在Scrapy中怎么利用Xpath选择器从网页中采集目标数据
这篇文章主要介绍在Scrapy中怎么利用Xpath选择器从网页中采集目标数据,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
我们提供的服务有:做网站、成都网站制作、微信公众号开发、网站优化、网站认证、崇阳ssl等。为近1000家企事业单位解决了网站和推广的问题。提供周到的售前咨询和贴心的售后服务,是有科学管理、有技术的崇阳网站制作公司
/具体实现/

1、针对标题,在上篇文章中就有提及,其Xpath表达式有多种,任选其一即可,在scrapy shell脚本下进行调试,得到标题的提取方式,并写入到爬虫主体文件中。
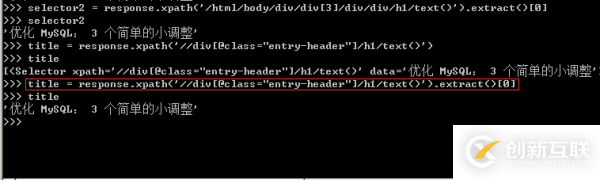
2、接下来是发布日期的提取,仍然是以交互式的方式实现网页与源码之间的交互,如下图所示。
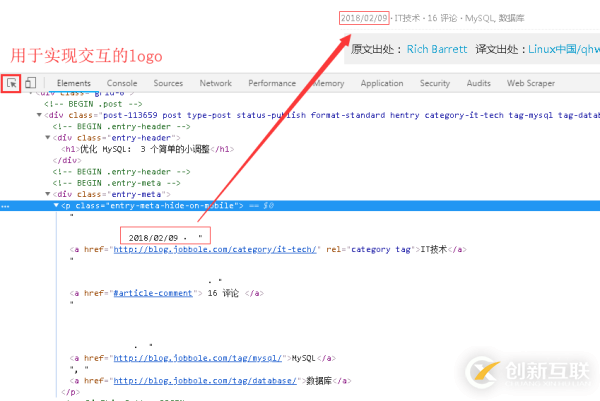
3、而且标签“entry-meta-hide-on-mobile”具有全局唯一性,可以很方便的定位到元素。
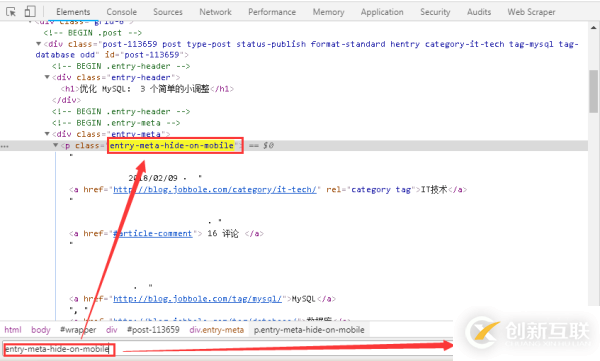
4、根据网页结构,我们可轻易的写出发布日期的Xpath表达式,可以在scrapy shell中先进行测试,再将选择器表达式写入爬虫文件中,详情如下图所示。
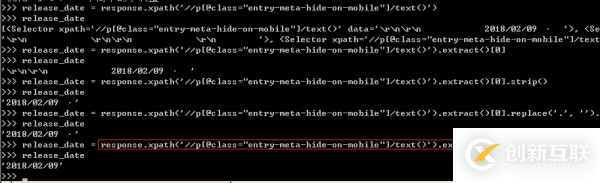
这里有部分杂质信息,需要利用strip()和replace()函数剔除多余的杂质,还日期一个“清白”。
5、关于文章主题标签的Xpath表达式,可以看到其在网页结构上处于日期的下方,如下图所示。
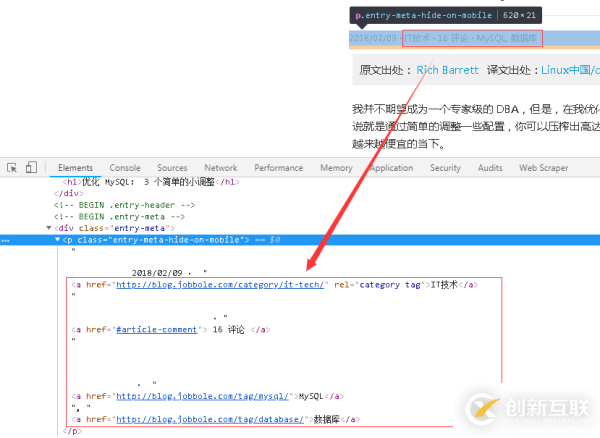
因此可以通过更改一下发布日期的Xpath表达式,即可获取到文章主题标签。
6、文章主题标签处于a标签下,如下图所示。
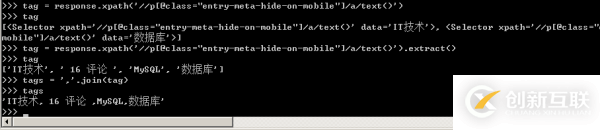
获取到整个列表之后,利用join函数将数组中的元素以逗号连接生成一个新的字符串叫tags,然后写入Scrapy爬虫文件中去。
7、对于点赞数,其分析方法同之前一致,找到唯一的一个标签“vote-post-up”即可定位到数据。
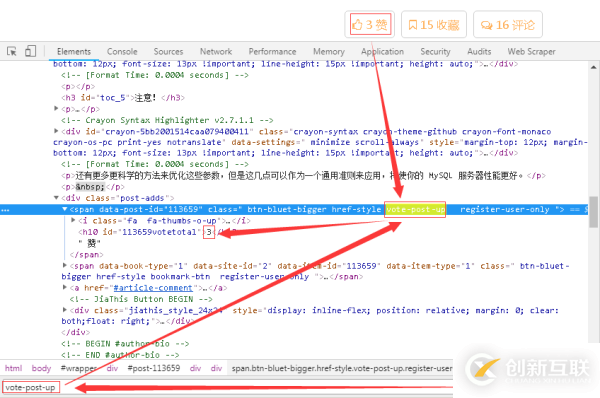
8、细心的小伙伴可能会看到“vote-post-up”属性并不是class标签中唯一一个属性,所以一开始的Xpath表达式匹配的内容为空。
这里给大家安利一个小技巧,如果标签中存在多个属性,且属性是唯一的时候,可以利用contains函数进行助攻,其用法是'//span[contains(@class,"vote-post-up"),务必要多加练习,否则容易忘记。根据网页结构写出Xpath表达式,调试的过程如下图所示。
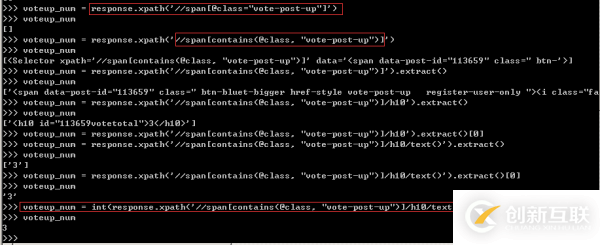
取出的点赞数是个字符串,需要利用int()将其强制转换为数字。
/具体实现/
9、根据点赞数采集的方法,我们可以很快的定位到收藏数,其对应的网页结构稍微有些不同,但是分析方法是一致的,不再赘述,如下图所示。
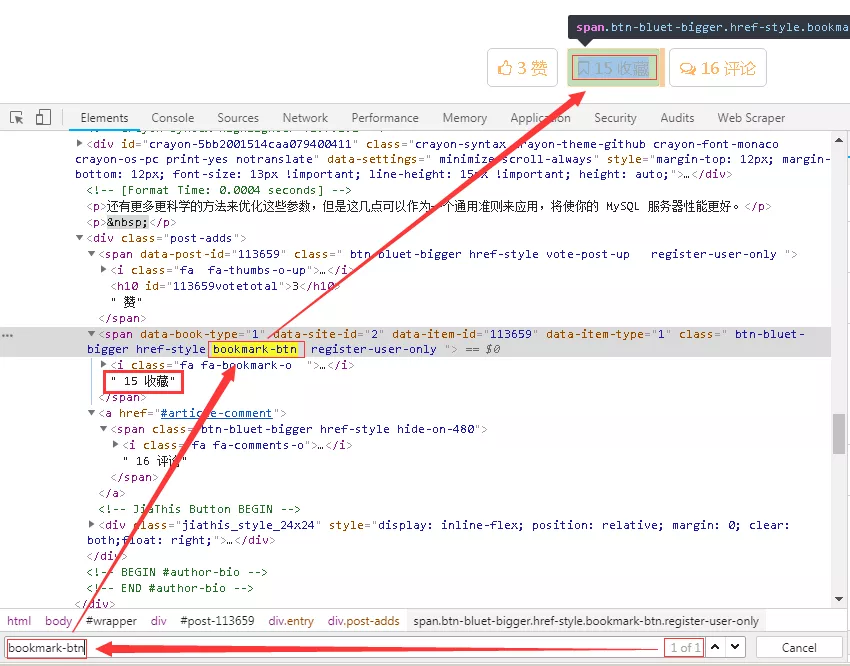
10、这里直接给出调试的代码,如下图所示。

11、不过我们需要的是其中的数字,这时候就可以利用正则表达式进行匹配,关于正则表达式的文章,之前有过连载,不熟悉正则表达式的小伙伴可以翻看历史文章,有详细说明的。在Pycharm中进行调试,代码也很简单,如下图所示。
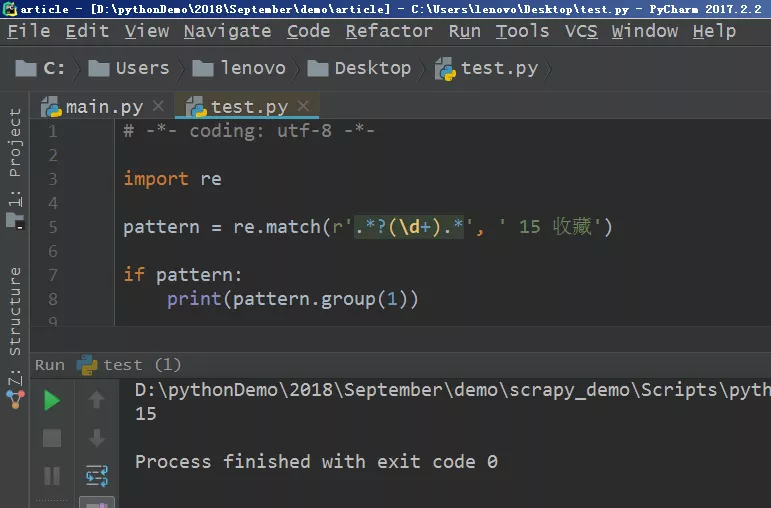
尔后将该代码放入到爬虫主体文件中即可,记得将“15 收藏”这部分替换成collection_num即可。
12、评论数相对简单一些,其有专门的一个标签,如下图所示。
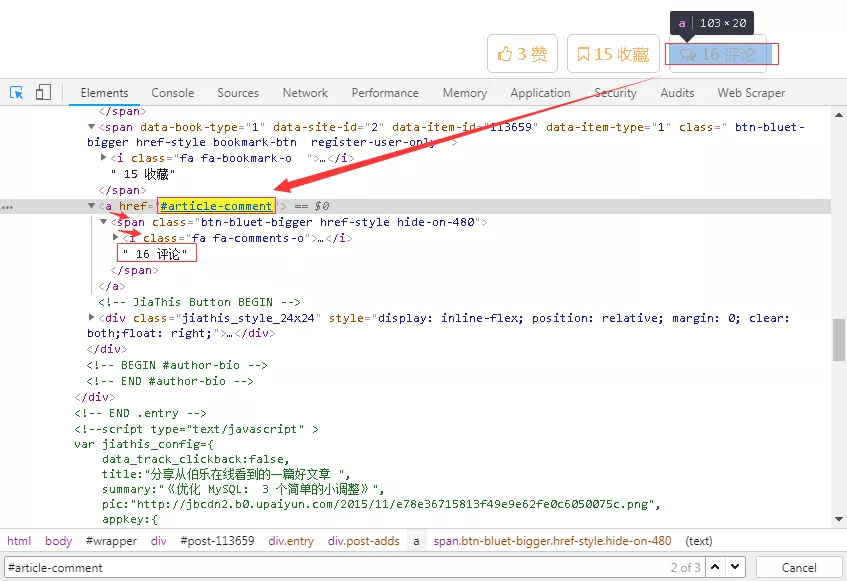
13、需要注意的是评论数这里的标签不是class,而是href,需要和网页上对应,否则取出的值为空列表。
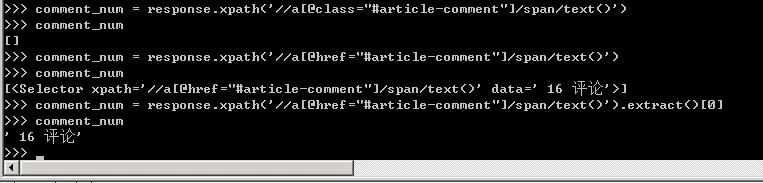
14、同收藏数一样,仍然要以正则表达式的形式去匹配数字,可以直接复制收藏数的代码,然后将收藏数collection_num改为评论数的comment_num即可。

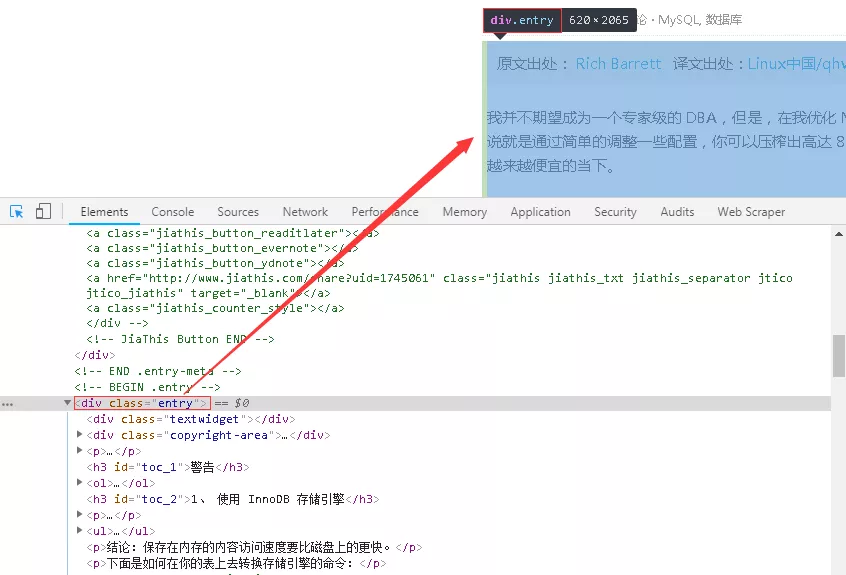
15、关于正文的提取,不同的网页有不同的结构,而且相对复杂,这里不做细究,整体目标是将网页内容和标签均提取出来。分析网页结构,发现正文内容在“entry”标签下,如下图所示。
\
16、之后在scrapyshell调试,可以得到内容的Xpath表达式,如下图所示。
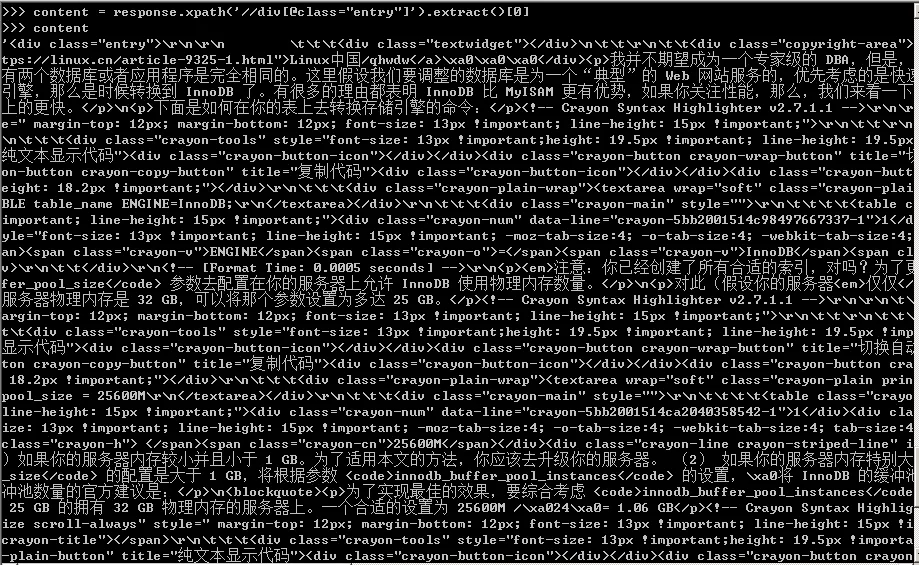
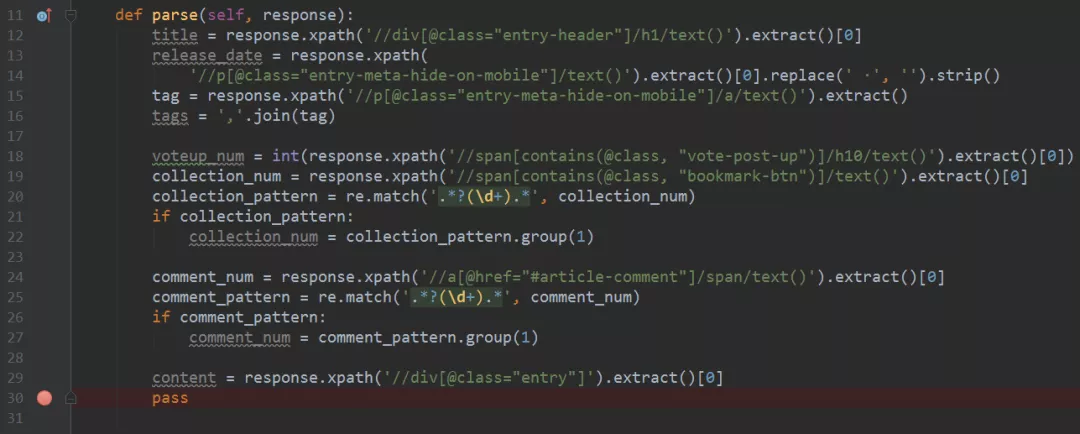
17、到这里,该网页中的信息提取的差不多了,结合上面的分析和Xpath表达式,我们得到的整体代码如下图所示。
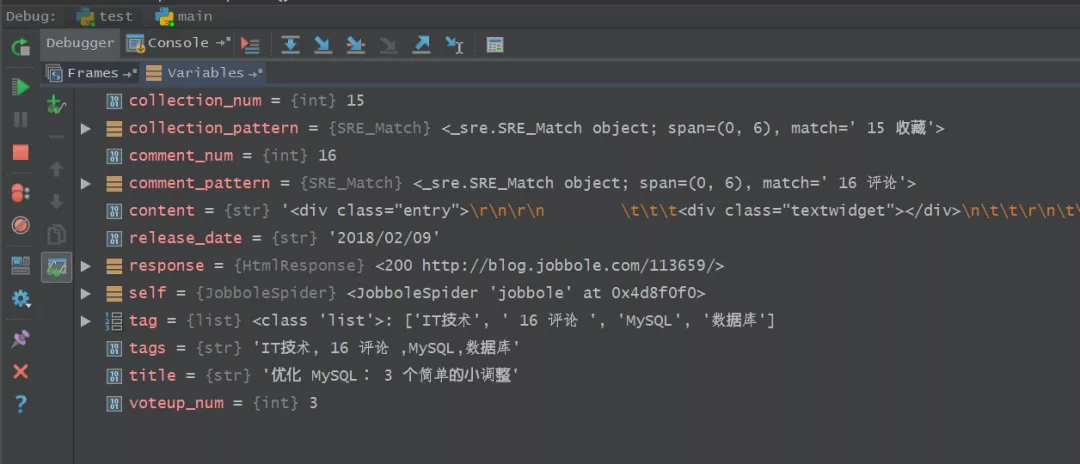
18、尔后进行Debug调试,查看代码中获取的内容,如下图所示,十分清晰。
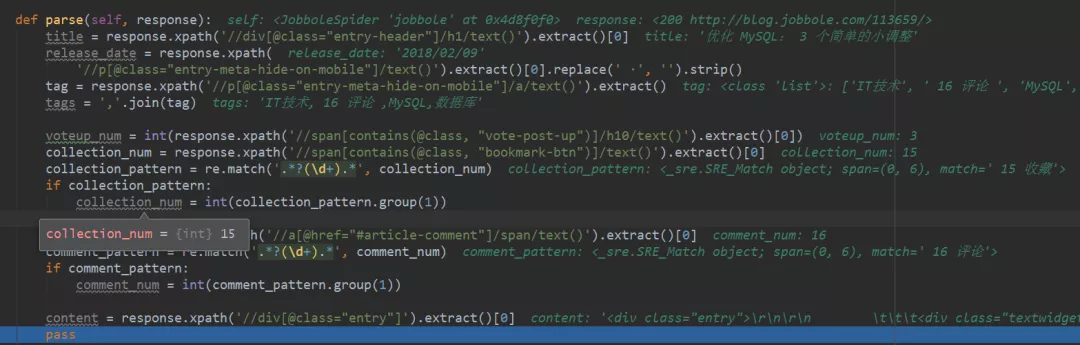
19、下图是控制台部分显示出的变量结果,与代码中显示的内容和网页上的信息都是保持一致的。
至此,关于Xpath表达式的具体应用教程先告一段落。总体来看,我们需要利用F12快捷键来审查网页元素,尔后分析网页结构并进行交互,然后根据网页结构写出Xpath表达式,习惯性的结合scrapy shell进行调试,得到调优的表达式,写入爬虫文件中去,最后执行爬虫程序或者Debug调试查看最终的数据采集结果。
以上是“在Scrapy中怎么利用Xpath选择器从网页中采集目标数据”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注创新互联行业资讯频道!
文章名称:在Scrapy中怎么利用Xpath选择器从网页中采集目标数据
当前URL:https://www.cdcxhl.com/article48/ieojep.html
成都网站建设公司_创新互联,为您提供标签优化、做网站、网站营销、自适应网站、外贸网站建设、搜索引擎优化
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 创新互联观点:做网站建设之前要考虑的一些问题 2014-02-03
- 5G时代是否需要网站建设 2014-10-18
- 企业网站建设如何做排名优化? 2022-08-11
- 商城网站建设报价 2021-04-20
- 上海网站建设公司浅谈过去经历事项 2020-06-16
- 定制网站建设具备有哪些优势 2021-05-06
- 网站建设完成之后的几种营销推广方式 2022-05-25
- 日常网站建设中运营与优化的工作重点 2022-12-18
- 企业的网站建设需要的基本功能 2022-06-15
- 成都网站建设公司怎么建站才利于优化_成都创新互联 2021-09-29
- 网站建设方案中网站功能设置的原则和要求 2021-12-04
- PHP网站建设之去除文件bom头信息 2023-03-06