linux中正则表达式的示例分析-创新互联
这篇文章将为大家详细讲解有关linux中正则表达式的示例分析,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
创新互联服务项目包括双清网站建设、双清网站制作、双清网页制作以及双清网络营销策划等。多年来,我们专注于互联网行业,利用自身积累的技术优势、行业经验、深度合作伙伴关系等,向广大中小型企业、政府机构等提供互联网行业的解决方案,双清网站推广取得了明显的社会效益与经济效益。目前,我们服务的客户以成都为中心已经辐射到双清省份的部分城市,未来相信会继续扩大服务区域并继续获得客户的支持与信任!正则表达式应用非常广泛,例如:php,Python,java等,但在linux中最常用的正则表达式的命令就是grep(egrep),sed,awk等,换句话 说linux三剑客要想能工作的更高效,就一定离不开正则表达式的配合。
1、什么是正则表达式?
简单的说,正则表达式就是为处理大量的字符串而定义的一套规则和方法。通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤、替换或者输出需要的字符串。linux正则表达式一般以行为单位处理的。
2、为什么要学正则表达式
在企业工作中,我们每天做的linux运维工作中,时刻都会面对大量带有字符串的文本配置、程序、命令输出及日志文件等,而我们经常会有迫切的需要从大量的字符串内容中查找符合工作需要的特定字符串,这就要靠正则表达式,因此,可以说正则表达式就是为过滤这样字符串的需求而生的!
3、容易混淆的两个注意事项:
1)linux正则表达式一般是以行为单位处理的。
2)正则表达式和我们常用的通配符特殊字符是有本质区别的,例如:ls *.txt 这里的*就是通配符(表示所有),不是正则表达式。
注意字符集问题:
确保字符集:export LC_ALL=C
---------------------------------------------
基础正则表达式+扩展正则表达式含义解释:
---------------------------------------------
. 代表且只能代表任意一个字符(不包括空行)
* 重复前面任意0个或多个字符
.* 匹配所有字符。(包括空行)
sed -ri 's#(.*)#\1#g' bqh.txt
把前面正则匹配的括号内的结果,在后面用\1取出来操作。
^ 表示以什么开头,^bqh 以bqh开头
$ 是以什么结尾
^$ 表示空行。
\ 例\. 就只代表点本身,转义符号,让有着特殊身份移动的字符,脱掉马甲,还原原型\$
^.* 以任意多个字符开头。
.*$ 以任意多个字符结尾。
(.*) 从第一字符匹配,到空格停止,
[abc] 匹配字符集合内的任意一个字符【a-zA-Z】
[^abc] 匹配不包括^后的任意字符的内容;中括号里的^为取反,注意和以...开头区别。
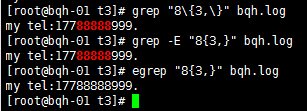
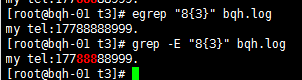
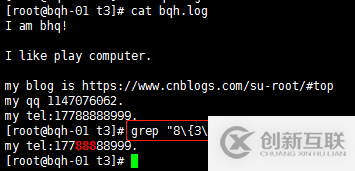
a\{n,m\} 重复n到m次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
\{n,\} 重复至少n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
\{n\} 重复n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
①^word 搜索以word开头的;vi ^ 一行的开够
②word$ 搜索以word结尾的;vi $ 一行的开头
③^$ 表示空行。
扩展的正则表达式:ERP(egrep或grep -E)
+ 重复一个或一个以上前面的字符
? 复0个或一个0前面的字符
| 用或的方式查找多个符合的字符串
() 找出“用户组”字符串
实战举例:
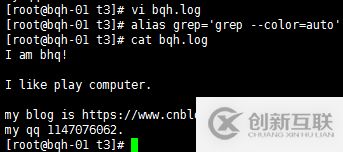
^m 搜索以m开头的

p$搜索以p结尾的

^$表示空号
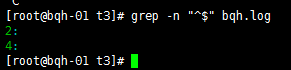
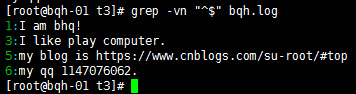
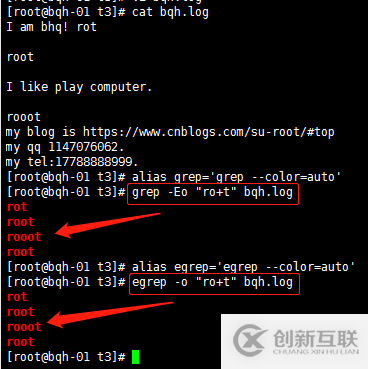
去掉空行:grep –v “^$” bqh.log
查看去掉的后的空行内容:grep -vn “^$” bqh.log
. 代表且只能代表任意一个字符(不包括空行)
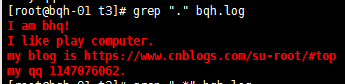
查找带0的字符:

.* 匹配所有字符。(包括空行)
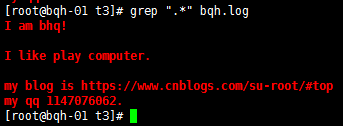
查找以.结尾的字符:
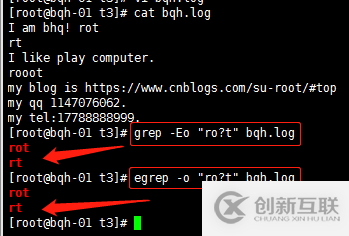
错误方法:grep ".$" bqh.log
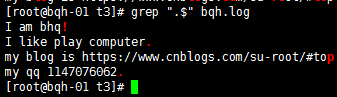
正确方法:
grep “\.$” bqh.log
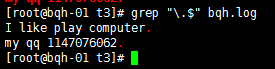
注意:\. 就只代表点本身,转义符号,让有着特殊身份移动的字符,脱掉马甲,还原原型\$
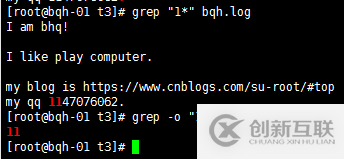
* 例1*重复1个或多个前面的一个字符。
grep –o “1*” bqh.log //-o精确匹配
^.* 以任意多个字符开头。

.*$ 以任意多个字符结尾。

[abc] 匹配字符集合内的任意一个字符【a-zA-Z】
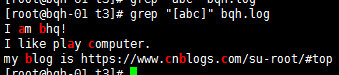
匹配字符集合内的a-z任意一个小写字符:
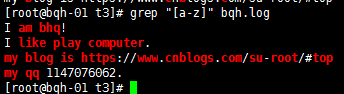
[^abc] 匹配不包括^后的任意字符的内容;中括号里的^为取反,注意和以...开头区别
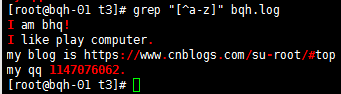
匹配非数字的任意字符:
a\{n,m\} 重复n到m次,前一个重复的字符。如果有用egrep/sed -r /grep -E可以去掉斜线。
\{n,\} 重复至少n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
\{n\} 重复n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
注意:egrep,grep -E或sed -r过滤一般特殊字符可以不转义。多使用参数。
---------------------------------------------------------------------------------
扩展的正则表达式:ERP(egrep或grep -E)
+ 重复一个或一个以上前面的字符
? 复0个或一个0前面的字符
| 用或的方式查找多个符合的字符串
() 找出“用户组”字符串
关于“linux中正则表达式的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
文章题目:linux中正则表达式的示例分析-创新互联
URL分享:https://www.cdcxhl.com/article46/ceeohg.html
成都网站建设公司_创新互联,为您提供网站营销、网站制作、网站设计公司、建站公司、品牌网站设计、全网营销推广
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 成都网站建设:移动网站建设和微官网建设有哪些区别 2017-01-08
- 移动网站建设方案 2022-06-20
- 移动网站建设在技术上并不完美 2022-12-19
- 移动网站建设:从浏览者的角度提出几点优化建议 2021-07-26
- 移动网站建设过程及注意事项! 2022-09-25
- 中小企业网站移动网站建设有哪些好处? 2016-11-27
- 移动网站建设与搜索引擎的关系 2016-11-07
- 移动网站建设常见问题集锦 2016-11-08
- 深度好文教你移动网站建设技巧 2021-04-29
- 手机端移动网站建设需要注意哪些问题呢? 2013-12-19
- 分析企业移动网站建设的必要性! 2016-12-13
- 移动网站建设与电脑端网站建设有何不同?应如何提高用户体验? 2022-10-28