ApacheFlinkJobManagerHA部署-创新互联
1. 下载源代码:
git clone https://github.com/apache/flink.git git branch -a
检出blink分支
git checkout -b blink remotes/origin/blink查看分支
git branch
2. 编译
mvn package -DskipTests
注意:
由于网络问题,编译flink-filesystems/flink-mapr-fs模块时,连接http://repository.mapr.com/maven 仓库速度较慢,修改link-filesystems/flink-mapr-fs/pom.xml文件,切换仓库为aliyun仓库:
<repositories>
<repository>
<id>aliyun-mapr-releases</id>
<url>https://maven.aliyun.com/repository/mapr-public/</url>
<snapshots><enabled>false</enabled></snapshots>
<releases><enabled>true</enabled></releases>
</repository>
<!--
<repository>
<id>mapr-releases</id>
<url>http://repository.mapr.com/maven/</url>
<snapshots><enabled>false</enabled></snapshots>
<releases><enabled>true</enabled></releases>
</repository>
-->
</repositories>修改nodejs仓库, flink-runtime-web/pom.xml:
<execution>
<id>npm install</id>
<goals>
<goal>npm</goal>
</goals>
<configuration>
<arguments>install -g -registry=https://registry.npm.taobao
.org --cache-max=0 --no-save</arguments>
</configuration>
</execution>
3. 打包
tar -cjvpf blink-1.5.1.tar.bz2 ./flink-1.5.1/
4. 部署
4.1 前置条件
- 部署有Hadoop集群(HDFS)
- 部署有Zookeeper集群
节点信息:
res-spark-0001 (master)
res-spark-0002 (master)
res-spark-0003 (slave)
res-spark-0004 (slave)
res-spark-0005 (slave)
4.2 解压缩
tar -jxvf blink-1.5.1.tar.bz24.3 配置文件
1).hdfs-site.xml
?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
wITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--HA-->
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
<description>Logical name for this new nameservice</description>
</property>
<!--每个nameservice至多配置两个节点-->
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nn1,nn2</value>
<description>Unique identifiers for each NameNode in the nameservice</description>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nn1</name>
<value>res-spark-0001:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nn2</name>
<value>res-spark-0002:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nn1</name>
<value>res-spark-0001:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nn2</name>
<value>res-spark-0002:50070</value>
</property>
<!--journalNode默认端口号为8485-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://res-spark-0005:8485;res-spark-0004:8485;res-spark-0002:8485/cluster1</value>
</property>
<!--Client与ActiveNameNode交互的实现类-->
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-file</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!--
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>64m</value>
</property>
-->
<property>
<name>dfs.namenode.handler.count</name>
<value>20</value>
</property>
<!--
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>DC-Hadoop-slave1:50090</value>
</property>
-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>8192</value>
</property>
<!--
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
-->
</configuration>2). core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
wITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
<final>true</final>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/disk1/hadoop/tmp/journal/node/local/data</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/disk1/hadoop/tmp/hadoop/hadoop-${user.name}</value>
<description>A bas for other temporary directories</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>res-spark-0001:2181,res-spark-0002:2181,res-spark-0003:2181</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- <property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints.</description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
-->
<property>
<name>fs.file.impl</name>
<value>org.apache.hadoop.fs.LocalFileSystem</value>
<description>The FileSystem for file: uris.</description>
</property>
<property>
<name>fs.hdfs.impl</name>
<value>org.apache.hadoop.hdfs.DistributedFileSystem</value>
<description>The FileSystem for hdfs: uris.</description>
</property>
<!--
<property>
<name>hadoop.proxyuser.oozie.groups</name>
<value>group1,group2<value>
</property>
<property>
<name>hadoop.proxyuser.oozie.hosts</name>
<value>*<value>
</property>
-->
</configuration>3). masters
res-spark-0001:8081
res-spark-0002:80814). slaves
res-spark-0003
res-spark-0004
res-spark-00055). flink-conf.yaml
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# wITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
#==============================================================================
# Common
#==============================================================================
# The external address of the host on which the JobManager runs and can be
# reached by the TaskManagers and any clients which want to connect. This setting
# is only used in Standalone mode and may be overwritten on the JobManager side
# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.
# In high availability mode, if you use the bin/start-cluster.sh script and setup
# the conf/masters file, this will be taken care of automatically. Yarn/Mesos
# automatically configure the host name based on the hostname of the node where the
# JobManager runs.
jobmanager.rpc.address: localhost
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The heap size for the JobManager JVM
jobmanager.heap.size: 1024m
# The heap size for the TaskManager JVM
taskmanager.heap.size: 1024m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 6
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
# The default file system scheme and authority.
#
# By default file paths without scheme are interpreted relative to the local
# root file system 'file:///'. Use this to override the default and interpret
# relative paths relative to a different file system,
# for example 'hdfs://mynamenode:12345'
#
# fs.default-scheme
#fs.default-scheme: hdfs://cluster1
#==============================================================================
# High Availability
#==============================================================================
# The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
#
# high-availability: zookeeper
high-availability: zookeeper
# The path where metadata for master recovery is persisted. While ZooKeeper stores
# the small ground truth for checkpoint and leader election, this location stores
# the larger objects, like persisted dataflow graphs.
#
# Must be a durable file system that is accessible from all nodes
# (like HDFS, S3, Ceph, nfs, ...)
#
# high-availability.storageDir: hdfs:///flink/ha/
high-availability.storageDir: hdfs:///flink/ha/
# The list of ZooKeeper quorum peers that coordinate the high-availability
# setup. This must be a list of the form:
# "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
#
# high-availability.zookeeper.quorum: localhost:2181
high-availability.zookeeper.quorum: res-spark-0001:2181,res-spark-0002:2181,res-spark-0003:2181
high-availability.cluster-id: /cluster_one
# ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# The default value is "open" and it can be changed to "creator" if ZK security is enabled
#
# high-availability.zookeeper.client.acl: open
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# <class-name-of-factory>.
#
# state.backend: filesystem
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
state.checkpoints.dir: hdfs://cluster1/flink-checkpoints
# Default target directory for savepoints, optional.
#
# state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints
state.savepoints.dir: hdfs://cluster1/flink-checkpoints
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#
# state.backend.incremental: false
#==============================================================================
# Web Frontend
#==============================================================================
# The address under which the web-based runtime monitor listens.
#
#web.address: 0.0.0.0
# The port under which the web-based runtime monitor listens.
# A value of -1 deactivates the web server.
rest.port: 8081
# Flag to specify whether job submission is enabled from the web-based
# runtime monitor. Uncomment to disable.
#web.submit.enable: false
web.submit.enable: true
#==============================================================================
# Advanced
#==============================================================================
# Override the directories for temporary files. If not specified, the
# system-specific Java temporary directory (java.io.tmpdir property) is taken.
#
# For framework setups on Yarn or Mesos, Flink will automatically pick up the
# containers' temp directories without any need for configuration.
#
# Add a delimited list for multiple directories, using the system directory
# delimiter (colon ':' on unix) or a comma, e.g.:
# /data1/tmp:/data2/tmp:/data3/tmp
#
# Note: Each directory entry is read from and written to by a different I/O
# thread. You can include the same directory multiple times in order to create
# multiple I/O threads against that directory. This is for example relevant for
# high-throughput RAIDs.
#
# io.tmp.dirs: /tmp
# Specify whether TaskManager's managed memory should be allocated when starting
# up (true) or when memory is requested.
#
# We recommend to set this value to 'true' only in setups for pure batch
# processing (DataSet API). Streaming setups currently do not use the TaskManager's
# managed memory: The 'rocksdb' state backend uses RocksDB's own memory management,
# while the 'memory' and 'filesystem' backends explicitly keep data as objects
# to save on serialization cost.
#
# taskmanager.memory.preallocate: false
# The classloading resolve order. Possible values are 'child-first' (Flink's default)
# and 'parent-first' (Java's default).
#
# Child first classloading allows users to use different dependency/library
# versions in their application than those in the classpath. Switching back
# to 'parent-first' may help with debugging dependency issues.
#
# classloader.resolve-order: child-first
# The amount of memory going to the network stack. These numbers usually need
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, teh default max is 1GB.
#
# taskmanager.network.memory.fraction: 0.1
# taskmanager.network.memory.min: 64mb
# taskmanager.network.memory.max: 1gb
#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================
# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL
# The below configure how Kerberos credentials are provided. A keytab will be used instead of
# a ticket cache if the keytab path and principal are set.
# security.kerberos.login.use-ticket-cache: true
# security.kerberos.login.keytab: /path/to/kerberos/keytab
# security.kerberos.login.principal: flink-user
# The configuration below defines which JAAS login contexts
# security.kerberos.login.contexts: Client,KafkaClient
#==============================================================================
# ZK Security Configuration
#==============================================================================
# Below configurations are applicable if ZK ensemble is configured for security
# Override below configuration to provide custom ZK service name if configured
# zookeeper.sasl.service-name: zookeeper
# The configuration below must match one of the values set in "security.kerberos.login.contexts"
# zookeeper.sasl.login-context-name: Client
#==============================================================================
# HistoryServer
#==============================================================================
# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
#jobmanager.archive.fs.dir: hdfs:///completed-jobs/
jobmanager.archive.fs.dir: hdfs:///completed-jobs/
# The address under which the web-based HistoryServer listens.
#historyserver.web.address: 0.0.0.0
# The port under which the web-based HistoryServer listens.
#historyserver.web.port: 8082
# Comma separated list of directories to monitor for completed jobs.
#historyserver.archive.fs.dir: hdfs:///completed-jobs/
historyserver.archive.fs.dir: hdfs:///completed-jobs/
# Interval in milliseconds for refreshing the monitored directories.
#historyserver.archive.fs.refresh-interval: 10000res-spark-0001节点:
jobmanager.rpc.address: res-spark-0001res-spark-0002节点:
jobmanager.rpc.address: res-spark-00026)启动集群
bin/start-cluster.sh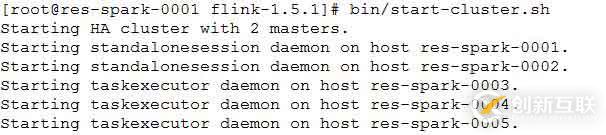
7)启动historyserver
bin/historyserver.sh start另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
网页题目:ApacheFlinkJobManagerHA部署-创新互联
网站链接:https://www.cdcxhl.com/article6/cesoog.html
成都网站建设公司_创新互联,为您提供面包屑导航、网站改版、网站建设、移动网站建设、网站策划、企业网站制作
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- ChatGPT的发展历程 2023-02-20
- ChatGPT是什么?ChatGPT是聊天机器人吗? 2023-05-05
- 马云回国,首谈ChatGPT。又是新一个风口? 2023-05-28
- ChatGPT的应用ChatGPT对社会的利弊影响 2023-02-20
- ChatGPT是什么 2023-02-20
- 火爆的ChatGPT,来聊聊它的热门话题 2023-02-20
- 怎样利用chatGPT快速赚钱? 2023-05-05
- 爆红的ChatGPT,谁会丢掉饭碗? 2023-02-20