Java大数据开发中ZooKeeper的原理机制是什么
本篇文章为大家展示了Java大数据开发中ZooKeeper的原理机制是什么,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
在金东等地区,都构建了全面的区域性战略布局,加强发展的系统性、市场前瞻性、产品创新能力,以专注、极致的服务理念,为客户提供网站制作、成都网站建设 网站设计制作按需网站制作,公司网站建设,企业网站建设,成都品牌网站建设,全网整合营销推广,成都外贸网站建设公司,金东网站建设费用合理。
1.1 参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
① tickTime =2000:通信心跳数,Zookeeper服务器与客户端心跳时间,单位毫秒
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间2*tickTime)
② initLimit =10:LF初始通信时限
集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心跳数(tickTime的数量),用它来限定集群中的Zookeeper服务器连接到Leader的时限。
③ syncLimit =5:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
④ dataDir:数据文件目录+数据持久化路径
主要用于保存Zookeeper中的数据。
⑤ clientPort =2181:客户端连接端口
监听客户端连接的端口。
1.2 内部原理
1.2.1 选举机制
半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器。
Zookeeper虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为Leader,其他机器则为Follower,Leader是通过内部的选举机制临时产生的。
下图是由五台服务器组成的ZK集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么!
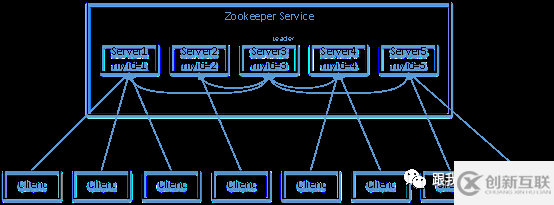
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报文没有任何响应,所以它的选举状态一直是LOOKING状态;
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态;
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的Leader;
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了;
(5)服务器5启动,同4一样当小弟。
1.2.2 节点类型
① Znode有两种类型:
短暂(ephemeral):客户端和服务器端断开连接后,创建的节点自己删除
持久(persistent):客户端和服务器端断开连接后,创建的节点不删除
② Znode有四种形式的目录节点(默认是persistent )
第一、持久化目录节点(PERSISTENT)
客户端与zookeeper断开连接后,该节点依旧存在;
第二、持久化顺序编号目录节点(PERSISTENT_SEQUENTIAL)客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号;
第三、临时目录节点(EPHEMERAL)
客户端与zookeeper断开连接后,该节点被删除;
第四、临时顺序编号目录节点(EPHEMERAL_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号。
1.2.3 监听原理
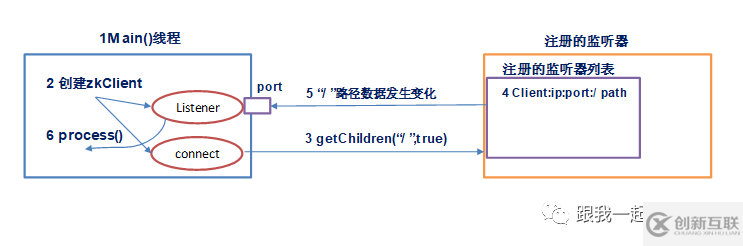
(1)在Zookeeper的API操作中,创建main()主方法即主线程;
(2)在main线程中创建Zookeeper客户端(zkClient),这时会创建两个线程:
线程connet负责网络通信连接,连接服务器;
线程Listener负责监听;
(3)客户端通过connet线程连接服务器,图中getChildren("/" , true) ," / "表示监听的是根目录,true表示监听,不监听用false;
(4)在Zookeeper的注册监听列表中将注册的监听事件添加到列表中,表示这个服务器中的/path,即根目录这个路径被客户端监听了;
(5)一旦被监听的服务器根目录下,数据或路径发生改变,Zookeeper就会将这个消息发送给Listener线程;
(6)Listener线程内部调用process方法,采取相应的措施,例如更新服务器列表等。
监听类型:
(1)监听节点数据的变化:get path [watch]
(2)监听子节点增减的变化:ls patch [watch]
1.2.4 数据写入
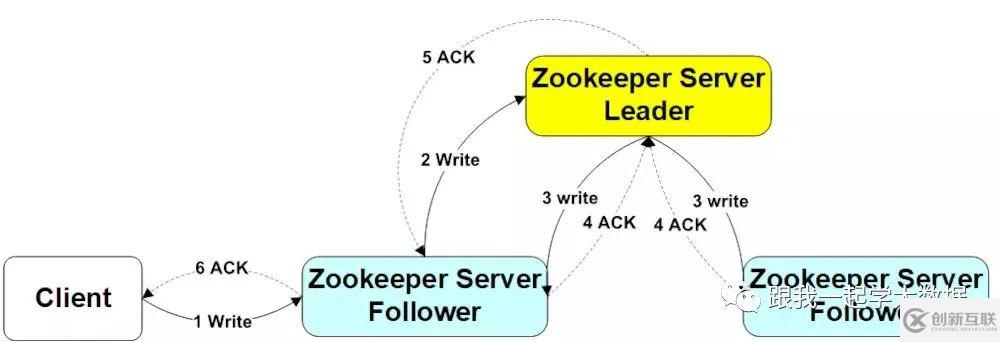
(1)Client向Zookeeper的其中一个Server上写数据,发送一个写请求;
(2)如果那个Server不是Leader,那么Server会把接收到的请求进一步转发给Leader,这个Leader会把写请求广播给各个server,各个Server写成功后就会通知Leader;
(3)当Leader收到大多数Server数据写成功了,那么就说明数据写成功了,比如三个节点,只要两个节点数据写成功了,就认为数据写成功了;
(4)Server1会通知Client数据写成功了,这时就认为整个写操作成功。
上述内容就是Java大数据开发中ZooKeeper的原理机制是什么,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注创新互联行业资讯频道。
文章名称:Java大数据开发中ZooKeeper的原理机制是什么
转载来源:https://www.cdcxhl.com/article46/iippeg.html
成都网站建设公司_创新互联,为您提供手机网站建设、网站营销、外贸网站建设、网页设计公司、虚拟主机、企业网站制作
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 手机站如何做好客服工作? 2016-11-06
- 分析旅游景点开发小程序的必要性 2022-05-20
- 谈手机app的推广方式 2016-11-05
- 创新互联手机网站seo优化怎么提升排名 2016-12-13
- 手机网站的重要性 2016-09-14
- 成都手机网站建设公司哪家好? 2014-03-29
- 手机网站建设如何吸引用户注意力? 2023-04-01
- 手机网站建设的5个要点 2022-08-15
- 成都手机网站建设,你需要考虑这些…… 2022-07-19
- 手机端的SEO影响有多重要! 2014-07-19
- 成都手机网站建设公司,是怎么做手机网站建设的? 2018-06-12
- 手机网站建设中如何适配电脑端内容 2016-09-12