怎样理解R语言
本篇文章为大家展示了怎样理解R语言,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
涪陵网站建设公司创新互联公司,涪陵网站设计制作,有大型网站制作公司丰富经验。已为涪陵1000+提供企业网站建设服务。企业网站搭建\外贸营销网站建设要多少钱,请找那个售后服务好的涪陵做网站的公司定做!
R语言包的安装
1.1R语言包
包是R函数、数据、预编译代码以一种定义完善的格式组成的集合。计算机上存储包的目录称为库(library)。函数.libPaths()能够显示库所在的位置, 函数library()则可以显示库中有哪些包。
R自带了一系列默认包(包括base、datasets、utils、grDevices、graphics、stats以及methods),它们提供了种类繁多的默认函数和数据集。其他包可通过下载来进行安装。安装好以后,它们必须被载入到会话中才能使用。命令search()可以告诉你哪些包已加载并可使用。
1.2R语言包的下载与安装
可以进入官方网站下载所需的包,也可以使用命令下载安装。
第一次安装一个包,使用命令install.packages()即可,不加参数执行install.packages()将显示一个CRAN镜像站点的列表,选择其中一个镜像站点之后,将看到所有可用包的列表,选择其中的一个包即可进行下载和安装。如果知道自己想安装的包的名称,可以直接将包名作为参数提供给这个函数。
一个包仅需安装一次。但和其他软件类似,包经常被其作者更新。使用命update.packages()可以更新已经安装的包。要查看已安装包的描述,可以使用installed.packages()命令,这将列出安装的包,以及它们的版本号、依赖关系等信息。
进入官方网站进行下载
https://cran.r-project.org/
一.向量操作
1.向量构成的基本元素为:
数值(numeric)
字符(character)
逻辑值(logical)
复数型(complex)
2.向量不需要定义类型,可直接赋值: x[9]<-9;x # 当向量x不够长时,指定第9个元素为9
x[9]<-9;x # 当向量x不够长时,指定第9个元素为9

3.给向量加名字:

4.向量元素的添加及合并

5几种特殊向量的生成
5.1生成系列seq()
seq(length=,from=, to=)
length:指定生成个数
from:是指开始生成的点
to:截止点
如果不指定,则默认条件下:
seq(N1,N2,BY=)
n1:开始位置
n2:截止位置
by=指定间隔

5.2 rep(P,N)重复生成P值N次

6.向量运算
#基本运算符+,-,*,/对应加减乘除
#<,>,<=,>= 大于,小于,大于等于,小于等于
# %/% 整除
# %% 求余数
#abs绝对值,sqrt平方根
#简单统计函数:sum求和,min最小值,
max最大值,mean平均值,

7.向量排序
sort();
输出排序后的结果;
order();
输出排序后的各个向量位置

8.按条件提取向量的元素

9.向量的比较

二.矩阵操作
矩阵的存储默认是按列进行存储的
1. 创建矩阵

创建一个c(1:12)的三行四列的矩阵

2. 矩阵的转置
y<-t(x)
若是针对的是一个向量
y<-(1:10)
转置后得到的是行向量

用class( )函数获得的类型分别是数值型和字符型
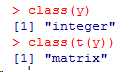
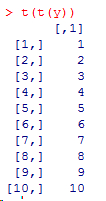
若要得到列向量则
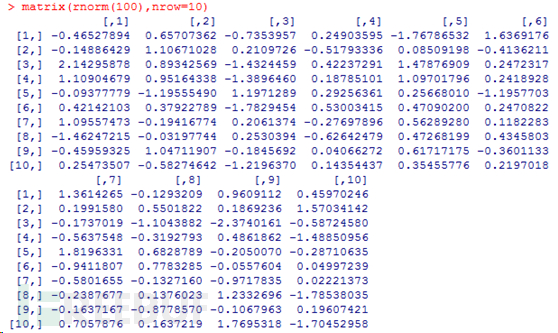
3. 创建一个服从正态分布的随机数矩阵
4. 创建对角矩阵和单位阵

5.代数意义下的矩阵乘法"%*%"
yy<- matrix(1:6, 3, 2); zz <- matrix(1:6, 2, 3)
yy%*% zz; zz %*% yy
6. 矩阵行和列的维数
xx<- matrix(1:20, 4, 5)
dim(xx)#行和列的维数
nrow(xx);ncol(xx) #行数和列数
7.矩阵合并
aa<- matrix(1:6, 3, 2); bb <- matrix(7:12, 3, 2)
cbind(aa,bb) #按列合并
rbind(aa,bb) #按行合
8.矩阵apply()运算函数:
语法是apply(data, dim,function),dim取1表示对行运用函数,取2表示对列运用函数。
xx<- matrix(1:20, 4, 5)
colMeans(xx)#列均值
colSums(xx)#列和
rowMeans(xx)#行均值
rowSums(xx)#行和
i
三、数据框:
由于不同的列可以包含不同模式(数值型、字符型等)的数据,数据框的概念较矩阵来说更为一般。数据框将是在R中常处理的 数据结构。
数据框可通过函数data.frame()创建,其中的列向量col1, col2, col3,…可为任何类型(如字符型、数值型或逻辑型)。每一列的 名称可由函数names指定。
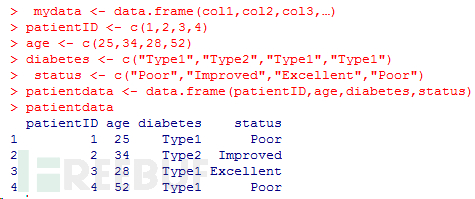
每一列数据的模式必须唯一,不过却可以将多个模式的不同列放到一起组成数据框。
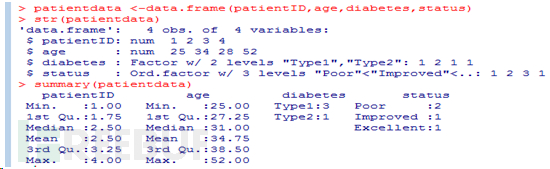
选取数据框中元素的方式有若干种。可以使用前述(如矩阵中的)下标记号,亦可直接指定列名。如:
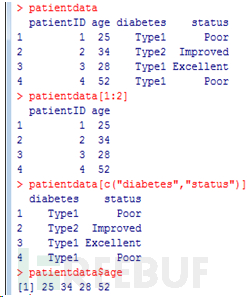
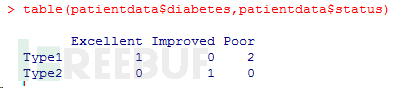
第三个例子中的记号$是新出现的 。它被用来选取一个给定数据框中的某个特定变量。例 如,如果你想生成糖尿病类型变量diabetes和病情变量status的列联表,使用以下代码即可
在每个变量名前都键入一次patientdata$可能会让人生厌,所以不妨走一些捷径。可以联 合使用函数attach()和detach()或单独使用函数with()来简化代码。
attach()、detach()和with() 函数attach()可将数据框添加到R的搜索路径中。R在遇到一个变量名以后,将检查搜索路 径中的数据框,以定位到这个变量。
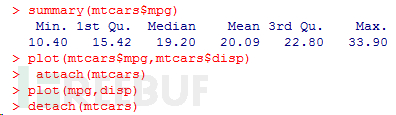
函数detach()将数据框从搜索路径中移除。
当名称相同的对象不止一个时,这种方法的局限性就很明显了。

四、因子
类别(名义型)变量和有序类别(有序型)变量在R中称为因子(factor)。因子在R中非常重要,因为它决定了数据的分析方式以及如何进行视觉呈现。函数factor()以一个整数向量的形式存储类别值,整数的取值范围是[1… k ](其中k 是名义型变量中唯一值的个数),同时一个由字符串(原始值)组成的内部向量将映射到这些整数上。
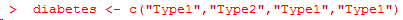
语句diabetes <- factor(diabetes)将此向量存储为(1, 2,1, 1),并在内部将其关联为 1=Type1和2=Type2(具体赋值根据字母顺序而定)。针对向量diabetes进行的任何分析都会将 其作为名义型变量对待,并自动选择适合这一测量尺度的统计方法。 要表示有序型变量,需要为函数factor()指定参数ordered=TRUE。给定向量:

语句status <- factor(status, ordered=TRUE)会将向量编码为(3, 2, 1, 3),并在内部将这 些值关联为1=Excellent、2=Improved以及3=Poor。
对于字符型向量,因子的水平默认依字母顺序创建。这对于因子status是有意义的,因为 “Excellent”、“Improved”、“Poor”的排序方式恰好与逻辑顺序相一致。如果“Poor”被编码为 “Ailing”,会有问题,因为顺序将为“Ailing”、“Excellent”、“Improved”。如果理想中的顺序是 “Poor”、“Improved”、“Excellent”,则会出现类似的问题。按默认的字母顺序排序的因子很少能够让人满意。 你可以通过指定levels选项来覆盖默认排序。
例如:
因子的使用:
上述内容就是怎样理解R语言,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注创新互联行业资讯频道。
当前名称:怎样理解R语言
本文来源:https://www.cdcxhl.com/article48/ipeshp.html
成都网站建设公司_创新互联,为您提供微信小程序、关键词优化、云服务器、ChatGPT、网站收录、网站维护
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 云虚拟主机如何使用? 2022-10-09
- 虚拟主机有哪些优点? 2013-06-29
- 网站怎样择有保障的虚拟主机 2016-04-18
- 哪家的虚拟主机好? 2022-07-07
- 徐汇做网站告诉你如何判断虚拟主机的好坏 2022-09-24
- 虚拟主机和vps、服务器哪个好 2021-06-09
- 企业建站选择美国虚拟主机的优势在哪里 2021-03-02
- 上海网站建设基础知识:虚拟主机知识大全总结 2019-04-19
- 虚拟主机空间流量为什么会有限制? 2016-11-07
- 虚拟主机打不开怎么处理? 2022-10-09
- 什么是网站空间(虚拟主机)? 2020-06-10
- 哪类网站不适合使用虚拟主机? 2021-05-05