调度系统的设计原理是什么
调度是一个非常广泛的概念,很多领域都会使用调度这个术语,在计算机科学中,调度就是一种将任务(Work)分配给资源的方法。任务可能是虚拟的计算任务,例如线程、进程或者数据流,这些任务会被调度到硬件资源上执行,例如:处理器 CPU 等设备。
创新互联是专业的白云网站建设公司,白云接单;提供成都网站建设、做网站,网页设计,网站设计,建网站,PHP网站建设等专业做网站服务;采用PHP框架,可快速的进行白云网站开发网页制作和功能扩展;专业做搜索引擎喜爱的网站,专业的做网站团队,希望更多企业前来合作!

图 1 - 调度系统设计精要
本文会介绍调度系统的常见场景以及设计过程中的一些关键问题,调度器的设计最终都会归结到一个问题上 — 如何对资源高效的分配和调度以达到我们的目的,可能包括对资源的合理利用、最小化成本、快速匹配供给和需求。
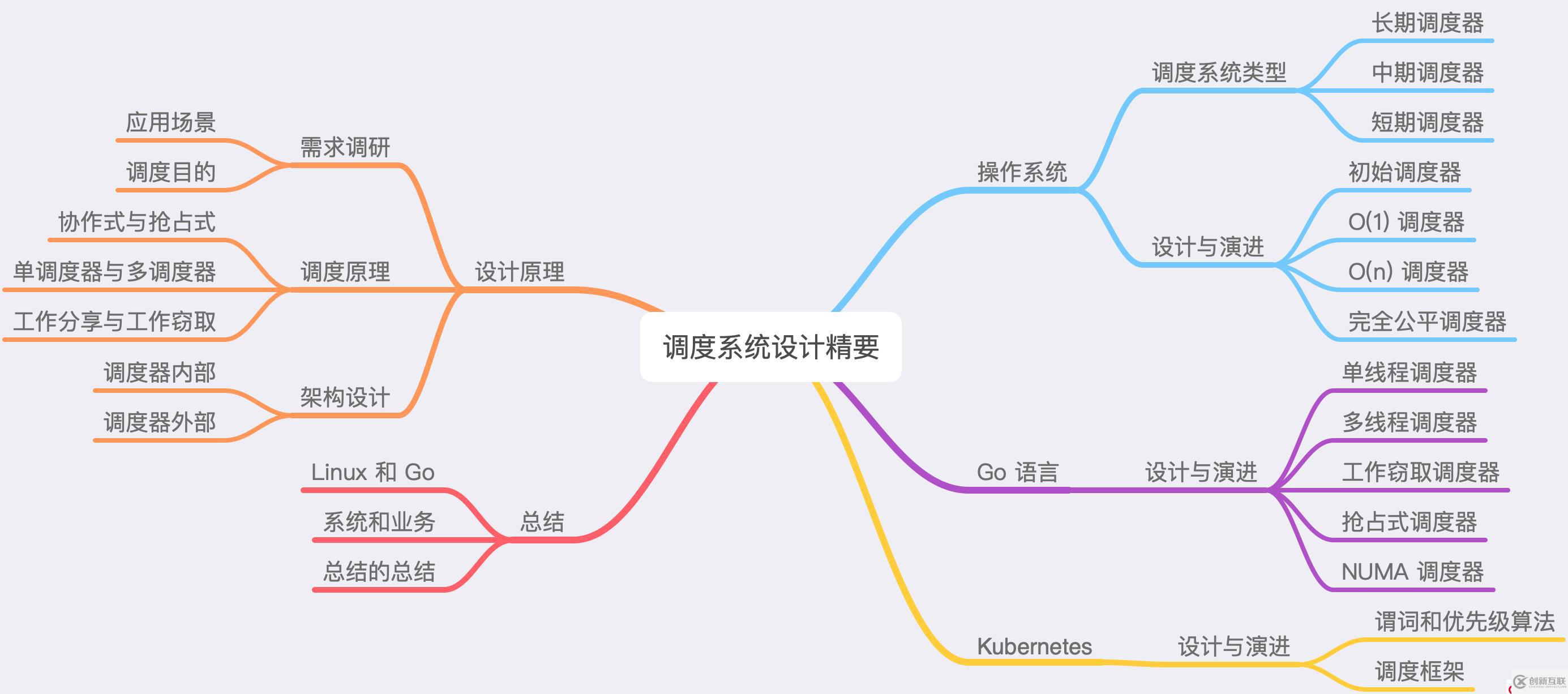
图 2 - 文章脉络和内容
除了介绍调度系统设计时会遇到的常见问题之外,本文还会深入分析几种常见的调度器的设计、演进与实现原理,包括操作系统的进程调度器,Go 语言的运行时调度器以及 Kubernetes 的工作负载调度器,帮助我们理解调度器设计的核心原理。
设计原理
调度系统其实就是调度器(Scheduler),我们在很多系统中都能见到调度器的身影,就像我们在上面说的,不止操作系统中存在调度器,编程语言、容器编排以及很多业务系统中都会存在调度系统或者调度模块。
这些调度模块的核心作用就是对有限的资源进行分配,以实现最大化资源的利用率或者降低系统的尾延迟,调度系统面对的就是资源的需求和供给不平衡的问题。
图 3 - 调度器的任务和资源
我们在这一节中将从多个方面介绍调度系统设计时需要重点考虑的问题,其中包括调度系统的需求调研、调度原理以及架构设计。
1. 需求调研
在着手构建调度系统之前,首要的工作就是进行详细的需求调研和分析,在这个过程中需要完成以下两件事:
- 调研调度系统的应用场景,深入研究场景中待执行的任务(Work)和能用来执行任务的资源(Resource)的特性;
- 分析调度系统的目的,可能是成本优先、质量优先、最大化资源的利用率等,调度目的一般都是动态的,会随着需求的变化而转变;
应用场景
调度系统应用的场景是我们首先需要考虑的问题,对应用场景的分析至关重要,我们需要深入了解当前场景下待执行任务和能用来执行任务的资源的特点。我们需要分析待执行任务的以下特征:
- 任务是否有截止日期,必须在某个时间点之前完成;
- 任务是否支持抢占,抢占的具体规则是什么;
- 任务是否包含前置的依赖条件;
- 任务是否只能在指定的资源上运行;
- ...
而用于执行任务的资源也可能存在资源不平衡,不同资源处理任务的速度不一致的问题。
资源和任务特点的多样性决定了调度系统的设计,我们在这里举几个简单的例子帮助各位读者理解调度系统需求分析的过程。

图 4 - Linux 操作系统
在操作系统的进程调度器中,待调度的任务就是线程,这些任务一般只会处于正在执行或者未执行(等待或者终止)的状态;而用于处理这些任务的 CPU 往往都是不可再分的,同一个 CPU 在同一时间只能执行一个任务,这是物理上的限制。简单总结一下,操作系统调度器的任务和资源有以下特性:
- 任务 —— Thread。状态简单:只会处于正在执行或者未被执行两种状态;优先级不同:待执行的任务可能有不同的优先级,在考虑优先级的情况下,需要保证不同任务的公平性;
- 资源 —— CPU 时间。资源不可再分:同一时间只能运行一个任务;
在上述场景中,待执行的任务是操作系统调度的基本单位 —— 线程,而可分配的资源是 CPU 的时间。Go 语言的调度器与操作系统的调度器面对的是几乎相同的场景,其中的任务是 Goroutine,可以分配的资源是在 CPU 上运行的线程。

图 5 - 容器编排系统 Kubernetes
除了操作系统和编程语言这种较为底层的调度器之外,容器和计算任务调度在今天也很常见,Kubernetes 作为容器编排系统会负责调取集群中的容器,对它稍有了解的人都知道,Kubernetes 中调度的基本单元是 Pod,这些 Pod 会被调度到节点 Node 上执行:
任务 —— Pod。优先级不同:Pod 的优先级可能不同,高优先级的系统 Pod 可以抢占低优先级 Pod 的资源;有状态:Pod 可以分为无状态和有状态,有状态的 Pod 需要依赖持久存储卷;
- 资源 —— Node。类型不同:不同节点上的资源类型不同,包括 CPU、GPU 和内存等,这些资源可以被拆分但是都属于当前节点;不稳定:节点可能由于突发原因不可用,例如:无网络连接、磁盘损坏等;
调度系统在生活和工作中都很常见,除了上述的两个场景之外,其他需要调度系统的场景包括 cdn 的资源调度、订单调度以及离线任务调度系统等。在不同场景中,我们都需要深入思考任务和资源的特性,它们对系统的设计起者指导作用。
调度目的
在深入分析调度场景后,我们需要理解调度的目的。我们可以将调度目的理解成机器学习中的成本函数(Cost function),确定调度目的就是确定成本函数的定义,调度理论一书中曾经介绍过常见的调度目的,包含以下内容:
- 完成跨度(Makesapan) — 第一个到最后一个任务完成调度的时间跨度;
- 最大延迟(Maximum Lateness) — 超过截止时间最长的任务;
- 加权完成时间的和(Total weighted completion time)— 权重乘完成时间的总和;
- ...
这些都是偏理论的调度的目的,多数业务调度系统的调度目的都是优化与业务联系紧密的指标 — 成本和质量。如何在成本和质量之间达到平衡是需要仔细思考和设计的,由于篇幅所限以及业务场景的复杂,本文不会分析如何权衡成本和质量,这往往都是需要结合业务考虑的事情,不具有足够的相似性。
2. 调度原理
性能优异的调度器是实现特定调度目的前提,我们在讨论调度场景和目的时往往都会忽略调度的额外开销,然而调度器执行时的延时和吞吐量等指标在调度负载较重时是不可忽视的。本节会分析与调度器实现相关的一些重要概念,这些概念能够帮助我们实现高性能的调度器:
- 协作式调度与抢占式调度;
- 单调度器与多调度器;
- 任务分享与任务窃取;
协作式与抢占式
协作式(Cooperative)与抢占式(Preemptive)调度是操作系统中常见的多任务运行策略。这两种调度方法的定义完全不同:
- 协作式调度允许任务执行任意长的时间,直到任务主动通知调度器让出资源;
- 抢占式调度允许任务在执行过程中被调度器挂起,调度器会重新决定下一个运行的任务;

图 6 - 协作式调度与抢占式调度
任务的执行时间和任务上下文切换的额外开销决定了哪种调度方式会带来更好的性能。如下图所示,图 7 展示了一个协作式调度器调度任务的过程,调度器一旦为某个任务分配了资源,它就会等待该任务主动释放资源,图中 4 个任务尽管执行时间不同,但是它们都会在任务执行完成后释放资源,整个过程也只需要 4 次上下文的切换。
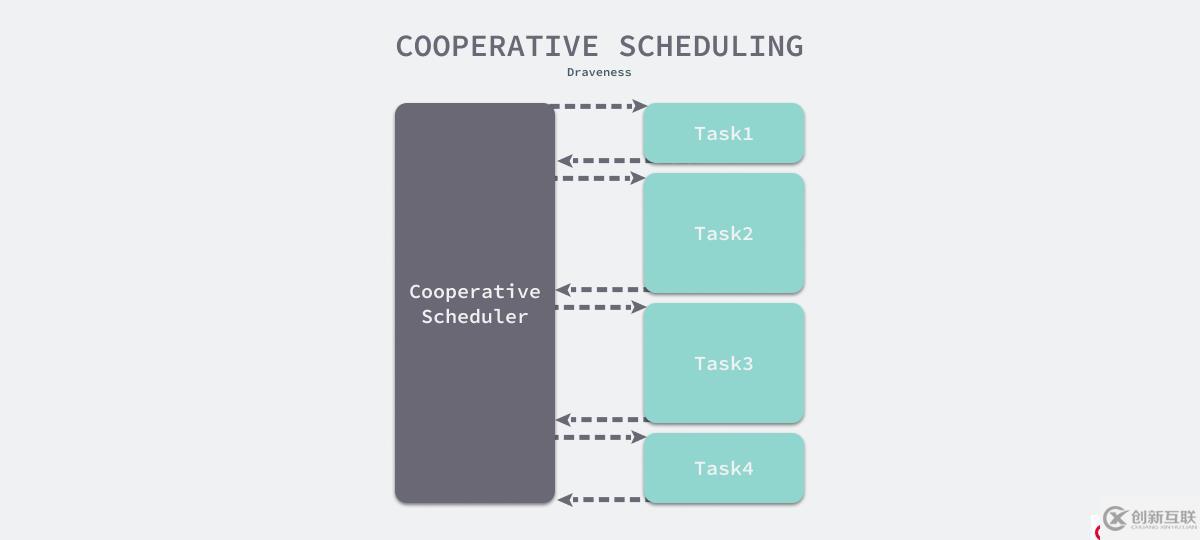
图 7 - 协作式调度
图 8 展示了抢占式调度的过程,由于调度器不知道所有任务的执行时间,所以它为每一个任务分配了一段时间切片。任务 1 和任务 4 由于执行时间较短,所以在第一次被调度时就完成了任务;但是任务 2 和任务 3 因为执行时间较长,超过了调度器分配的上限,所以为了保证公平性会触发抢占,等待队列中的其他任务会获得资源。在整个调度过程中,一共发生了 6 次上下文切换。
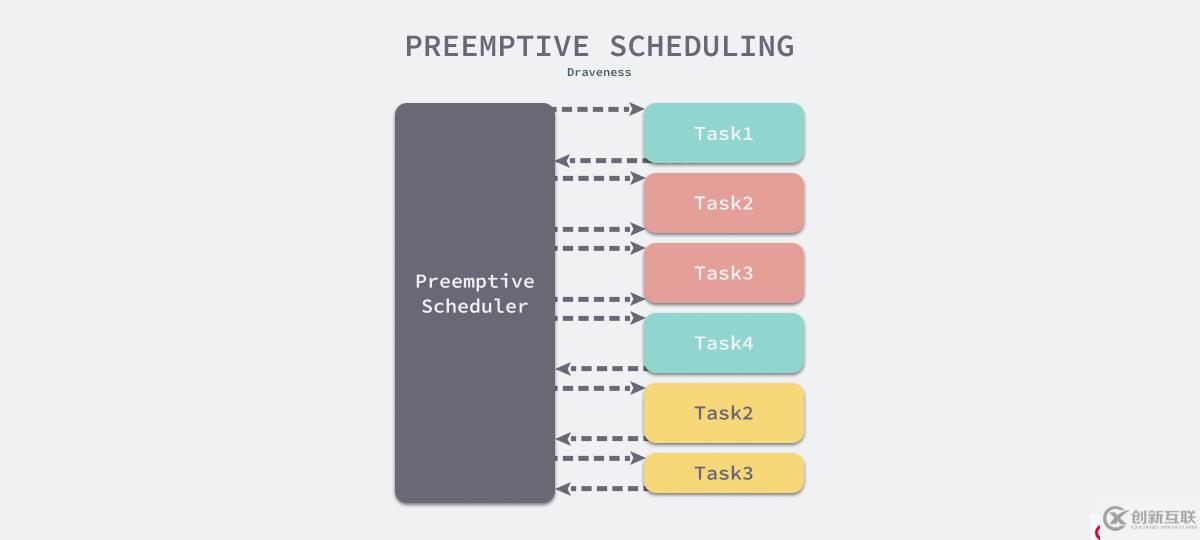
图 8 - 抢占式调度
如果部分任务的执行时间很长,协作式的任务调度会使部分执行时间长的任务饿死其他任务;不过如果待执行的任务执行时间较短并且几乎相同,那么使用协作式的任务调度能减少任务中断带来的额外开销,从而带来更好的调度性能。
因为多数情况下任务执行的时间都不确定,在协作式调度中一旦任务没有主动让出资源,那么就会导致其它任务等待和阻塞,所以调度系统一般都会以抢占式的任务调度为主,同时支持任务的协作式调度。
单调度器与多调度器
使用单个调度器还是多个调度器也是设计调度系统时需要仔细考虑的,多个调度器并不一定意味着多个进程,也有可能是一个进程中的多个调度线程,它们既可以选择在多核上并行调度、在单核上并发调度,也可以同时利用并行和并发提高性能。
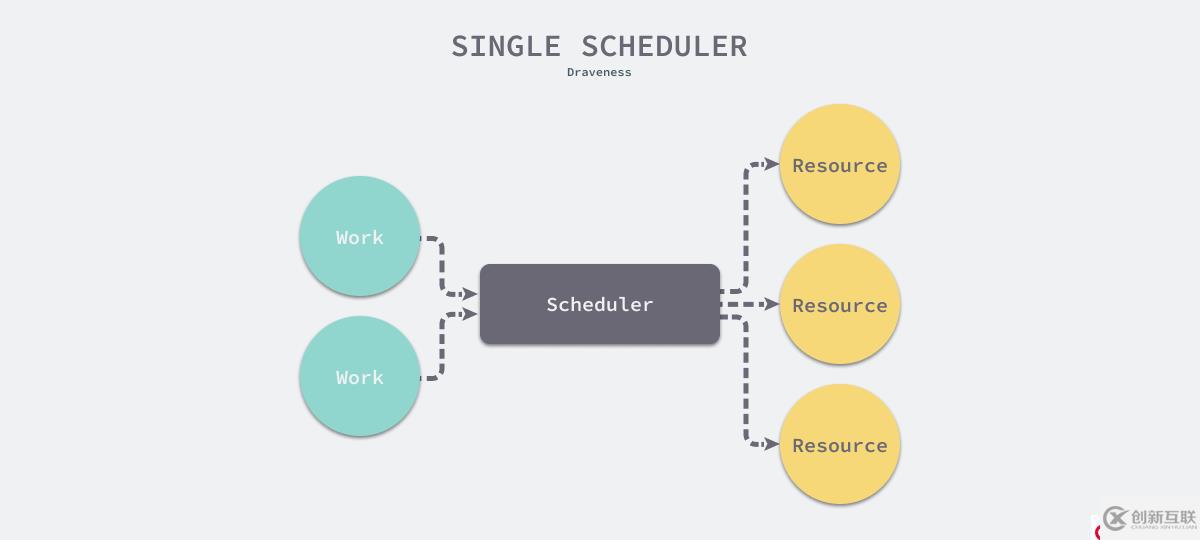
图 9 - 单调度器调度任务和资源
不过对于调度系统来说,因为它做出的决策会改变资源的状态和系统的上下文进而影响后续的调度决策,所以单调度器的串行调度是能够精准调度资源的唯一方法。单个调度器利用不同渠道收集调度需要的上下文,并在收到调度请求后会根据任务和资源情况做出当下最优的决策。
随着调度器的不断演变,单调度器的性能和吞吐量可能会受到限制,我们还是需要引入并行或者并发调度来解决性能上的瓶颈,这时我们需要将待调度的资源分区,让多个调度器分别负责调度不同区域中的资源。
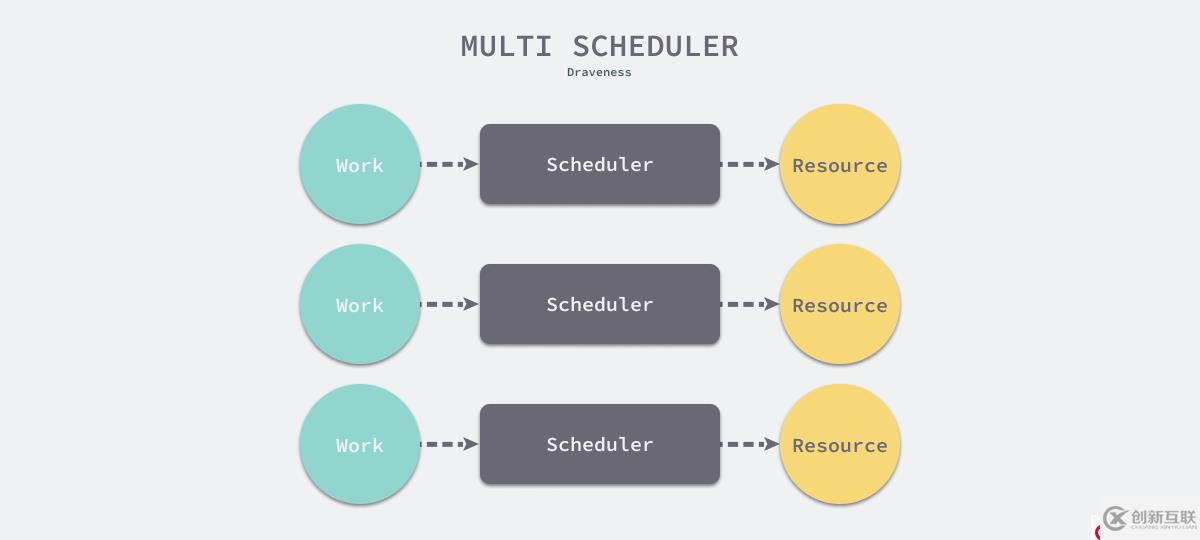
图 10 - 多调度器与资源分区
多调度器的并发调度能够极大提升调度器的整体性能,例如 Go 语言的调度器。Go 语言运行时会将多个 CPU 交给不同的处理器分别调度,这样通过并行调度能够提升调度器的性能。
上面介绍的两种调度方法都建立在需要精准调度的前提下,多调度器中的每一个调度器都会面对无关的资源,所以对于同一个分区的资源,调度还是串行的。
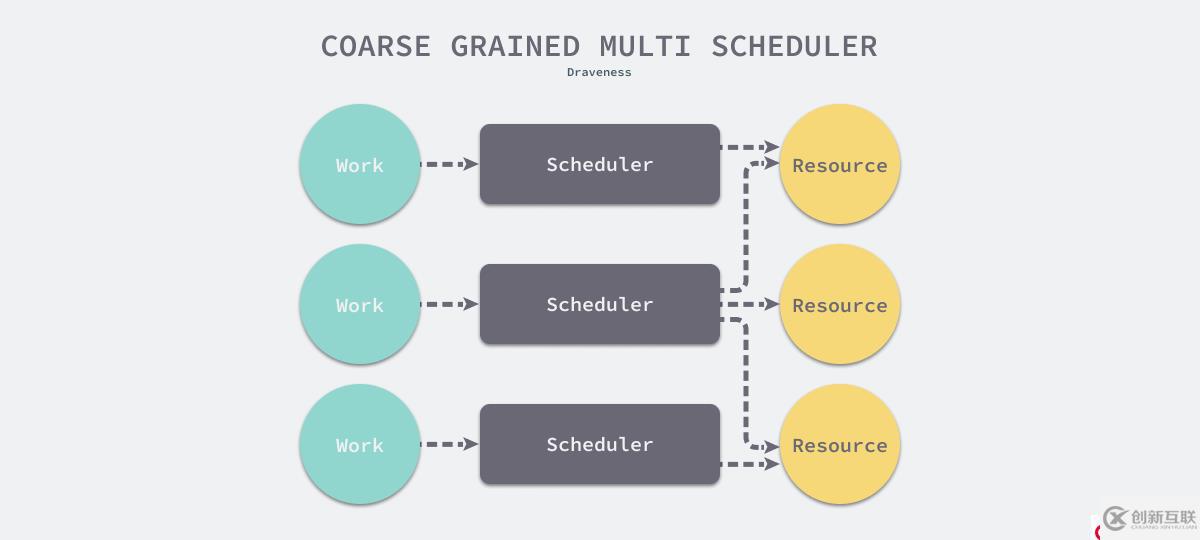
图 11 - 多调度器粗粒度调度
使用多个调度器同时调度多个资源也是可行的,只是可能需要牺牲调度的精确性 — 不同的调度器可能会在不同时间接收到状态的更新,这就会导致不同调度器做出不同的决策。负载均衡就可以看做是多线程和多进程的调度器,因为对任务和资源掌控的信息有限,这种粗粒度调度的结果很可能就是不同机器的负载会有较大差异,所以无论是小规模集群还是大规模集群都很有可能导致某些实例的负载过高。
工作分享与工作窃取
这一小节将继续介绍在多个调度器间重新分配任务的两个调度范式 — 工作分享(Work Sharing)和工作窃取(Work Stealing)。独立的调度器可以同时处理所有的任务和资源,所以它不会遇到多调度器的任务和资源的不平衡问题。在多数的调度场景中,任务的执行时间都是不确定的,假设多个调度器分别调度相同的资源,由于任务的执行时间不确定,多个调度器中等待调度的任务队列最终会发生差异 — 部分队列中包含大量任务,而另外一些队列不包含任务,这时就需要引入任务再分配策略。
工作分享和工作窃取是完全不同的两种再分配策略。在工作分享中,当调度器创建了新任务时,它会将一部分任务分给其他调度器;而在工作窃取中,当调度器的资源没有被充分利用时,它会从其他调度器中窃取一些待分配的任务,如下图所示:
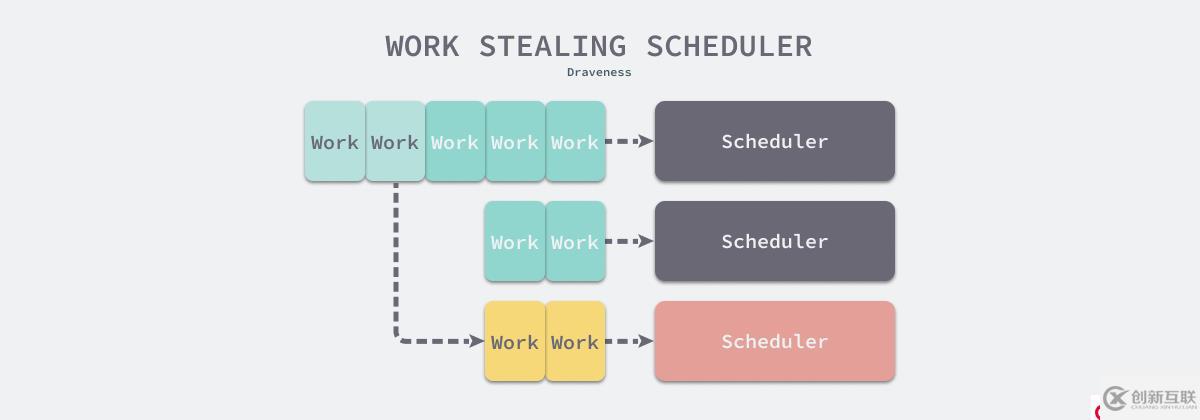
图 12 - 工作窃取调度器
这两种任务再分配的策略都为系统增加了额外的开销,与工作分享相比,工作窃取只会在当前调度器的资源没有被充分利用时才会触发,所以工作窃取引入的额外开销更小。工作窃取在生产环境中更加常用,Linux 操作系统和 Go 语言都选择了工作窃取策略。
3. 架构设计
本节将从调度器内部和外部两个角度分析调度器的架构设计,前者分析调度器内部多个组件的关系和做出调度决策的过程;后者分析多个调度器应该如何协作,是否有其他的外部服务可以辅助调度器做出更合理的调度决策。
调度器内部
当调度器收到待调度任务时,会根据采集到的状态和待调度任务的规格(Spec)做出合理的调度决策,我们可以从下图中了解常见调度系统的内部逻辑。
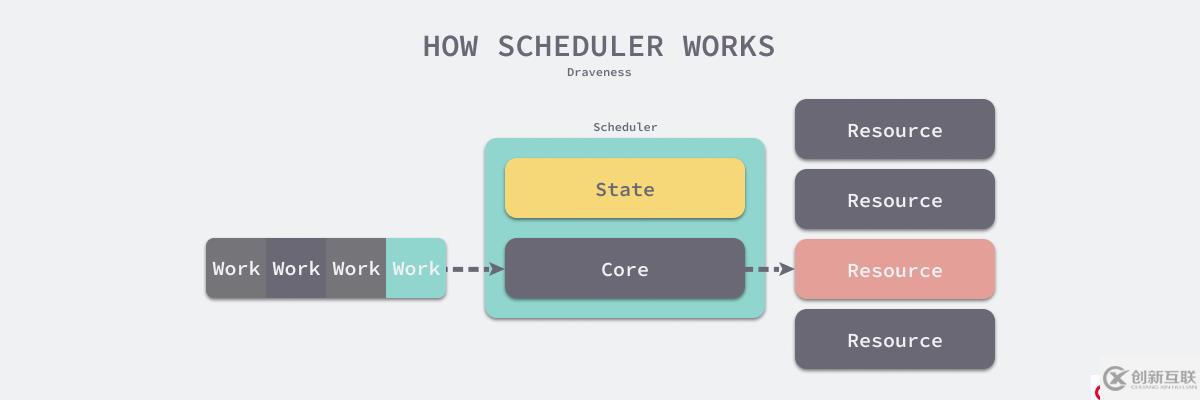
图 13 - 调度器做出调度决策
常见的调度器一般由两部分组成 — 用于收集状态的状态模块和负责做决策的决策模块。
- 状态模块
状态模块会从不同途径收集尽可能多的信息为调度提供丰富的上下文,其中可能包括资源的属性、利用率和可用性等信息。根据场景的不同,上下文可能需要存储在 MySQL 等持久存储中,一般也会在内存中缓存一份以减少调度器访问上下文的开销。
- 决策模块
决策模块会根据状态模块收集的上下文和任务的规格做出调度决策,需要注意的是做出的调度决策只是在当下有效,在未来某个时间点,状态的改变可能会导致之前做的决策不符合任务的需求,例如:当我们使用 Kubernetes 调度器将工作负载调度到某些节点上,这些节点可能由于网络问题突然不可用,该节点上的工作负载也就不能正常工作,即调度决策失效。
调度器在调度时都会通过以下的三个步骤为任务调度合适的资源:
- 通过优先级、任务创建时间等信息确定不同任务的调度顺序;
- 通过过滤和打分两个阶段为任务选择合适的资源;
- 不存在满足条件的资源时,选择牺牲的抢占对象。
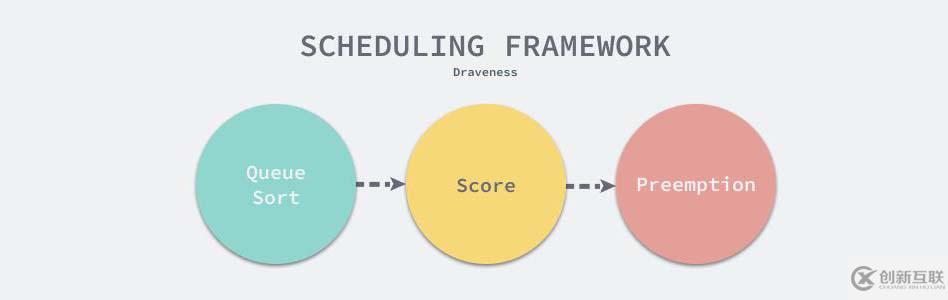
图 14 - 调度框架
上图展示了常见调度器决策模块执行的几个步骤,确定优先级、对闲置资源进行打分、确定抢占资源的牺牲者,上述三个步骤中的最后一个往往都是可选的,部分调度系统不需要支持抢占式调度的功能。
调度器外部
如果我们将调度器看成一个整体,从调度器外部看架构设计就会得到完全不同的角度 — 如何利用外部系统增强调度器的功能。在这里我们将介绍两种调度器外部的设计,分别是多调度器和反调度器(Descheduler)。
- 多调度器
串行调度与并行调度一节已经分析了多调度器的设计,我们可以将待调度的资源进行分区,让多个调度器线程或者进程分别负责各个区域中资源的调度,充分利用多和 CPU 的并行能力。
- 反调度器
反调度器是一个比较有趣的概念,它能够移除决策不再正确的调度,降低系统中的熵,让调度器根据当前的状态重新决策。
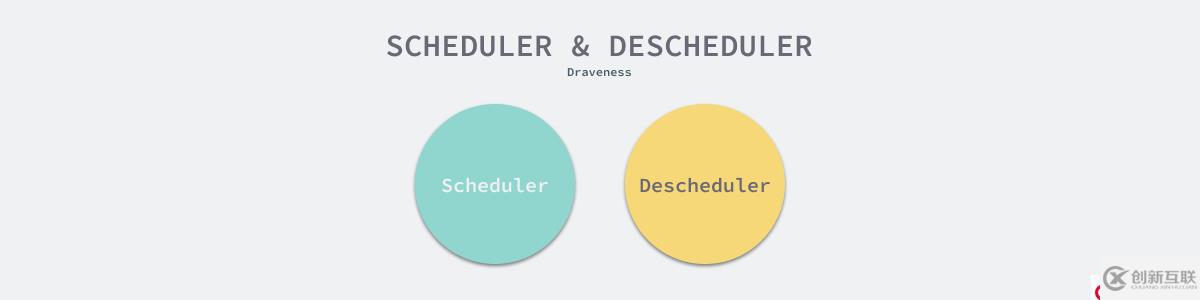
图 15 - 调度器与反调度器
反调度器的引入使得整个调度系统变得更加健壮。调度器负责根据当前的状态做出正确的调度决策,反调度器根据当前的状态移除错误的调度决策,它们的作用看起来相反,但是目的都是为任务调度更合适的资源。
反调度器的使用没有那么广泛,实际的应用场景也比较有限。作者第一次发现这个概念是在 Kubernetes 孵化的descheduler 项目中,不过因为反调度器移除调度关系可能会影响正在运行的线上服务,所以 Kubernetes 也只会在特定场景下使用。
操作系统
调度器是操作系统中的重要组件,操作系统中有进程调度器、网络调度器和 I/O 调度器等组件,本节介绍的是操作系统中的进程调度器。
有一些读者可能会感到困惑,操作系统调度的最小单位不是线程么,为什么这里使用的是进程调度。在 Linux 操作系统中,调度器调度的不是进程也不是线程,它调度的是 task_struct 结构体,该结构体既可以表示线程,也可以表示进程,而调度器会将进程和线程都看成任务,我们在这里先说明这一问题,避免读者感到困惑。我们会使用进程调度器这个术语,但是一定要注意 Linux 调度器中并不区分线程和进程。
Linux incorporates process and thread scheduling by treating them as one in the same. A process can be viewed as a single thread, but a process can contain multiple threads that share some number of resources (code and/or data).
接下来,本节会研究操作系统中调度系统的类型以及 Linux 进程调度器的演进过程。
1. 调度系统类型
操作系统会将进程调度器分成三种不同的类型,即长期调度器、中期调度器和短期调度器。这三种不同类型的调度器分别提供了不同的功能,我们将在这一节中依次介绍它们。
长期调度器
长期调度器(Long-Term Scheduler)也被称作任务调度器(Job Scheduler),它能够决定哪些任务会进入调度器的准备队列。当我们尝试执行新的程序时,长期调度器会负责授权或者延迟该程序的执行。长期调度器的作用是平衡同时正在运行的 I/O 密集型或者 CPU 密集型进程的任务数量:
- 如果 I/O 密集型任务过多,就绪队列中就不存在待调度的任务,短期调度器不需要执行调度,CPU 资源就会面临闲置;
- 如果 CPU 密集型任务过多,I/O 等待队列中就不存在待调度的任务,I/O 设备就会面临闲置;
长期调度器能平衡同时正在运行的 I/O 密集型和 CPU 密集型任务,最大化的利用操作系统的 I/O 和 CPU 资源。
中期调度器
中期调度器会将不活跃的、低优先级的、发生大量页错误的或者占用大量内存的进程从内存中移除,为其他的进程释放资源。
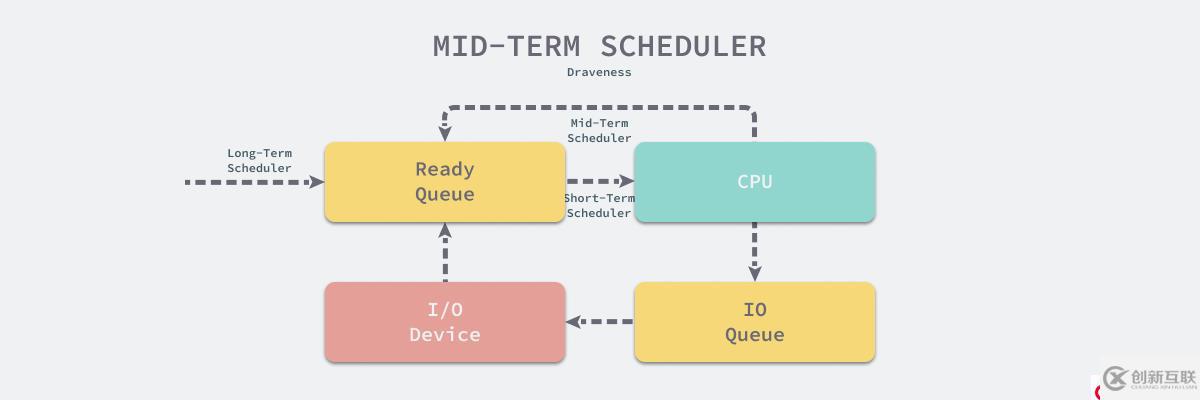
图 16 - 中期调度器
当正在运行的进程陷入 I/O 操作时,该进程只会占用计算资源,在这种情况下,中期调度器就会将它从内存中移除等待 I/O 操作完成后,该进程会重新加入就绪队列并等待短期调度器的调度。
短期调度器
短期调度器应该是我们最熟悉的调度器,它会从就绪队列中选出一个进程执行。进程的选择会使用特定的调度算法,它会同时考虑进程的优先级、入队时间等特征。因为每个进程能够得到的执行时间有限,所以短期调度器的执行十分频繁。
2. 设计与演进
本节将重点介绍 Linux 的 CPU 调度器,也就是短期调度器。Linux 的 CPU 调度器并不是从设计之初就是像今天这样复杂的,在很长的一段时间里(v0.01 ~ v2.4),Linux 的进程调度都由几十行的简单函数负责,我们先了解一下不同版本调度器的历史:
初始调度器 · v0.01 ~ v2.4。由几十行代码实现,功能非常简陋;同时最多处理 64 个任务;
调度器 · v2.4 ~ v2.6。调度时需要遍历全部任务当待执行的任务较多时,同一个任务两次执行的间隔很长,会有比较严重的饥饿问题;
调度器 · v2.6.0 ~ v2.6.22。通过引入运行队列和优先数组实现 的时间复杂度;使用本地运行队列替代全局运行队列增强在对称多处理器的扩展性;引入工作窃取保证多个运行队列中任务的平衡;
- 完全公平调度器 · v2.6.23 ~ 至今。引入红黑树和运行时间保证调度的公平性;引入调度类实现不同任务类型的不同调度策略;
这里会详细介绍从最初的调度器到今天复杂的完全公平调度器(Completely Fair Scheduler,CFS)的演变过程。
初始调度器
Linux 最初的进程调度器仅由 sched.h 和 sched.c 两个文件构成。你可能很难想象 Linux 早期版本使用只有几十行的 schedule 函数负责了操作系统进程的调度:
void schedule(void) {
int i,next,c;
struct task_struct ** p;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) {
...
}
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p) continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;
}
switch_to(next);
}无论是进程还是线程,在 Linux 中都被看做是 task_struct 结构体,所有的调度进程都存储在上限仅为 64 的数组中,调度器能够处理的进程上限也只有 64 个。

图 17 - 最初的进程调度器
上述函数会先唤醒获得信号的可中断进程,然后从队列倒序查找计数器 counter 最大的可执行进程,counter 是进程能够占用的时间切片数量,该函数会根据时间切片的值执行不同的逻辑:
- 如果最大的 counter 时间切片大于 0,调用汇编语言的实现的 switch_to 切换进程;
- 如果最大的 counter 时间切片等于 0,意味着所有进程的可执行时间都为 0,那么所有进程都会获得新的时间切片;
Linux 操作系统的计时器会每隔 10ms 触发一次 do_timer 将当前正在运行进程的 counter 减一,当前进程的计数器归零时就会重新触发调度。
O(n)调度器
调度器是 Linux 在 v2.4 ~ v2.6 版本使用的调度器,由于该调取器在最坏的情况下会遍历所有的任务,所以它调度任务的时间复杂度就是 。Linux 调度算法将 CPU 时间分割成了不同的时期(Epoch),也就是每个任务能够使用的时间切片。
我们可以在 sched.h 和 sched.c 两个文件中找到调度器的源代码。与上一个版本的调度器相比, 调度器的实现复杂了很多,该调度器会在 schedule 函数中遍历运行队列中的所有任务并调用 goodness 函数分别计算它们的权重获得下一个运行的进程:
asmlinkage void schedule(void){
...
still_running_back:
list_for_each(tmp, &runqueue_head) {
p = list_entry(tmp, struct task_struct, run_list);
if (can_schedule(p, this_cpu)) {
int weight = goodness(p, this_cpu, prev->active_mm);
if (weight > c)
c = weight, next = p;
}
}
...
}在每个时期开始时,上述代码都会为所有的任务计算时间切片,因为需要执行 n 次,所以调度器被称作 调度器。在默认情况下,每个任务在一个周期都会分配到 200ms 左右的时间切片,然而这种调度和分配方式是 调度器的最大问题:
- 每轮调度完成之后就会陷入没有任务需要调度的情况,需要提升交互性能的场景会受到严重影响,例如:在桌面拖动鼠标会感觉到明显的卡顿;
- 每次查找权重最高的任务都需要遍历数组中的全部任务;
- 调度器分配的平均时间片大小为 210ms,当程序中包含 100 个进程时,同一个进程被运行两次的间隔是 21s,这严重影响了操作系统的可用性.
正是因为调度器存在了上述的问题,所以 Linux 内核在两个版本后使用新的 调度器替换该实现。
O(1)调度器
调度器在 v2.6.0 到 v2.6.22 的 Linux 内核中使用了四年的时间,它能够在常数时间内完成进程调度,你可以在sched.h 和 sched.c 中查看 调度器的源代码。因为实现和功能复杂性的增加,调度器的代码行数从 的 2100 行增加到 5000 行,它在调度器的基础上进行了如下的改进:
- 调度器支持了 时间复杂度的调度;
- 调度器支持了对称多处理(Symmetric multiprocessing,SMP)的扩展性;
- 调度器优化了对称多处理的亲和性。
数据结构
调度器通过运行队列 runqueue 和优先数组 prio_array 两个重要的数据结构实现了 的时间复杂度。每一个运行队列都持有两个优先数组,分别存储活跃的和过期的进程数组:
struct runqueue {
...
prio_array_t *active, *expired, arrays[2];
...
}
struct prio_array {
unsignedint nr_active;
unsignedlong bitmap[BITMAP_SIZE];
struct list_head queue[MAX_PRIO];
};优先数组中的 nr_active 表示活跃的进程数,而 bitmap 和 list_head 共同组成了如下图所示的数据结构:
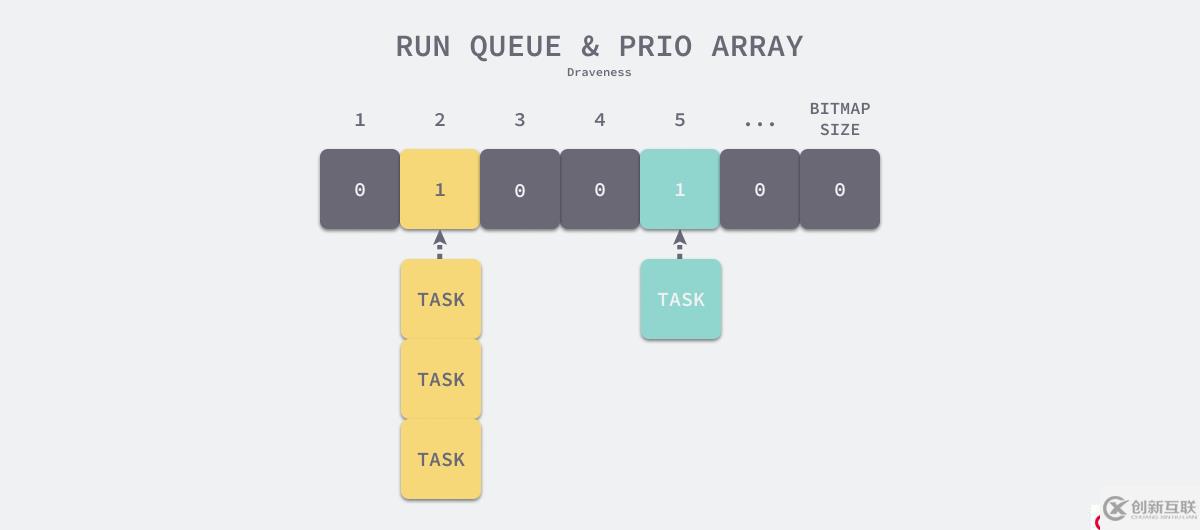
图 18 - 优先数组
优先数组的 bitmap 总共包含 140 位,每一位都表示对应优先级的进程是否存在。图 17 中的优先数组包含 3 个优先级为 2 的进程和 1 个优先级为 5 的进程。每一个优先级的标志位都对应一个 list_head 数组中的链表。 调度器使用上述的数据结构进行如下所示的调度:
- 调用 sched_find_first_bit 按照优先级分配 CPU 资源;
- 调用 schedule 从链表头选择进程执行;
- 通过 schedule 轮训调度同一优先级的进程,该函数在每次选中待执行的进程后,将进程添加到队列的末尾,这样可以保证同一优先级的进程会依次执行(Round-Robin);
- 计时器每隔 1ms 会触发一次 scheduler_tick 函数,如果当前进程的执行时间已经耗尽,就会将其移入过期数组;
- 当活跃队列中不存在待运行的进程时,schedule 会交换活跃优先数组和过期优先数组;
上述的这些规则是 调度器运行遵守的主要规则,除了上述规则之外,调度器还需要支持抢占、CPU 亲和等功能,不过在这里就不展开介绍了。
本地运行队列
全局的运行队列是 调度器难以在对称多处理器架构上扩展的主要原因。为了保证运行队列的一致性,调度器在调度时需要获取运行队列的全局锁,随着处理器数量的增加,多个处理器在调度时会导致更多的锁竞争,严重影响调度性能。 调度器通过引入本地运行队列解决这个问题,不同的 CPU 可以通过 this_rq 获取绑定在当前 CPU 上的运行队列,降低了锁的粒度和冲突的可能性。
#define this_rq() (&__get_cpu_var(runqueues))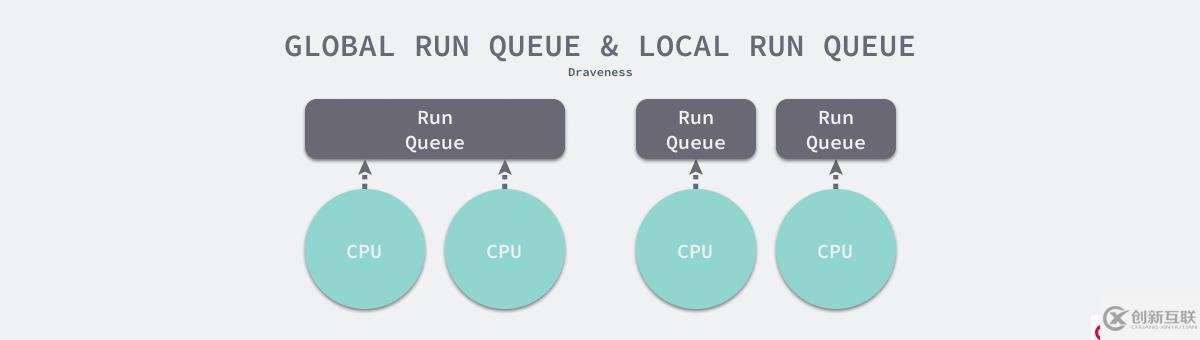
图 19 - 全局运行队列和本地运行队列
多个处理器由于不再需要共享全局的运行队列,所以增强了在对称对处理器架构上的扩展性,当我们增加新的处理器时,只需要增加新的运行队列,这种方式不会引入更多的锁冲突。
优先级和时间切片
调度器中包含两种不同的优先级计算方式,一种是静态任务优先级,另一种是动态任务优先级。在默认情况下,任务的静态任务优先级都是 0,不过我们可以通过系统调用 nice 改变任务的优先级; 调度器会奖励 I/O 密集型任务并惩罚 CPU 密集型任务,它会通过改变任务的静态优先级来完成优先级的动态调整,因为与用户交互的进程时 I/O 密集型的进程,这些进程由于调度器的动态策略会提高自身的优先级,从而提升用户体验。
完全公平调度器
完全公平调度器(Completely Fair Scheduler,CFS)是 v2.6.23 版本被合入内核的调度器,也是内核的默认进程调度器,它的目的是最大化 CPU 利用率和交互的性能。Linux 内核版本 v2.6.23 中的 CFS 由以下的多个文件组成:
- include/linux/sched.h
- kernel/sched_stats.h
- kernel/sched.c
- kernel/sched_fair.c
- kernel/sched_idletask.c
- kernel/sched_rt.c
通过 CFS 的名字我们就能发现,该调度器的能为不同的进程提供完全公平性。一旦某些进程受到了不公平的待遇,调度器就会运行这些进程,从而维持所有进程运行时间的公平性。这种保证公平性的方式与『水多了加面,面多了加水』有一些相似:
- 调度器会查找运行队列中受到最不公平待遇的进程,并为进程分配计算资源,分配的计算资源是与其他资源运行时间的差值加上最小能够运行的时间单位;
- 进程运行结束之后发现运行队列中又有了其他的进程受到了最不公平的待遇,调度器又会运行新的进程;
- ...
调度器算法不断计算各个进程的运行时间并依次调度队列中的受到最不公平对待的进程,保证各个进程的运行时间差不会大于最小运行的时间单位。
数据结构
虽然我们还是会延用运行队列这一术语,但是 CFS 的内部已经不再使用队列来存储进程了,cfs_rq 是用来管理待运行进程的新结构体,该结构体会使用红黑树(Red-black tree)替代链表:
struct cfs_rq {
struct load_weight load;
unsignedlong nr_running;
s64 fair_clock;
u64 exec_clock;
s64 wait_runtime;
u64 sleeper_bonus;
unsignedlong wait_runtime_overruns, wait_runtime_underruns;
struct rb_root tasks_timeline;
struct rb_node *rb_leftmost;
struct rb_node *rb_load_balance_curr;
struct sched_entity *curr;
struct rq *rq;
struct list_head leaf_cfs_rq_list;
};红黑树(Red-black tree)是平衡的二叉搜索树,红黑树的增删改查操作的最坏时间复杂度为 ,也就是树的高度,树中最左侧的节点 rb_leftmost 运行的时间最短,也是下一个待运行的进程。
注:在最新版本的 CFS 实现中,内核使用虚拟运行时间 vruntime 替代了等待时间,但是基本的调度原理和排序方式没有太多变化。
调度过程
CFS 的调度过程还是由 schedule 函数完成的,该函数的执行过程可以分成以下几个步骤:
- 关闭当前 CPU 的抢占功能;
- 如果当前 CPU 的运行队列中不存在任务,调用 idle_balance 从其他 CPU 的运行队列中取一部分执行;
- 调用 pick_next_task 选择红黑树中优先级最高的任务;
- 调用 context_switch 切换运行的上下文,包括寄存器的状态和堆栈;
- 重新开启当前 CPU 的抢占功能。
CFS 的调度过程与 调度器十分类似,当前调度器与前者的区别只是增加了可选的工作窃取机制并改变了底层的数据结构。
调度类
CFS 中的调度类是比较有趣的概念,调度类可以决定进程的调度策略。每个调度类都包含一组负责调度的函数,调度类由如下所示的 sched_class 结构体表示:
struct sched_class {
struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int wakeup);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int sleep);
void (*yield_task) (struct rq *rq, struct task_struct *p);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p);
struct task_struct * (*pick_next_task) (struct rq *rq);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
unsigned long (*load_balance) (struct rq *this_rq, int this_cpu,
struct rq *busiest,
unsigned long max_nr_move, unsigned long max_load_move,
struct sched_domain *sd, enum cpu_idle_type idle,
int *all_pinned, int *this_best_prio);
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p);
void (*task_new) (struct rq *rq, struct task_struct *p);
};调度类中包含任务的初始化、入队和出队等函数,这里的设计与面向对象中的设计稍微有些相似。内核中包含 SCHED_NORMAL、SCHED_BATCH、SCHED_IDLE、SCHED_FIFO 和 SCHED_RR 调度类,这些不同的调度类分别实现了 sched_class 中的函数以提供不同的调度行为。
本文标题:调度系统的设计原理是什么
文章路径:https://www.cdcxhl.com/article46/jsdpeg.html
成都网站建设公司_创新互联,为您提供网站设计公司、外贸建站、网站维护、响应式网站、面包屑导航、网站设计
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
