如何理解Flink端到端精准一次处理语义Exactly-once
本篇内容主要讲解“如何理解 Flink 端到端精准一次处理语义 Exactly-once”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“如何理解 Flink 端到端精准一次处理语义 Exactly-once”吧!
专注于为中小企业提供网站建设、成都网站建设服务,电脑端+手机端+微信端的三站合一,更高效的管理,为中小企业海北州免费做网站提供优质的服务。我们立足成都,凝聚了一批互联网行业人才,有力地推动了成百上千家企业的稳健成长,帮助中小企业通过网站建设实现规模扩充和转变。
在 Flink 中需要端到端精准一次处理的位置有三个:
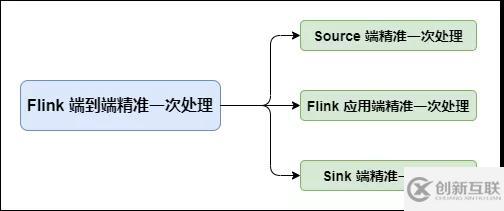
Flink 端到端精准一次处理
Source 端:数据从上一阶段进入到 Flink 时,需要保证消息精准一次消费。
Flink 内部端:这个我们已经了解,利用 Checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性。
Flink可靠性的基石-checkpoint机制详细解析
Sink 端:将处理完的数据发送到下一阶段时,需要保证数据能够准确无误发送到下一阶段。
在 Flink 1.4 版本之前,精准一次处理只限于 Flink 应用内,也就是所有的 Operator 完全由 Flink 状态保存并管理的才能实现精确一次处理。但 Flink 处理完数据后大多需要将结果发送到外部系统,比如 Sink 到 Kafka 中,这个过程中 Flink 并不保证精准一次处理。
在 Flink 1.4 版本正式引入了一个里程碑式的功能:两阶段提交 Sink,即 TwoPhaseCommitSinkFunction 函数。该 SinkFunction 提取并封装了两阶段提交协议中的公共逻辑,自此 Flink 搭配特定 Source 和 Sink(如 Kafka 0.11 版)实现精确一次处理语义(英文简称:EOS,即 Exactly-Once Semantics)。
Flink端到端精准一次处理语义(EOS)
注:以下内容适用于 Flink 1.4 及之后版本
对于 Source 端:Source 端的精准一次处理比较简单,毕竟数据是落到 Flink 中,所以 Flink 只需要保存消费数据的偏移量即可, 如消费 Kafka 中的数据,Flink 将 Kafka Consumer 作为 Source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性。
对于 Sink 端:Sink 端是最复杂的,因为数据是落地到其他系统上的,数据一旦离开 Flink 之后,Flink 就监控不到这些数据了,所以精准一次处理语义必须也要应用于 Flink 写入数据的外部系统,故这些外部系统必须提供一种手段允许提交或回滚这些写入操作,同时还要保证与 Flink Checkpoint 能够协调使用(Kafka 0.11 版本已经实现精确一次处理语义)。
我们以 Flink 与 Kafka 组合为例,Flink 从 Kafka 中读数据,处理完的数据在写入 Kafka 中。
为什么以Kafka为例,第一个原因是目前大多数的 Flink 系统读写数据都是与 Kafka 系统进行的。第二个原因,也是最重要的原因 Kafka 0.11 版本正式发布了对于事务的支持,这是与Kafka交互的Flink应用要实现端到端精准一次语义的必要条件。
当然,Flink 支持这种精准一次处理语义并不只是限于与 Kafka 的结合,可以使用任何 Source/Sink,只要它们提供了必要的协调机制。
Flink 与 Kafka 组合
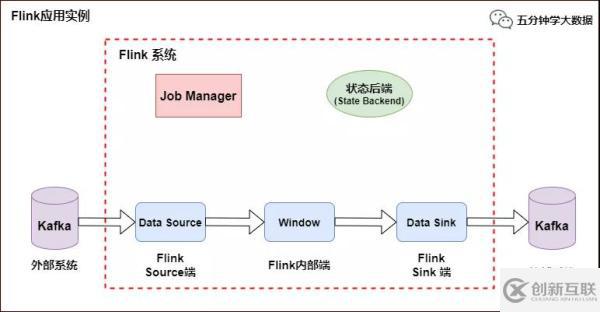
Flink 应用示例
如上图所示,Flink 中包含以下组件:
一个 Source,从 Kafka 中读取数据(即 KafkaConsumer)
一个时间窗口化的聚会操作(Window)
一个 Sink,将结果写入到 Kafka(即 KafkaProducer)
若要 Sink 支持精准一次处理语义(EOS),它必须以事务的方式写数据到 Kafka,这样当提交事务时两次 Checkpoint 间的所有写入操作当作为一个事务被提交。这确保了出现故障或崩溃时这些写入操作能够被回滚。
当然了,在一个分布式且含有多个并发执行 Sink 的应用中,仅仅执行单次提交或回滚是不够的,因为所有组件都必须对这些提交或回滚达成共识,这样才能保证得到一个一致性的结果。Flink 使用两阶段提交协议以及预提交(Pre-commit)阶段来解决这个问题。
两阶段提交协议(2PC)
两阶段提交协议(Two-Phase Commit,2PC)是很常用的解决分布式事务问题的方式,它可以保证在分布式事务中,要么所有参与进程都提交事务,要么都取消,即实现 ACID 中的 A (原子性)。
在数据一致性的环境下,其代表的含义是:要么所有备份数据同时更改某个数值,要么都不改,以此来达到数据的强一致性。
两阶段提交协议中有两个重要角色,协调者(Coordinator)和参与者(Participant),其中协调者只有一个,起到分布式事务的协调管理作用,参与者有多个。
顾名思义,两阶段提交将提交过程划分为连续的两个阶段:表决阶段(Voting)和提交阶段(Commit)。
两阶段提交协议过程如下图所示:
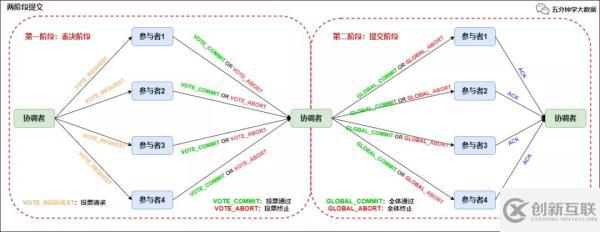
两阶段提交协议
第一阶段:表决阶段
协调者向所有参与者发送一个 VOTE_REQUEST 消息。
当参与者接收到 VOTE_REQUEST 消息,向协调者发送 VOTE_COMMIT 消息作为回应,告诉协调者自己已经做好准备提交准备,如果参与者没有准备好或遇到其他故障,就返回一个 VOTE_ABORT 消息,告诉协调者目前无法提交事务。
第二阶段:提交阶段
协调者收集来自各个参与者的表决消息。如果所有参与者一致认为可以提交事务,那么协调者决定事务的最终提交,在此情形下协调者向所有参与者发送一个 GLOBAL_COMMIT 消息,通知参与者进行本地提交;如果所有参与者中有任意一个返回消息是 VOTE_ABORT,协调者就会取消事务,向所有参与者广播一条 GLOBAL_ABORT 消息通知所有的参与者取消事务。
每个提交了表决信息的参与者等候协调者返回消息,如果参与者接收到一个 GLOBAL_COMMIT 消息,那么参与者提交本地事务,否则如果接收到 GLOBAL_ABORT 消息,则参与者取消本地事务。
两阶段提交协议在 Flink 中的应用
Flink 的两阶段提交思路:
我们从 Flink 程序启动到消费 Kafka 数据,最后到 Flink 将数据 Sink 到 Kafka 为止,来分析 Flink 的精准一次处理。
当 Checkpoint 启动时,JobManager 会将检查点分界线(checkpoint battier)注入数据流,checkpoint barrier 会在算子间传递下去,如下如所示:
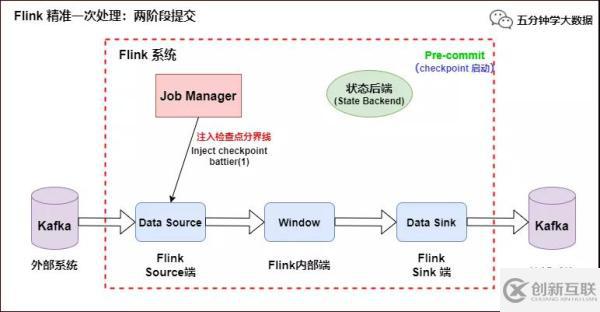
Flink 精准一次处理:Checkpoint 启动
Source 端:Flink Kafka Source 负责保存 Kafka 消费 offset,当 Chckpoint 成功时 Flink 负责提交这些写入,否则就终止取消掉它们,当 Chckpoint 完成位移保存,它会将 checkpoint barrier(检查点分界线) 传给下一个 Operator,然后每个算子会对当前的状态做个快照,保存到状态后端(State Backend)。
对于 Source 任务而言,就会把当前的 offset 作为状态保存起来。下次从 Checkpoint 恢复时,Source 任务可以重新提交偏移量,从上次保存的位置开始重新消费数据,如下图所示:
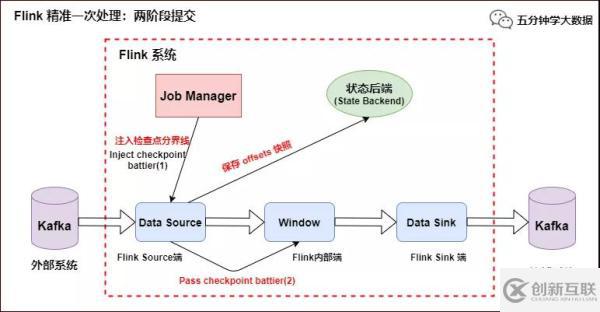
Flink 精准一次处理:checkpoint barrier 及 offset 保存
Slink 端:从 Source 端开始,每个内部的 transform 任务遇到 checkpoint barrier(检查点分界线)时,都会把状态存到 Checkpoint 里。数据处理完毕到 Sink 端时,Sink 任务首先把数据写入外部 Kafka,这些数据都属于预提交的事务(还不能被消费),此时的 Pre-commit 预提交阶段下 Data Sink 在保存状态到状态后端的同时还必须预提交它的外部事务,如下图所示:
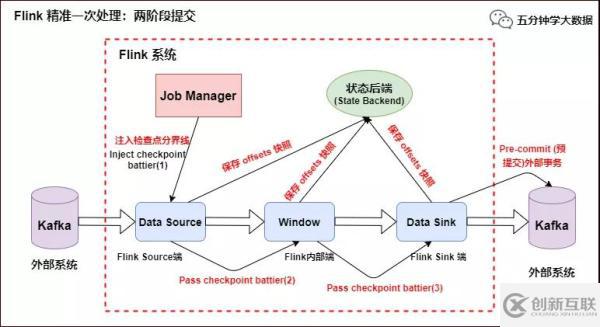
Flink 精准一次处理:预提交到外部系统
当所有算子任务的快照完成(所有创建的快照都被视为是 Checkpoint 的一部分),也就是这次的 Checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 Checkpoint 完成,此时 Pre-commit 预提交阶段才算完成。才正式到两阶段提交协议的第二个阶段:commit 阶段。该阶段中 JobManager 会为应用中每个 Operator 发起 Checkpoint 已完成的回调逻辑。
本例中的 Data Source 和窗口操作无外部状态,因此在该阶段,这两个 Opeartor 无需执行任何逻辑,但是 Data Sink 是有外部状态的,此时我们必须提交外部事务,当 Sink 任务收到确认通知,就会正式提交之前的事务,Kafka 中未确认的数据就改为“已确认”,数据就真正可以被消费了,如下图所示:
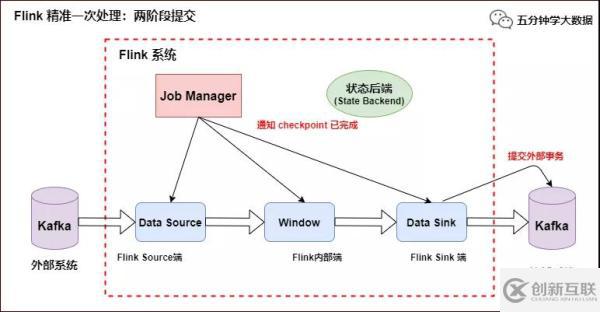
Flink 精准一次处理:数据精准被消费
注:Flink 由 JobManager 协调各个 TaskManager 进行 Checkpoint 存储,Checkpoint 保存在 StateBackend(状态后端) 中,默认 StateBackend 是内存级的,也可以改为文件级的进行持久化保存。
最后,一张图总结下 Flink 的 EOS:

Flink 端到端精准一次处理
到此,相信大家对“如何理解 Flink 端到端精准一次处理语义 Exactly-once”有了更深的了解,不妨来实际操作一番吧!这里是创新互联网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
分享名称:如何理解Flink端到端精准一次处理语义Exactly-once
网页URL:https://www.cdcxhl.com/article6/ipedig.html
成都网站建设公司_创新互联,为您提供服务器托管、做网站、定制网站、外贸网站建设、企业建站、App开发
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 企业网站制作要求 2013-11-19
- 企业网站制作后如何推广 2021-08-08
- 企业网站制作必须要做备案吗? 2022-12-29
- 企业网站制作的基本步骤有哪些 2017-06-17
- 企业网站制作如何通过数据分析来提升用户粘性 2020-12-07
- 松江企业网站制作常见问题有哪些? 2020-12-21
- 常见网站设计风格技巧-成都企业网站制作 2023-03-08
- 企业网站制作要怎么才能吸引用户浏览 2016-08-22
- 如何让企业网站制作体验度更好? 2021-08-26
- 企业网站制作需自成一格 2021-09-09
- 企业网站制作如何获取客户的信任 2021-09-24
- 企业网站制作怎样提高竞争力? 2023-04-22