怎么用Python采集web质量数据到Excel表
本篇内容介绍了“怎么用Python采集web质量数据到Excel表”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
为景宁畲族自治等地区用户提供了全套网页设计制作服务,及景宁畲族自治网站建设行业解决方案。主营业务为成都网站建设、网站制作、景宁畲族自治网站设计,以传统方式定制建设网站,并提供域名空间备案等一条龙服务,秉承以专业、用心的态度为用户提供真诚的服务。我们深信只要达到每一位用户的要求,就会得到认可,从而选择与我们长期合作。这样,我们也可以走得更远!
Python脚本编写前的准备:
下载pycurl模块,直接双击安装即可。
xlsxwriter使用pip命令安装,此处需要注意环境变量是否配置。
1、由于pycurl是下载下来直接安装的,这里就不写了,比较简单。
2、安装xlsxwriter模块(需可连接Internet)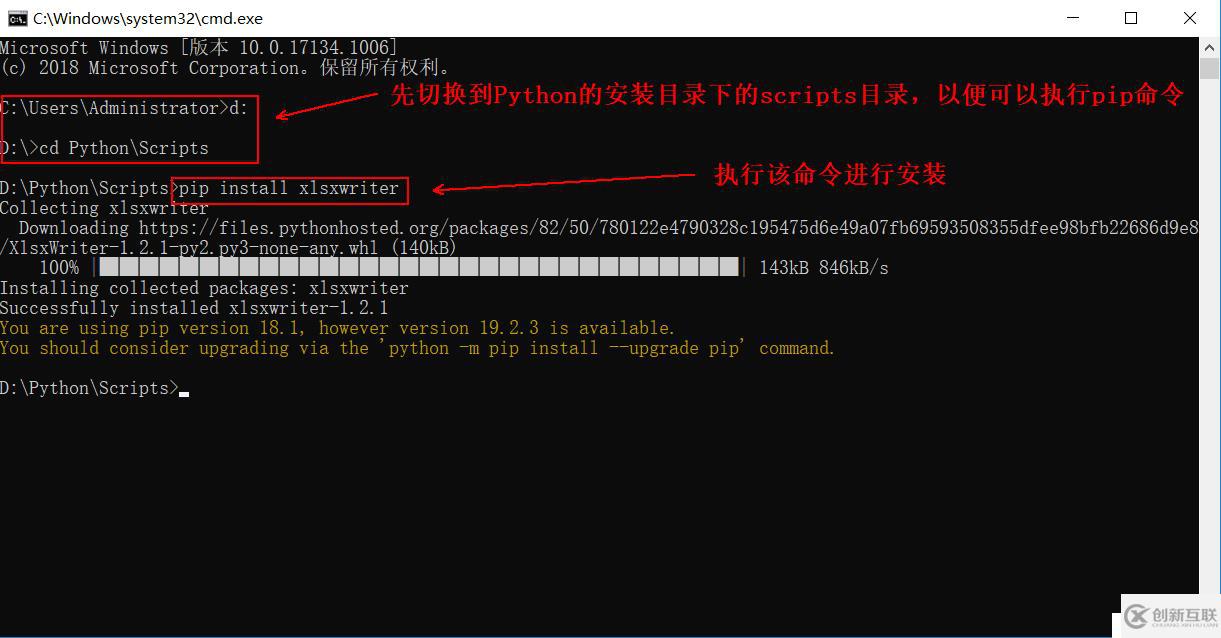
3、采集数据的脚本如下:
# _._ coding:utf-8 _._
import os,sys
import pycurl
import xlsxwriter
URL="www.baidu.com" #探测目标的url,需要探测哪个目标,这里改哪个即可
c = pycurl.Curl() #创建一个curl对象
c.setopt(pycurl.URL, URL) #定义请求的url常量
c.setopt(pycurl.CONNECTTIMEOUT, 10) #定义请求连接的等待时间
c.setopt(pycurl.TIMEOUT, 10) #定义请求超时时间
c.setopt(pycurl.NOPROGRESS, 1) #屏蔽下载进度条
c.setopt(pycurl.FORBID_REUSE, 1) #完成交互后强制断开连接,不重用
c.setopt(pycurl.MAXREDIRS, 1) #指定HTTP重定向的最大数为1
c.setopt(pycurl.DNS_CACHE_TIMEOUT, 30)
#创建一个文件对象,以’wb’方式打开,用来存储返回的http头部及页面内容
indexfile = open(os.path.dirname(os.path.realpath(__file__))+"/content.txt","wb")
c.setopt(pycurl.WRITEHEADER, indexfile) #将返回的http头部定向到indexfile文件
c.setopt(pycurl.WRITEDATA, indexfile) #将返回的html内容定向到indexfile文件
c.perform()
NAMELOOKUP_TIME = c.getinfo(c.NAMELOOKUP_TIME) #获取DNS解析时间
CONNECT_TIME = c.getinfo(c.CONNECT_TIME) #获取建立连接时间
TOTAL_TIME = c.getinfo(c.TOTAL_TIME) #获取传输的总时间
HTTP_CODE = c.getinfo(c.HTTP_CODE) #获取HTTP状态码
SIZE_DOWNLOAD = c.getinfo(c.SIZE_DOWNLOAD) #获取下载数据包大小
HEADER_SIZE = c.getinfo(c.HEADER_SIZE) #获取HTTP头部大小
SPEED_DOWNLOAD=c.getinfo(c.SPEED_DOWNLOAD) #获取平均下载速度
print u"HTTP状态码: %s" %(HTTP_CODE) #输出状态码
print u"DNS解析时间: %.2f ms" %(NAMELOOKUP_TIME*1000) #输出DNS解析时间
print u"建立连接时间: %.2f ms" %(CONNECT_TIME*1000) #输出建立连接时间
print u"传输结束总时间: %.2f ms" %(TOTAL_TIME*1000) #输出传输结束总时间
print u"下载数据包大小: %d bytes/s" %(SIZE_DOWNLOAD) #输出下载数据包大小
print u"HTTP头部大小: %d byte" %(HEADER_SIZE) #输出HTTP头部大小
print u"平均下载速度: %d bytes/s" %(SPEED_DOWNLOAD) #输出平均下载速度
indexfile.close() #关闭文件
c.close() #关闭curl对象
f = file('chart.txt','a') #打开一个chart.txt文件,以追加的方式
f.write(str(HTTP_CODE)+','+str(NAMELOOKUP_TIME*1000)+','+str(CONNECT_TIME*1000)+','+str(TOTAL_TIME*1000)+','+str(SIZE_DOWNLOAD/1024)+','+str(HEADER_SIZE)+','+str(SPEED_DOWNLOAD/1024)+'\n') #将上面输出的结果写入到chart.txt文件
f.close() #关闭chart.txt文件
workbook = xlsxwriter.Workbook('chart.xlsx') #创建一个chart.xlsx的excel文件
worksheet = workbook.add_worksheet() #创建一个工作表对象,默认为Sheet1
chart = workbook.add_chart({'type': 'column'}) #创建一个图表对象
title = [URL , u' HTTP状态码',u' DNS解析时间',u' 建立连接时间',u' 传输结束时间',u' 下载数据包大小',u' HTTP头部大小',u' 平均下载速度'] #定义数据表头列表
format=workbook.add_format() #定义format格式对象
format.set_border(1) #定义format对象单元格边框加粗(1像素)的格式
format_title=workbook.add_format() #定义format_title格式对象
format_title.set_border(1) #定义format_title对象单元格边框加粗(1像素)的格式
format_title.set_bg_color('#00FF00') #定义format_title对象单元格背景颜色为’#cccccc’
format_title.set_align('center') #定义format_title对象单元格居中对齐的格式
format_title.set_bold() #定义format_title对象单元格内容加粗的格式
worksheet.write_row(0, 0,title,format_title) #将title的内容写入到第一行
f = open('chart.txt','r') #以只读的方式打开chart.txt文件
line = 1 #定义变量line等于1
for i in f: #开启for循环读文件
head = [line] #定义变量head等于line
lineList = i.split(',') #将字符串转化为列表形式
lineList = map(lambda i2:int(float(i2.replace("\n", ''))), lineList) #将列表中的最后\n删除,将小数点后面的数字删除,将浮点型转换成整型
lineList = head + lineList #两个列表相加
worksheet.write_row(line, 0, lineList, format) #将数据写入到execl表格中
line += 1
average = [u'平均值', '=AVERAGE(B2:B' + str((line - 1)) +')', '=AVERAGE(C2:C' + str((line - 1)) +')', '=AVERAGE(D2:D' + str((line - 1)) +')', '=AVERAGE(E2:E' + str((line - 1)) +')', '=AVERAGE(F2:F' + str((line - 1)) +')', '=AVERAGE(G2:G' + str((line - 1)) +')', '=AVERAGE(H2:H' + str((line - 1)) +')'] #求每一列的平均值
worksheet.write_row(line, 0, average, format) #在最后一行数据下面写入平均值
f.close() #关闭文件
def chart_series(cur_row, line): #定义一个函数
chart.add_series({
'categories': '=Sheet1!$B$1:$H$1', #将要输出的参数作为图表数据标签(X轴)
'values': '=Sheet1!$B$'+cur_row+':$H$'+cur_row, #获取B列到H列的数据
'line': {'color': 'black'}, #线条颜色定义为black
'name': '=Sheet1!$A'+ cur_row, #引用业务名称为图例项
})
for row in range(2, line + 1): #从第二行开始到最后一次取文本中的行的数据系列函数调用
chart_series(str(row), line)
chart.set_size({'width':876,'height':287}) #定义图表的宽度及高度
worksheet.insert_chart(line + 2, 0, chart) #在最后一行数据下面的两行处插入图表
workbook.close() #关闭execl文档4、运行脚本后,会在脚本所在的目录下产生三个文件,两个是txt文本文件,一个是Excel文件,执行脚本后,会显示如下信息:
5、当前目录下产生的文件如下:
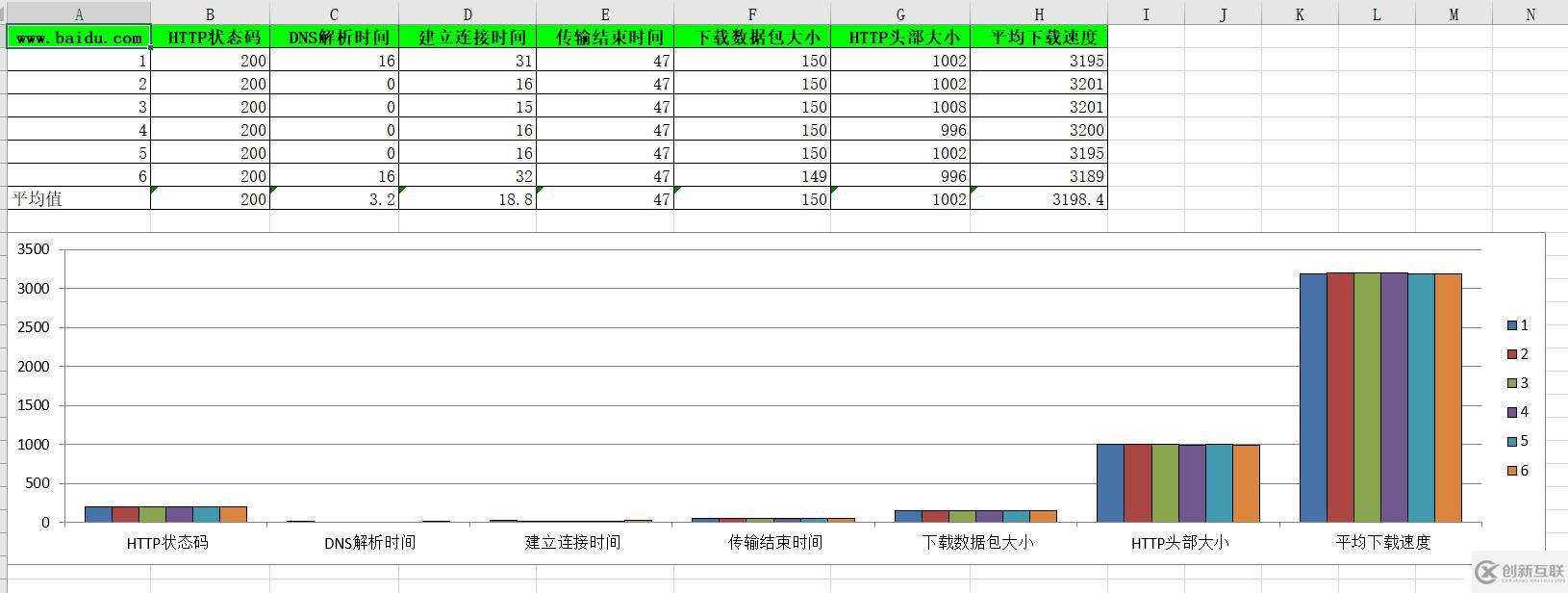
其中,两个txt格式的文件都是为了给Excel做铺垫的,所以可以选择性忽略即可,主要是看Excel中的数据。Excel中的数据如下(以下是执行6次脚本后的显示结果,也就是说探测了6次):
“怎么用Python采集web质量数据到Excel表”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注创新互联网站,小编将为大家输出更多高质量的实用文章!
本文标题:怎么用Python采集web质量数据到Excel表
分享地址:https://www.cdcxhl.com/article46/jdhjeg.html
成都网站建设公司_创新互联,为您提供品牌网站建设、营销型网站建设、网站策划、手机网站建设、网站维护、网站收录
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 网站制作时需做好充分的准备工作 2021-08-20
- 浅谈营销型网站内容建设需要注意哪些问题 2022-06-23
- 如何解决北京建站公司长期生存的问题? 2016-08-10
- 如何将电子商务网站制作得让人眼前一亮? 2016-11-13
- 网站制作如何创造有效的外部链接 2021-10-05
- 【网站建设】导致公司网站制作失败的原因有哪些? 2022-05-06
- 什么是企业网站制作中的可用性设计 2021-09-12
- 网站制作如何不成为摆设 2015-04-01
- 成都网站制作的价格受到哪些因素影响? 2016-10-16
- 企业官方网站制作需要那些步骤? 2016-11-10
- 网页页面有没有「百度收录」? 2015-11-18
- 手机版网站和手机微站之间的不同 2016-11-16