执行业务操作
//1、读取文件,获取一行一行的数据 这一步是扁平化
//hello word
val value = context.textFile("D:\\wc.txt") //textFile 可以吧文件一行一行的读出来
//2、将数据进行拆分,形成一个一个的单词
//扁平化:将整体拆分为个体的操作
//"hello word" =>hello,word
val danci: RDD[String] = value.flatMap(a =>a.split(" ")) //根据空格进行拆分
//3、将数据根据单词进行分组,便于统计
//(hello,hello,hello,hello,hello),(word,word,word) 这个样子的
//按照单词进行分组
val wordGroup = danci.groupBy(word =>word) //按照单词进行分组
//4、对分组数的数据进行转换
//(hello,hello,hello,hello,hello),(word,word,word)
//(hello,5),(word,3)
val wordToCount = wordGroup.map{//模式匹配
case (word,list) =>{(word,list.size) //匹配,第一个是单词。第二个是长度,这个长度就是单词出现的次数
}
}
//5、将转换结果采集到控制台打印出来
val tuples = wordToCount.collect() //collect()方法,将结果采集打印
tuples.foreach(println)
//TODD 关闭连接
context.stop() //这样就关闭连接了
}
}因为之前那个是用size方法得到次数,但是这样就不像是一个聚合操作,所以使用map映射,然后使用reduce 进行聚合操作,这样来得到单词出现的次数。
package com.atguigu.bigdata.spark.core.wc
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//复杂版wordcount
class spark01_fuzaWrodCount {}
object spark01_fuzaWrodCount{def main(args: Array[String]): Unit = {//之前是使用size 方法,得出单词出现的次数,但是那样实现不像是个聚合功能,所以我们改善一下
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val context = new SparkContext(sparkConf)
println(context)
//TODD 执行业务操作
//1、读取文件,获取一行一行的数据 这一步是扁平化
//hello word
val value = context.textFile("D:\\wc.txt") //textFile 可以吧文件一行一行的读出来
//2、将数据进行拆分,形成一个一个的单词
//扁平化:将整体拆分为个体的操作
//"hello word" =>hello,word
val danci: RDD[String] = value.flatMap(a =>a.split(" ")) //根据空格进行拆分
val wordToOne: RDD[(String, Int)] = danci.map(word =>(word, 1)) //直接在这一步统计单词出现的次数
val wordGroup: RDD[(String, Iterable[(String, Int)])] = wordToOne.groupBy(t =>t._1) //然后按照方式,取第一个元素为分组的依据
val wordToCount = wordGroup.map{//这一步不是用size了
case (word,list) =>{list.reduce(
(t1,t2) =>{(t1._1,t1._2 + t2._2)
}
)
}
}
//这里不是直接size,而是进行reduce,聚合操作,将key给加起来
//val wordCount2 = wordGroup.map{case (word,list)=>{ list.reduce((t1,t2)=>{(t1._1,t1._2+t2._2)})}}
val array: Array[(String, Int)] = wordToCount.collect() //采集结果打印输出
array.foreach(println) //foreach()方法进行遍历
//TODD 关闭连接
context.stop() //这样就关闭连接了
}
}Spark框架里面有个方法,分组和聚合可以一个方法完成reduceByKey(_ + _),这样大大减少了代码量,从读取文件进来,到输出结果四五行就能完成这个案例。
package com.atguigu.bigdata.spark.core.wc
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
//使用saprk框架进行统计
class spark02_sparkCount {}
object spark02_sparkCount{def main(args: Array[String]): Unit = {//之前是使用size 方法,得出单词出现的次数,但是那样实现不像是个聚合功能,所以我们改善一下
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val context = new SparkContext(sparkConf)
println(context)
//TODD 执行业务操作
//1、读取文件,获取一行一行的数据 这一步是扁平化
//hello word
val value = context.textFile("D:\\wc.txt") //textFile 可以吧文件一行一行的读出来
//2、将数据进行拆分,形成一个一个的单词
//扁平化:将整体拆分为个体的操作
//"hello word" =>hello,word
val danci: RDD[String] = value.flatMap(a =>a.split(" ")) //根据空格进行拆分
val wordToOne: RDD[(String, Int)] = danci.map(word =>(word, 1)) //直接在这一步统计单词出现的次数
//Spark 框架提供了更多的功能,可以将分组和聚合使用一个功能实现
//reduceByKey():相同的key的数据,可以对value进行reduce聚合 这是spark提供的功能
val wordCount = wordToOne.reduceByKey((x,y) =>x+y) //相当于同一个key 进行累加_ + _ 可以简化成这样
val array: Array[(String, Int)] = wordCount.collect() //采集结果打印输出
array.foreach(println) //foreach()方法进行遍历
//TODD 关闭连接
context.stop() //这样就关闭连接了
}
}简化下来就是这几步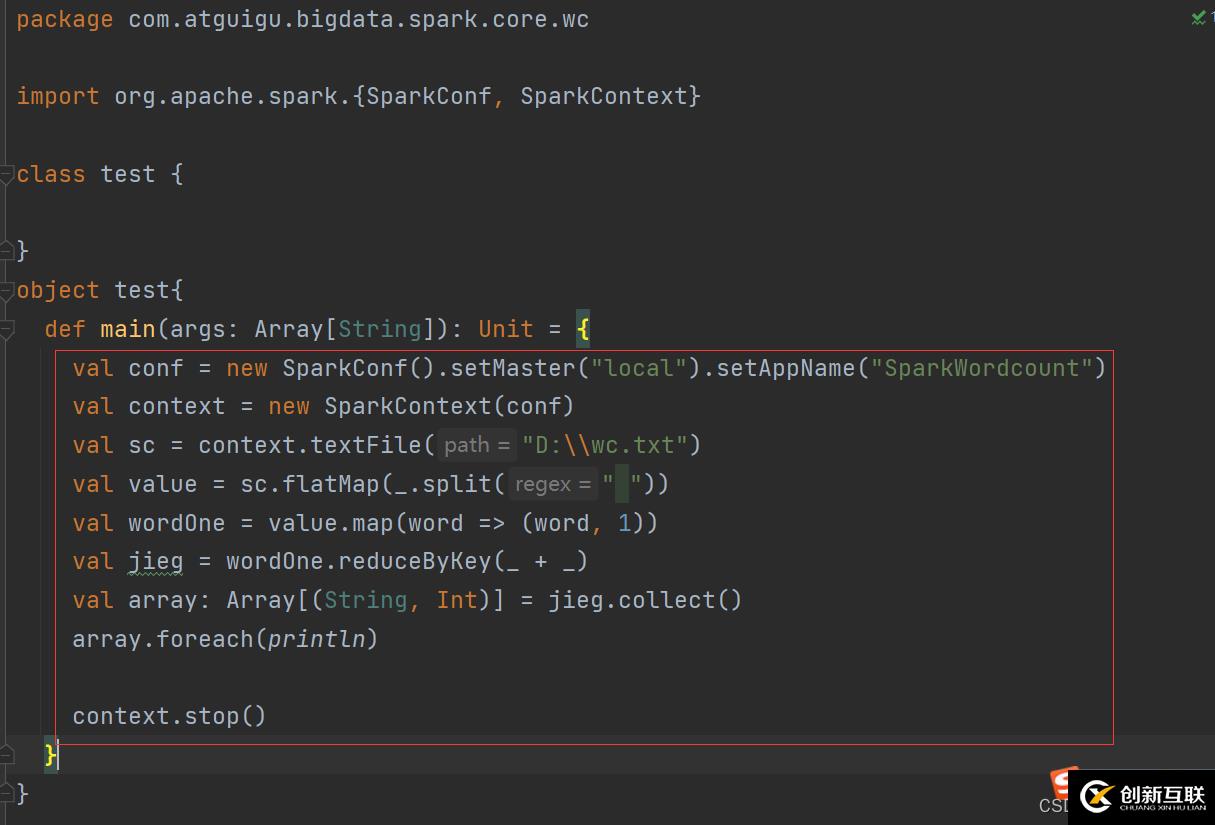
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
网站题目:SparkWordCount案例-创新互联
网页网址:https://www.cdcxhl.com/article8/dgdcop.html
成都网站建设公司_创新互联,为您提供网站内链、用户体验、响应式网站、网页设计公司、动态网站、品牌网站制作
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 企业电子商务网站营销运营的解决方案 2022-11-28
- AR/VR解决方案 2021-05-30
- 营销网站建设解决方案 2021-05-11
- 外贸网站建设和规范设计解决方案 2022-08-14
- 李工与大家谈谈企业网站建设解决方案 2022-06-25
- 科技网站建设,科技公司网站建设解决方案怎么做 2023-03-05
- 企业内网网站建设解决方案 2022-06-28
- 物联网解决方案 2021-05-14
- B2B平台推广技巧-让网络营销更上一个台阶! 2022-06-09
- 网站定制功能解决方案-网站建设创新互联科技 2021-11-26
- 个人网站建设创新互联之解决方案 2015-09-17
- 深圳网站建设技术解决方案的特点 2021-08-12