VMwarevSphere5.1群集深入解析(二十八)-创新互联
VMware vSphere

5.1
Clustering Deepdive
HA.DRS.Storage DRS.Stretched Clusters
Duncan Epping &Frank Denneman
Translate By Tim2009 / 翻译:Tim2009
目录
版权
关于作者
知识点
前言
第一部分 vSphere高可用性
第一章 介绍vSphere高可用性
第二章 高可用组件
第三章 基本概念
第四章 重新启动虚拟机
第五章 增加高可用灵活性(网络冗余)
第六章 访问控制
第七章 虚拟机和应用监控
第八章 集成
第九章 汇总
第二部分 vSphere DRS(分布式资源调度)
第一章 vSphere DRS介绍
第二章 vMotion和EVC
第三章 DRS动态配额
第四章 资源池与控制
第五章 DRS计算推荐
第六章 DRS推荐向导
第七章 DPM介绍
第八章 DPM计算推荐
第九章 DPM推荐向导
第十章 汇总
第三部分 vSphere存储DRS
第一章 vSphere存储DRS介绍
第二章 存储DRS算法
第三章 存储I/O控制(SIOC)
第四章 数据存储配置
第五章 数据存储架构与设计
第六章 对存储vMotion的影响
第七章 关联性
第八章 数据存储维护模式
第九章 总结汇总
第四部分 群集架构的扩展
第一章 群集架构的扩展
第二章 vSphere配置
第三章 故障排错
第四章 总结汇总
第五章 附录
第四部分 群集架构的扩展
第二章 vSphere配置
这种情况下,我们的重点是扩展群集环境中vSphere HA,vSphere DRS和存储DRS之间的关系,以及围绕这些vSphere组件在设计和运作方面经常被忽视和低估的考虑。历来很多重点放在存储层,而很少考虑工作负载如何配置和管理。
如我们之前提到的,扩展群集关键的驱动力是工作负载平衡和灾难避免。怎样确认我们的环境是处在合理的平衡中而没有影响可用性或者大幅减少操作开销?我们怎样建立配置需求和持续管理过程,我们怎样定期验证我们仍然满足我们的需求?定义和遵从需求失败会使环境混乱难以管理、各种故障场景难以预测,也会希望它来帮助你。事实上,忽略过程会导致故障事件中产生额外的停机时间。
这三个VMware vSphere功能每一个都有特别的配置需求,能加强你环境的弹性和工作负载的可用性,通过这一部分,架构建议将产生,这些建议将基于测试期间的各种场景发现的问题。每一个故障场景测试在接下来的章节中都被记录,请记住,这些故障场景直接应用这些实例的配置,基于你的实施和配置选项你的环境可能会受到额外故障。
vSphere HA特性
我们的实例环境中有4台主机和一个统一扩展存储解决方案。当全部站点发生故障是需要考虑弹性架构的一个场景,我们建议开启接入控制(Admission Control),工作负载的可用性是许多扩展群集环境的主要驱动力,它建议有足够的容量允许全站点故障,尽管如此,两个站点将平等的分配主机,来确保所有的工作负载能通过HA重新开始,建议配置接入控制策略为50%。
我们建议使用基于百分比的策略来提供架构的灵活性和减少操作开销,尽管新主机加入环境中没有必要改变百分比,而且没有整合率偏差,导致使用虚拟机级别预留资源的风险,更多详情请见第6章。
HA使用心跳检测机制来验证主机的状态,如第3章解释的有两个心跳检测机制;称为网络和数据存储心跳检测,网络心跳检测时HA验证主机的主要机制,数据存储心跳检测是一旦网络心跳检测失败通过HA来确定主机状态的另一种机制。
如果主机没有收到任何的心跳检测,它检测是否仅仅是从其它主机隔离或者网络中完全隔离。这个过程包括了Ping主机的默认网关,或者一个或者多个手工设置的隔离地址来代替主机网关,从而加强隔离检测的可靠性。我们建议指定最少两个额外的隔离地址并且每个地址能到本地网络,即使在站点之间连接失败的情况下,开启HA能够验证完整的网络隔离,并提供冗余允许一个IP故障。
但是,如果主机被隔离,vSphere HA触发响应,这在之前有解释过,叫做隔离响应,当主机同管理网络之间的连接断开,触发隔离响应来保证妥善管理虚拟机。隔离响应在第三章有深入讨论,根据使用不同的存储和物理网络完成,隔离响应用来在需要时做出决定,我们提到在第四章,表3中支持的决定。
在我们的测试环境中,一部分这些地址将属于Frimley 数据中心,另一部分属于Bluefine数据中心,屏幕截图显示了怎样配置多个隔离地址的实例,vSphereHA高级设置使用das.isolationaddress,更详细的如何配置可以在KB 文章 1002117中找到。
为了vSphere HA数据存储心跳在任何故障场景中都运行正常,我们建议增加数据存储心跳的数量为2-4,最少的数据存储心跳为2,大为5,扩展群集环境中建议4,这样将提供本地的全冗余。还建议定义4个指定数据存储为优先数据存储心跳,选择一个站点的2个然后选择另一个站点的2个。这样做即使站点之间发生连接故障也允许vSphere HA的数据存储心跳。如果站点之间发生连接故障后站点还存在部分网络,这些数据存储将非常有用。
数据存储心跳的数量能通过HA高级设置das.heartbeatDsPerHost.进行增加。
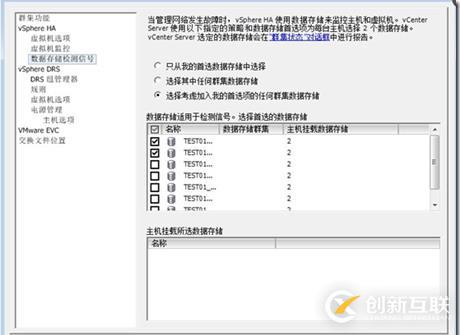
我们建议使用“选择考虑加入我的选项的任何群集数据存储”,它将允许vSphere HA选择任意4个设计的数据存储,我们手工选择变得不可用,原因是如果我们建议的站点间4个心跳连接失败,vCenter将最终在一个站点上,这样另一个站点的主机就没有机会HA来改变数据存储心跳。这个设置的截屏如下。
图163:数据存储心跳
vSphere 5.0 U1永久设备丢失(PDL)增强
vSphere 5.0 U1版本中,介绍了永久设备丢失(PDL)的条件—允许数据存储上的虚拟机自动故障转移,我们将在其中一个故障场景中展示一个PDL环境,沟通的环境是通过阵列控制器经过一个指定的SCSI代码到ESXi,这些条件声明一个设备(LUN)将不可用,并且可能是永久不可用。当存储管理员设置这个LUN脱机,这个实例场景通过阵列通信,当撤回访问LUN,不统一的环境发生故障期间用来确定ESXi进行合适的行动,应该注意的是当全部存储发生故障,可能生成永久磁盘丢失的情况,在阵列和ESXi主机之间没有通信的可能,这个状态通过ESXi主机来识别当做所有路径断开(APD)。
重要的是认识到接下来的设置只应用PDL环境,而不是APD环境,在我们的故障环境中,我们将论证两种环境的不同行为。
为了允许vSphere HA响应PDL环境,vSphere U1里介绍了两个高级设置,第一个主机设置是disk.terminateVMOnPDL Default。这个设置在/etc/vmware/settings里配置,由默认设置为“True”,注意这是每主机的设置,主机需要重新启动这个设置才生效,当数据存储进入了PDL状态,这个设置确保杀掉虚拟机。PDL环境中一旦杀掉虚拟机,数据存储就磁盘I/O初始化。如果虚拟机的文件没有在同一个数据存储上,并且PDL存在其中一个数据存储上,通过HA虚拟机可能不会重新启动,vSphere 5.1里修正了这个问题,为了确保PDL环境中能通过HA进行迁移,我们建议设置disk.terminateVMonPDL Default 为“True”,并将虚拟机文件放置单个数据存储上,请注意当数据存储没有产生I/O,虚拟机只是被杀掉,虚拟机可以恢复活动的。正在运行密集内存负载而数据存储没有产生I/O的虚拟机可能恢复活动状态。
第二个设置是vSphere HA的高级设置,称之为das.maskCleanShutdown Enabled。vSphere 5.0 U1中介绍了这个设置,默认是禁用的,需要设置你的HA群集为“True”,这个设置允许HA触发PDL环境中自动杀掉的虚拟机重启,HA不能区分虚拟机是被PDL杀掉还是被管理员关闭,设置标记“True”假定是前者。注意在APD期间用户关机将被行为标记
我们建议设置das.maskCleanShutdown Enabled 为“True”,为了限制PDL环境数据存储上虚拟机的停机时间,当das.maskCleanShutdown Enabled没有设置“True”,PDL环境也存在,disk.terminateVMonPDL Default被设置为“True”,杀掉虚拟机后,虚拟机重新启动不会发生,HA将假定虚拟机是管理员断电(或者关闭)。
vSphere DRS
vSphere DRS在很多环境中用来分配群集负载。vSphere DRS提供很多其它功能来帮助扩展环境,我们建议开启vSphere DRS允许群集的主机之间的负载平衡,vSphere DRS 负载平衡计算是基于CPU和内存的使用情况,同样,关于存储和网络资源利用率和流量也必须小心照顾,为了避免扩展群集环境中非预期的存储和网络流量开销,我们建议执行vSphere DRS关联规则来允许合乎逻辑和可预测的分开虚拟机,这将帮我们提高可用性,负责架构服务的AD,DNS虚拟机,这将有助于确保这些服务跨站点分离。
vSphere DRS关联规则还帮助阻止存储不要的停机时间和网络流量过载,我们建议调整vSphere VM-Host的存储配置关联规则,我们的意思设置VM-Host关联规则,这样虚拟机偏向于运行在同一站点的主机上,同时数据存储阵列的主要读/写节点进行配置。例如,我们的测试配置中,虚拟机存储在Frimley-01数据存储设置了VM-Host关联规则是偏向于Frimley数据中心的主机。这样确保了站点间网络连接发生故障时,虚拟机不会断开与存储系统的连接。VM-Host关联规则配置取决于这些建议,从而确保虚拟机呆在主数据存储本地。巧合的是所有的读I/O来自于它们站点的本地虚拟机,注意:不同存储厂商使用不同的技术来描述LUN到阵列或者控制器的关系,在这个章节我们将使用通用术语“Storage Site Affinity”,“Storage Site Affinity”意味着偏向于LUN的本地读写访问。
我们建议执行“should rules”,这些在HA发生故障时都能够被冲突,服务的可用性应该一直胜过性能。在“Must rule”情况下,HA将不会同设置的规则冲突,在站点或主机发生故障时它可能导致服务中断。一个数据中心发生故障的场景,“Must rules”将使它不可能为vSphere HA重启虚拟机,同时他们没有关联规则请求来允许虚拟机在其它数据中心的主机上开启。vSphere DRS同HA的沟通这些规则,把他们存储在允许启动的兼容性列表。vSphere DRS还有一个注意的地方,在某些情况下,如果大量的主机不平衡和激进建议设置,会与“Should rule”冲突。尽管非常罕见,我们建议监控对你的工作负载产生可用性和性能有冲突的规则。
我们建议手工定义创建站点的一组主机,基于数据存储关联规则添加虚拟机到这个站点上,在我们的场景中只有限制数量的虚拟机被发布,我们建议使用vCenter Orchestrator或者Power CLI自动定义站点关联规则,如果没有选择自动,我们推荐使用一个通用的命名惯例,简化创建这些组,我们建议这些组定期验证,来确保属于组的虚拟机有正确的站点关联规则。
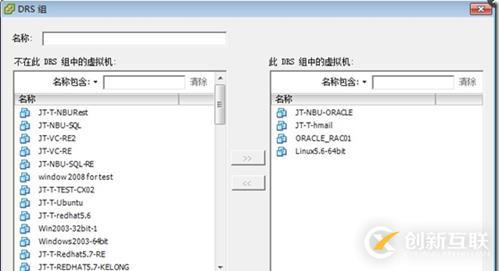
接下来的截屏描述了用于该场景的配置,在第一张截图中,所有的虚拟机应保持在Bluefin本地的虚拟机组内。
图164:DRS组-虚拟机
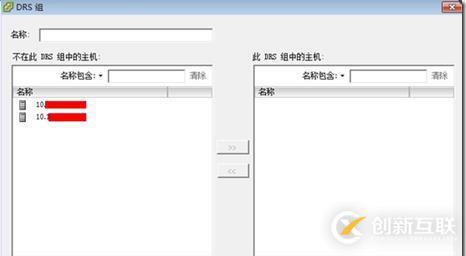
接下来,创建一个本地包括所有主机的Bluefin 主机组。
图165:DRS组-主机
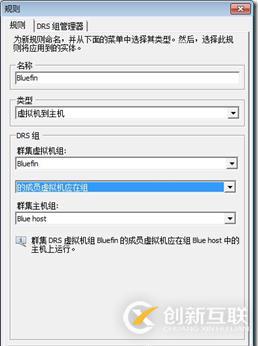
最终,Bluefin本地创建好了一个新的规则,定义了连接到主机组虚拟机组“should run on”规则
图166:VM-Host规则
两边本地都应该完成,直接导致了4个组合2个规则。
图167:结果-管理规则
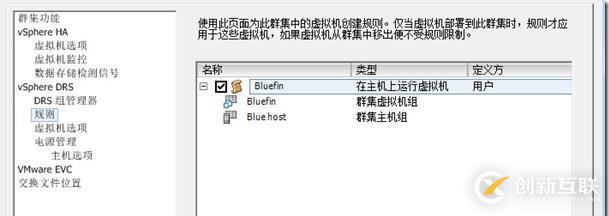
调整关联性规则冲突
DRS分配了高优先级来调整关联性规则冲突,在调用期间,DRS的主要目标是调整任何冲突和为群集主机组主机清单上虚拟机生成迁移建议,这些移动的优先级比负载平衡高,所以将在负载平衡之前开始虚拟机迁移。
DRS默认每5分钟调用一次,但是如果群集检测到更改DRS还是会触发,当主机重新连接上群集,DRS被调用,并生成建议来调整任何识别的冲突。我们的测试展示了在主机重新连接群集后的30秒内DRS生成建议来调整关联规则冲突。注意DRS限制了vMotion网络的总吞吐量,这意味着在所有的管理规则冲突被调整之前,可能需要多次调用。
vSphere Storage DRS
当定义的性能或者容量阈值超出,Storage DRS从管理员角度和虚拟机、磁盘平衡来考虑启用激进的单一数据存储,存储DRS确保你的工作负载中足够的磁盘资源可用,我们建议开启存储DRS。
存储DRS使用存储vMotion在数据存储群集内的数据存储上来迁移虚拟机,由于底层扩展存储系统使用同步复制,一个迁移或者一系列迁移将对重复流量有影响,导致在移动磁盘的时候出现网络资源争用,可能引起虚拟机临时不可用。从站点的角度,如果虚拟机不一起迁移它们的磁盘,在同一访问配置中迁移漫游数据存储还可能导致额外的I/O延迟。例如,如果Frimley主机上的虚拟机有磁盘迁移到Bluefin的数据存储上,它将继续操作,但可能降低性能。虚拟机读取磁盘受制于站点B读取虚拟iSCSI IP延迟的增加和受制于站点间的延迟。
当迁移发生时能够控制,我们建议配置存储DRS手工模式,这允许人工验证每个建议,并允许在非峰值时间应用建议,同时获得操作的益处和初始化位置的效率。
我们建议基于存储配置遵从存储站点关联来创建数据存储群集,站点A关联的数据存储不能同站点B的数据存储相互混合。这将允许操作的一致性和缓和DRS VM-Host关联规则的创建和持续。因此当数据存储群集和定义存储站点关联边界之间的虚拟机被迁移,建议来保证所有的vSphere DRS VM-Host关联规则被更新。我们建议调整数据存储群集和VM-Host关联规则的命名约定,以简化配置和管理流程。
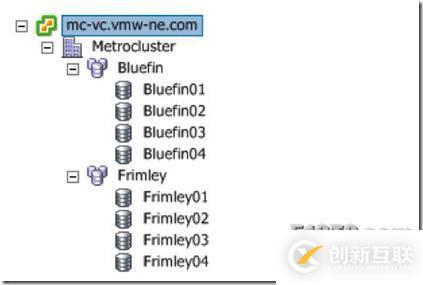
命名约定在我们的测试中用来给数据存储和数据存储群集一个特别的站点名称,从而简化站点上发布虚拟机的DRS主机关联性。在我们的站点“Bluefin”和“Frimley”里的站点特指存储见下图。请注意vCenter映射功能不能用来查看存储当前的站点关联,同时也不能显示数据存储群集的对象。
图168:数据存储群集架构
另外有需要云服务器可以了解下创新互联cdcxhl.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
本文题目:VMwarevSphere5.1群集深入解析(二十八)-创新互联
本文网址:https://www.cdcxhl.com/article8/dedhop.html
成都网站建设公司_创新互联,为您提供外贸建站、Google、微信公众号、手机网站建设、品牌网站设计、网站维护
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 成都做网站要多少钱?网站制作好怎样进行有效推广? 2016-09-06
- 网站改版的好处 2016-09-20
- 企业做网站容易出现哪些错误? 2021-05-11
- 成都做网站流程 2017-10-29
- 企业选择做网站公司需注意的问题 2020-07-20
- 珠海企业做网站:你知道如何增加网站的流量吗? 2021-10-07
- 如何做网站才能体现出企业文化 2022-11-02
- 找建站公司做网站,这些一定要了解,否则你肯定后悔! 2016-11-05
- 做网站用自助建站怎么样 好不好 2016-07-16
- 做网站空间变动一般要碰到哪些情况? 2022-10-14
- 做网站就选上海网站建设公司、上海网站设计公司 2020-11-05
- 做网站可以通过什么手段取得访客的信任 2022-10-25