为PXC集群引入Mycat并构建完整的高可用集群架构
MySQL集群中间件比较
在CentOS8下搭建PXC集群一文中,演示了如何从零开始搭建一个三节点的PXC集群。但是光搭建了PXC集群还不够,因为在实际的企业应用中,可能会存在多个PXC集群,每个集群作为一个数据分片存在。因此,在完整的架构下我们还需要为集群引入数据库中间件,以实现数据分片和负载均衡等功能。
创新互联IDC提供业务:成都服务器托管,成都服务器租用,成都服务器托管,重庆服务器租用等四川省内主机托管与主机租用业务;数据中心含:双线机房,BGP机房,电信机房,移动机房,联通机房。
市面上有许多的数据库中间件,这些中间件主要分为两种类型,负载均衡型和数据切分型(通常数据切分型会具备负载均衡功能):
- 负载均衡型:
- Haproxy
- MySQL - Proxy
- 数据切分型:
- MyCat
- Atlas
- OneProxy
- ProxySQL
负载均衡型中间件的作用:
- 负载均衡提供了请求转发,可以将请求均匀的转发到集群中的各个节点上,降低了单节点的负载
- 使得我们可以充分利用到集群中的各个节点的资源,以发挥集群的性能
数据切分型中间件的作用:
- 按照不同的路由算法分发SQL语句,让不同的分片可以存储不同的数据,这样就形成了数据切分
- 让数据均匀的存储在不同的分片上,避免某一个分片的数据量超过数据库的存储极限。这里的分片指的是一个集群或一个数据库节点
以下是对常见的中间件进行的一个比较:
| 名称 | 是否开源免费 | 负载能力 | 开发语言 | 功能 | 文档 | 普及率 |
|---|---|---|---|---|---|---|
| MyCat | 开源免费 | 基于阿里巴巴的Corba中间件重构而来,有高访问量的检验 | Java | 功能全面,有丰富的分片算法以及读写分离、全局主键和分布式事务等功能 | 文档丰富,不仅有官方的《Mycat权威指南》,还有许多社区贡献的文档 | 电信、电商领域均有应用,是国内普及率最高的MySQL中间件 |
| Atlas | 开源免费 | 基于MySQL Proxy,主要用于360产品,有每天承载几十亿次请求的访问量检验 | C语言 | 功能有限,实现了读写分离,具有少量的数据切分算法,不支持全局主键和分布式事务 | 文档较少,只有开源项目文档,无技术社区和出版物 | 普及率低,除了奇虎360外,仅在一些中小型项目在使用,可供参考的案例不多 |
| OneProxy | 分为免费版和企业版 | 基于C语言的内核,性能较好 | C语言 | 功能有限,实现了读写分离,具有少量的数据切分算法,不支持全局主键和分布式事务 | 文档较少,官网不提供使用文档,无技术社区和出版物 | 普及率低,仅仅在一些中小型企业的内部系统中使用过 |
| ProxySQL | 开源免费 | 性能出众,Percona推荐 | C++ | 功能相对丰富,支持读写分离、数据切分、故障转移及查询缓存等 | 文档丰富,有官方文档和技术社区 | 普及率相比于Mycat要低,但已有许多公司尝试使用 |
配置Mycat数据切分
经过上一小节的介绍与比较,可以看出MyCat与ProxySQL是比较理想的数据库中间件。由于MyCat相对于ProxySQL功能更全面,普及率也更高一些,所以这里采用Mycat来做为PXC集群的中间件。关于Mycat的介绍与安装,可以参考我的另一篇Mycat 快速入门,这里就不再重复了。
本小节主要介绍如何配置Mycat的数据切分功能,让Mycat作为前端的数据切分中间件转发SQL请求到后端的PXC集群分片中。因此,这里我搭建了两个PXC集群,每个集群就是一个分片,以及搭建了两个Mycat节点和两个Haproxy节点用于后面组建双机热备。如图: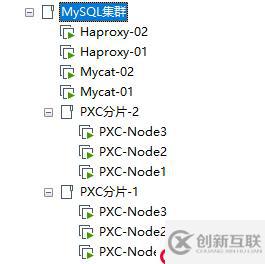
各个节点的信息如下表:
| 角色 | Host | IP |
|---|---|---|
| Haproxy-Master | Haproxy-Master | 192.168.190.140 |
| Haproxy-Backup | Haproxy-Backup | 192.168.190.141 |
| Mycat:Node1 | mycat-01 | 192.168.190.136 |
| Mycat:Node2 | mycat-02 | 192.168.190.135 |
| PXC分片-1:Node1 | PXC-Node1 | 192.168.190.132 |
| PXC分片-1:Node2 | PXC-Node2 | 192.168.190.133 |
| PXC分片-1:Node3 | PXC-Node3 | 192.168.190.134 |
| PXC分片-2:Node1 | PXC-Node1 | 192.168.190.137 |
| PXC分片-2:Node2 | PXC-Node2 | 192.168.190.138 |
| PXC分片-2:Node3 | PXC-Node3 | 192.168.190.139 |
在每个分片里创建一个test库,并在该库中创建一张t_user表用作测试,具体的建表SQL如下:
CREATE TABLE `t_user` (
`id` int(11) NOT NULL,
`username` varchar(20) NOT NULL,
`password` char(36) NOT NULL,
`tel` char(11) NOT NULL,
`locked` char(10) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;完成以上准备后,接着我们开始配置Mycat,如果你对Mycat的配置文件不了解的话,可以参考我另一篇文章:Mycat 核心配置详解,本文就不赘述了。
1、编辑server.xml文件,配置Mycat的访问用户:
<user name="admin" defaultAccount="true">
<property name="password">Abc_123456</property>
<property name="schemas">test</property>
<property name="defaultSchema">test</property>
</user>2、编辑schema.xml文件,配置Mycat的逻辑库、逻辑表以及集群节点的连接信息:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 配置逻辑库 -->
<schema name="test" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<!-- 配置逻辑表 -->
<table name="t_user" dataNode="dn1,dn2" rule="mod-long"/>
</schema>
<!-- 配置数据分片,每个分片都会有一个索引值,从0开始。例如,dn1索引值为0,dn2的索引值为1,以此类推 -->
<!-- 分片的索引与分片算法有关,分片算法计算得出的值就是分片索引 -->
<dataNode name="dn1" dataHost="pxc-cluster1" database="test" />
<dataNode name="dn2" dataHost="pxc-cluster2" database="test" />
<!-- 配置集群节点的连接信息 -->
<dataHost name="pxc-cluster1" maxCon="1000" minCon="10" balance="2"
writeType="1" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="W1" url="192.168.190.132:3306" user="admin"
password="Abc_123456">
<readHost host="W1-R1" url="192.168.190.133:3306" user="admin" password="Abc_123456"/>
<readHost host="W1-R2" url="192.168.190.134:3306" user="admin" password="Abc_123456"/>
</writeHost>
<writeHost host="W2" url="192.168.190.133:3306" user="admin"
password="Abc_123456">
<readHost host="W2-R1" url="192.168.190.132:3306" user="admin" password="Abc_123456"/>
<readHost host="W2-R2" url="192.168.190.134:3306" user="admin" password="Abc_123456"/>
</writeHost>
</dataHost>
<dataHost name="pxc-cluster2" maxCon="1000" minCon="10" balance="2"
writeType="1" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="W1" url="192.168.190.137:3306" user="admin" password="Abc_123456">
<readHost host="W1-R1" url="192.168.190.138:3306" user="admin" password="Abc_123456"/>
<readHost host="W1-R2" url="192.168.190.139:3306" user="admin" password="Abc_123456"/>
</writeHost>
<writeHost host="W2" url="192.168.190.138:3306" user="admin" password="Abc_123456">
<readHost host="W2-R1" url="192.168.190.137:3306" user="admin" password="Abc_123456"/>
<readHost host="W2-R2" url="192.168.190.138:3306" user="admin" password="Abc_123456"/>
</writeHost>
</dataHost>
</mycat:schema>3、编辑rule.xml文件,修改mod-long分片算法的求模基数,由于只有两个集群作为分片,所以这里需要将基数改为2:
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>- Tips:该分片算法使用表中
id列的值对求模基数进行求模以得出数据分片的索引
完成以上三个文件的配置后,启动Mycat:
[root@mycat-01 ~]# mycat start
Starting Mycat-server...
[root@mycat-01 ~]# more /usr/local/mycat/logs/wrapper.log |grep successfully
# 日志输出了 successfully 代表启动成功
INFO | jvm 1 | 2020/01/19 15:09:02 | MyCAT Server startup successfully. see logs in logs/mycat.log测试
启动完成后,进入Mycat中执行一条insert语句,测试下是否能将该SQL转发到正确的集群分片上。具体步骤如下:
[root@mycat-01 ~]# mysql -uadmin -P8066 -h227.0.0.1 -p
mysql> use test;
mysql> insert into t_user(id, username, password, tel, locked)
-> values(1, 'Jack', hex(AES_ENCRYPT('123456', 'Test')), '13333333333', 'N');上面这条insert语句插入的是一条id为1的记录,而我们采用的是对id列求模的分片算法,配置的求模基数为2。因此,根据id的值和求模基数进行求模计算的结果为:1 % 2 = 1。得出来的1就是分片的索引,所以正常情况下Mycat会将该insert语句转发到分片索引为1的集群上。
根据schema.xml文件中的配置,索引为1的分片对应的集群是pxc-cluster2,即第二个PXC集群分片。接下来,我们可以通过对比这两个集群中的数据,以验证Mycat是否按照预期正确地转发了该SQL。
从下图中可以看到,Mycat正确地将该insert语句转发到了第二个分片上,此时第一个分片是没有数据的: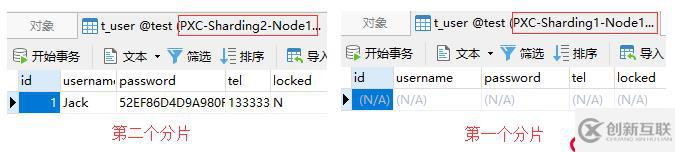
接着我们再测试当id为2时,Mycat是否能将该SQL转发到第一个分片上。具体的SQL如下:
insert into t_user(id, username, password, tel, locked)
values(2, 'Jon', hex(AES_ENCRYPT('123456', 'Test')), '18888888888', 'N');测试结果如图: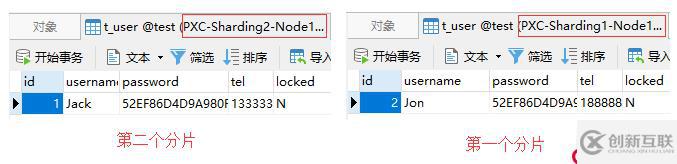
在完成以上的测试后,此时在Mycat上是能够查询出所有分片中的数据的: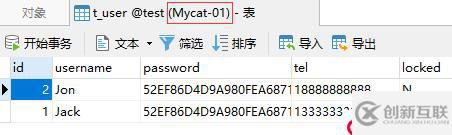
常用的四类数据切分算法
主键求模切分
上一小节的示例中,使用的就是主键求模切分,其特点如下:
- 主键求模切分适合用在初始数据很大,但是数据增长不快的场景。例如,地图产品、行政数据、企业数据等。
- 主键求模切分的弊端在于扩展新分片难度大,迁移的数据太多
- 如果需要扩展分片数量,建议扩展后的分片数量是原有分片的2n倍。例如,原本是两个分片,扩展后是四个分片
主键范围切分
- 主键范围切分适合用在数据快速增长的场景
- 容易增加分片,需要有明确的主键列
日期切分
- 日期切分适合用在数据快速增长的场景
- 容易增加分片,需要有明确的日期列
枚举值切分
- 枚举值切分适合用在归类存储数据的场景,适合大多数业务
- 枚举值切分按照某个字段的值(数字)与
mapFile配置的映射关系来切分数据 - 枚举值切分的弊端在于分片存储的数据不够均匀
在Mycat 核心配置详解一文中,也介绍过枚举值切分算法。该算法相对于其他算法来说要用到一个额外的映射文件(mapFile),所以这里就针对该算法的使用进行一个简单的演示。
需求:用户表中有一个存储用户所在区号的列,要求将该列作为分片列,实现让不同区号下的用户数据被分别存储到不同的分片中
1、首先,在Mycat的rule.xml文件中,增加如下配置:
<!-- 定义分片规则 -->
<tableRule name="sharding-by-areafile">
<rule>
<!-- 定义使用哪个列作为分片列 -->
<columns>area_id</columns>
<algorithm>area-int</algorithm>
</rule>
</tableRule>
<!-- 定义分片算法 -->
<function name="area-int" class="io.mycat.route.function.PartitionByFileMap">
<!-- 定义mapFile的文件名,位于conf目录下 -->
<property name="mapFile">area-hash-int.txt</property>
</function>2、在conf目录下创建area-hash-int.txt文件,定义区号与分片索引的对应关系:
[root@mycat-01 /usr/local/mycat]# vim conf/area-hash-int.txt
020=0
0755=0
0757=0
0763=1
0768=1
0751=13、配置schema.xml,增加一个逻辑表,并将其分片规则设置为sharding-by-areafile:
<schema name="test" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="t_user" dataNode="dn1,dn2" rule="mod-long"/>
<table name="t_customer" dataNode="dn1,dn2" rule="sharding-by-areafile"/>
</schema>4、进入Mycat中执行热加载语句,该语句的作用可以使Mycat不用重启就能应用新的配置:
[root@mycat-01 ~]# mysql -uadmin -P9066 -h227.0.0.1 -p
mysql> reload @@config_all;测试
完成以上配置后,我们来建个表测试一下,在所有的集群中创建t_customer表。具体的建表SQL如下:
create table t_customer(
id int primary key,
username varchar(20) not null,
area_id int not null
);进入Mycat中插入一条area_id为020的记录:
[root@mycat-01 ~]# mysql -uadmin -P8066 -h227.0.0.1 -p
mysql> use test;
mysql> insert into t_customer(id, username, area_id)
-> values(1, 'Jack', 020);根据映射文件中的配置,area_id为020的数据会被存储到第一个分片中,如下图: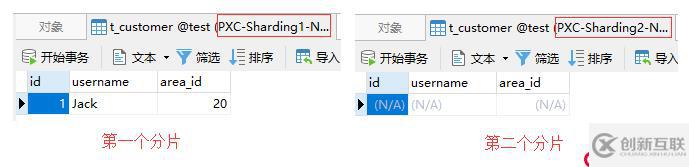
- Tips:这里由于
area_id是int类型的,所以前面的0会被去掉
然后再插入一条area_id为0763的记录:
insert into t_customer(id, username, area_id)
values(2, 'Tom', 0763);根据映射文件中的配置,area_id为0763的数据会被存储到第二个分片中,如下图: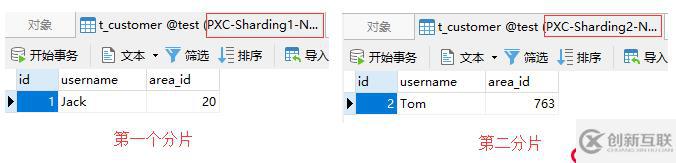
完成以上测试后,此时在Mycat中应能查询到所有分片中的数据: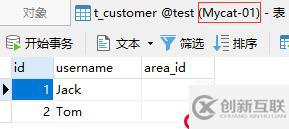
父子表
当有关联的数据存储在不同的分片时,就会遇到表连接的问题,在Mycat中是不允许跨分片做表连接查询的。为了解决跨分片表连接的问题,Mycat提出了父子表这种解决方案。
父子表规定父表可以有任意的切分算法,但与之关联的子表不允许有切分算法,即子表的数据总是与父表的数据存储在一个分片中。父表不管使用什么切分算法,子表总是跟随着父表存储。
例如,用户表与订单表是有关联关系的,我们可以将用户表作为父表,订单表作为子表。当A用户被存储至分片1中,那么A用户产生的订单数据也会跟随着存储在分片1中,这样在查询A用户的订单数据时就不需要跨分片了。如下图所示:
实践
了解了父子表的概念后,接下来我们看看如何在Mycat中配置父子表。首先,在schema.xml文件中配置父子表关系:
<schema name="test" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="t_customer" dataNode="dn1,dn2" rule="sharding-by-areafile">
<!-- 配置子表 -->
<childTable name="t_orders" joinKey="customer_id" parentKey="id"/>
</table>
</schema>childTable标签说明:
joinKey属性:定义子表中用于关联父表的列parentKey属性:定义父表中被关联的列childTable标签内还可以继续添加childTable标签
完成以上配置后,让Mycat重新加载配置文件:
reload @@config_all;测试
接着在所有分片中创建t_orders表,具体的建表SQL如下:
create table t_orders(
id int primary key,
customer_id int not null,
create_time datetime default current_timestamp
);现在分片中有两个用户,id为1的用户存储在第一个分片,id为2的用户存储在第二个分片。此时,通过Mycat插入一条订单记录:
insert into t_orders(id, customer_id)
values(1, 1);由于该订单记录关联的是id为1的用户,根据父子表的规定,会被存储至第一个分片中。如下图: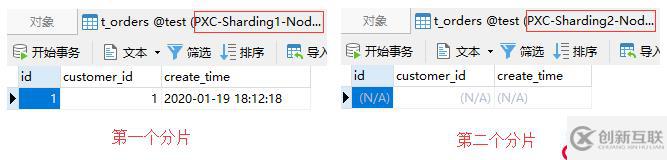
同样,如果订单记录关联的是id为2的用户,那么就会被存储至第二个分片中:
insert into t_orders(id, customer_id)
values(2, 2);测试结果如下: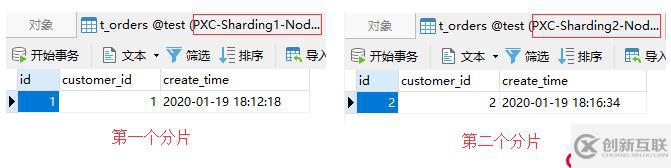
由于父子表的数据都是存储在同一个分片,所以在Mycat上进行关联查询也是没有问题的: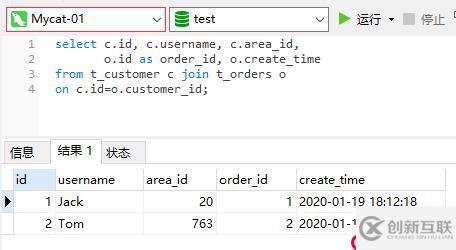
组建双机热备的高可用Mycat集群
前言
在以上小节的示例中,我们可以看到对后端数据库集群的读写操作都是在Mycat上进行的。Mycat作为一个负责接收客户端请求,并将请求转发到后端数据库集群的中间件,不可避免的需要具备高可用性。否则,如果Mycat出现单点故障,那么整个数据库集群也就无法使用了,这对整个系统的影响是十分巨大的。
所以本小节将演示如何去构建一个高可用的Mycat集群,为了搭建Mycat高可用集群,除了要有两个以上的Mycat节点外,还需要引入Haproxy和Keepalived组件。
其中Haproxy作为负载均衡组件,位于最前端接收客户端的请求并将请求分发到各个Mycat节点上,用于保证Mycat的高可用。而Keepalived则用于实现双机热备,因为Haproxy也需要高可用,当一个Haproxy宕机时,另一个备用的Haproxy能够马上接替。也就说同一时间下只会有一个Haproxy在运行,另一个Haproxy作为备用处于等待状态。当正在运行中的Haproxy因意外宕机时,Keepalived能够马上将备用的Haproxy切换到运行状态。
Keepalived是让主机之间争抢同一个虚拟IP(VIP)来实现高可用的,这些主机分为Master和Backup两种角色,并且Master只有一个,而Backup可以有多个。最开始Master先获取到VIP处于运行状态,当Master宕机后,Backup检测不到Master的情况下就会自动获取到这个VIP,此时发送到该VIP的请求就会被Backup接收到。这样Backup就能无缝接替Master的工作,以实现高可用。
引入这些组件后,最终我们的集群架构将演变成这样子: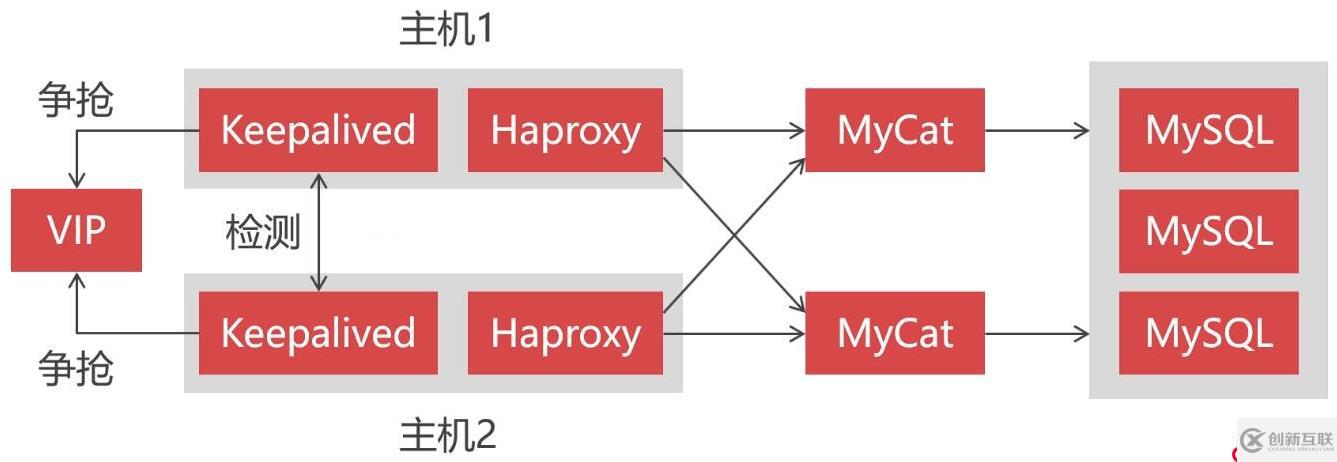
安装Haproxy
Haproxy由于是老牌的负载均衡组件了,所以CentOS的yum仓库中自带有该组件的安装包,安装起来就非常简单。安装命令如下:
[root@Haproxy-Master ~]# yum install -y haproxy配置Haproxy:
[root@Haproxy-Master ~]# vim /etc/haproxy/haproxy.cfg
# 在文件的末尾添加如下配置项
# 监控界面配置
listen admin_stats
# 绑定的ip及监听的端口
bind 0.0.0.0:4001
# 访问协议
mode http
# URI 相对地址
stats uri /dbs
# 统计报告格式
stats realm Global\ statistics
# 用于登录监控界面的账户密码
stats auth admin:abc123456
# 数据库负载均衡配置
listen proxy-mysql
# 绑定的ip及监听的端口
bind 0.0.0.0:3306
# 访问协议
mode tcp
# 负载均衡算法
# roundrobin:轮询
# static-rr:权重
# leastconn:最少连接
# source:请求源ip
balance roundrobin
# 日志格式
option tcplog
# 需要被负载均衡的主机
server mycat_01 192.168.190.136:8066 check port 8066 weight 1 maxconn 2000
server mycat_02 192.168.190.135:8066 check port 8066 weight 1 maxconn 2000
# 使用keepalive检测死链
option tcpka由于配置了3306端口用于TCP转发,以及4001作为Haproxy监控界面的访问端口,所以在防火墙上需要开放这两个端口:
[root@Haproxy-Master ~]# firewall-cmd --zone=public --add-port=3306/tcp --permanent
[root@Haproxy-Master ~]# firewall-cmd --zone=public --add-port=4001/tcp --permanent
[root@Haproxy-Master ~]# firewall-cmd --reload完成以上步骤后,启动Haproxy服务:
[root@Haproxy-Master ~]# systemctl start haproxy然后使用浏览器访问Haproxy的监控界面,初次访问会要求输入用户名密码,这里的用户名密码就是配置文件中所配置的:
登录成功后,就会看到如下页面: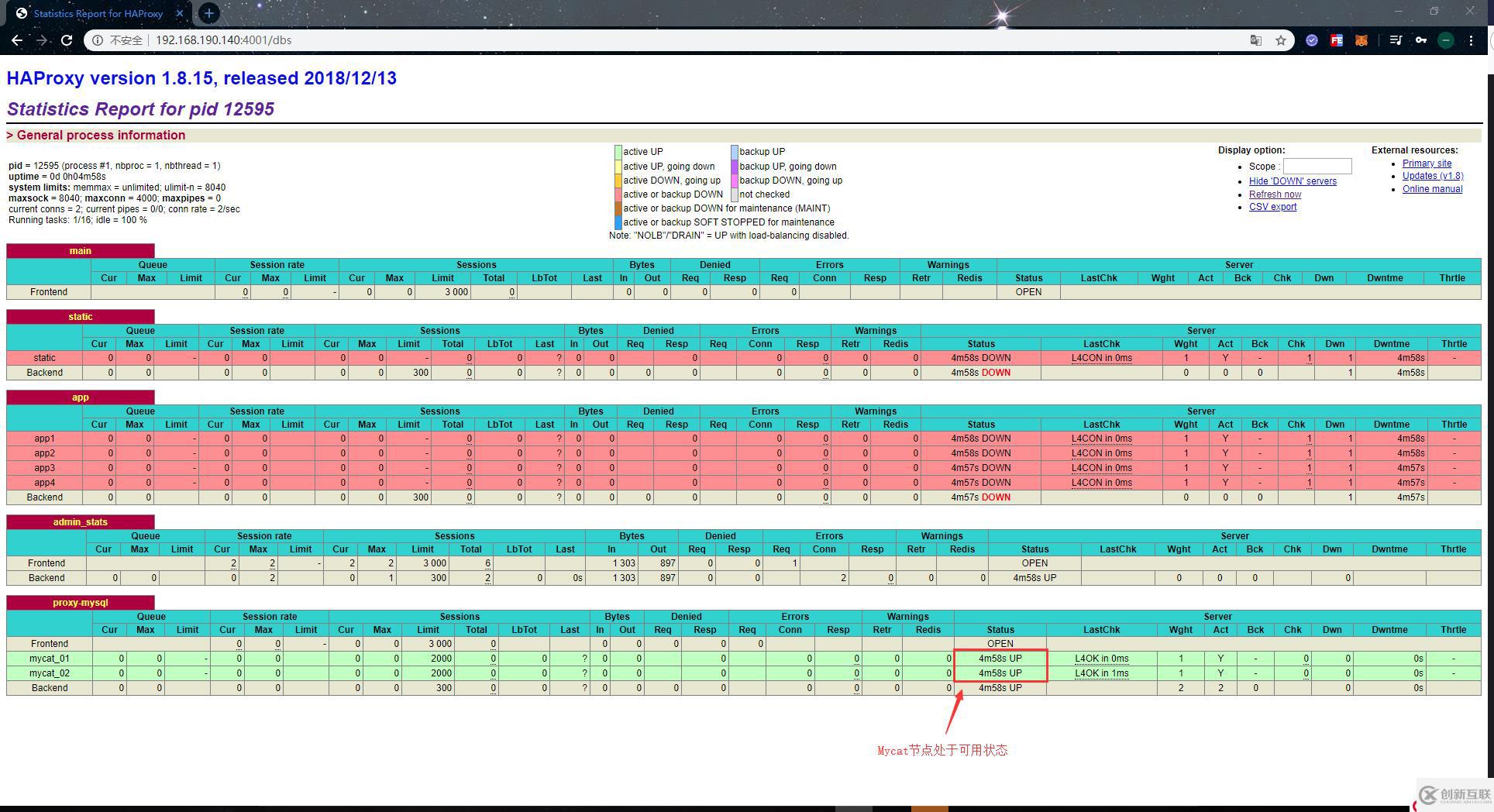
Haproxy的监控界面提供的监控信息也比较全面,在该界面下,我们可以看到每个主机的连接信息及其自身状态。当主机无法连接时,Status一栏会显示DOWN,并且背景色也会变为红色。正常状态下的值则为UP,背景色为绿色。
另一个Haproxy节点也是使用以上的步骤进行安装和配置,这里就不再重复了。
测试Haproxy
Haproxy服务搭建起来后,我们来使用远程工具测试一下能否通过Haproxy正常连接到Mycat。如下: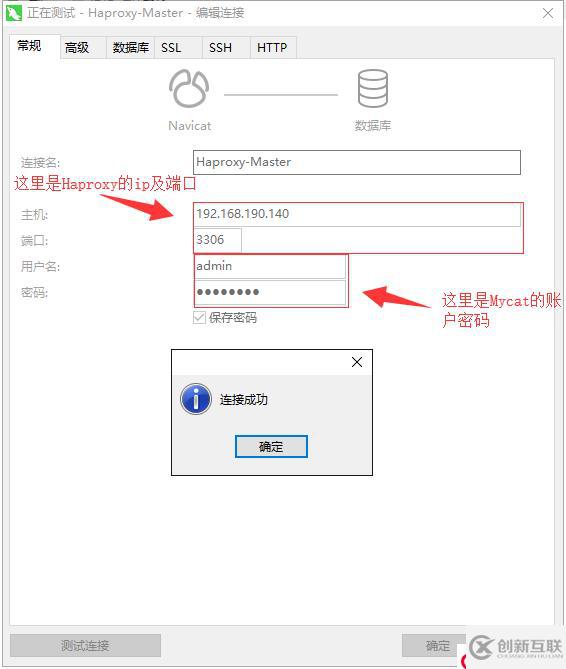
连接成功后,在Haproxy上执行一些SQL语句,看看能否正常插入数据和查询数据: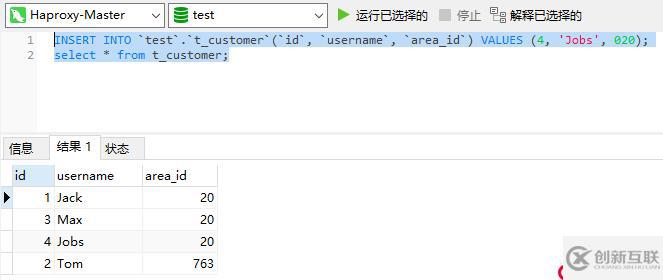
我们搭建Haproxy是为了让Mycat具备高可用的,所以最后测试一下Mycat是否已具备有高可用性,首先将一个Mycat节点给停掉:
[root@mycat-01 ~]# mycat stop
Stopping Mycat-server...
Stopped Mycat-server.
[root@mycat-01 ~]#此时,从Haproxy的监控界面中,可以看到mycat_01这个节点已经处于下线状态了:
现在集群中还剩一个Mycat节点,然后我们到Haproxy上执行一些SQL语句,看看是否还能正常插入数据和查询数据: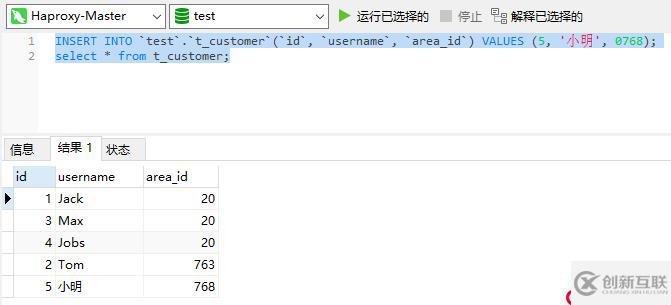
从测试结果可以看到,插入和查询语句依旧是能正常执行的。也就是说即便此时关掉一个Mycat节点整个数据库集群还能够正常使用,说明现在Mycat集群是具有高可用性了。
利用Keepalived实现Haproxy的高可用
实现了Mycat集群的高可用之后,我们还得实现Haproxy的高可用,因为现在的架构已经从最开始的Mycat面向客户端变为了Haproxy面向客户端。
而同一时间只需要存在一个可用的Haproxy,否则客户端就不知道该连哪个Haproxy了。这也是为什么要采用VIP的原因,这种机制能让多个节点互相接替时依旧使用同一个IP,客户端至始至终只需要连接这个VIP。所以实现Haproxy的高可用就要轮到Keepalived出场了,在安装Keepalived之前需要开启防火墙的VRRP协议:
[root@Haproxy-Master ~]# firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --protocol vrrp -j ACCEPT
[root@Haproxy-Master ~]# firewall-cmd --reload然后就可以使用yum命令安装Keepalived了,需要注意Keepalived是安装在Haproxy节点上的:
[root@Haproxy-Master ~]# yum install -y keepalived安装完成后,编辑keepalived的配置文件:
[root@Haproxy-Master ~]# mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak # 不使用自带的配置文件
[root@Haproxy-Master ~]# vim /etc/keepalived/keepalived.conf
vrrp_instance VI_1 {
state MASTER
interface ens32
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.190.100
}
}配置说明:
state MASTER:定义节点角色为master,当角色为master时,该节点无需争抢就能获取到VIP。集群内允许有多个master,当存在多个master时,master之间就需要争抢VIP。为其他角色时,只有master下线才能获取到VIPinterface ens32:定义可用于外部通信的网卡名称,网卡名称可以通过ip addr命令查看virtual_router_id 51:定义虚拟路由的id,取值在0-255,每个节点的值需要唯一,也就是不能配置成一样的priority 100:定义权重,权重越高就越优先获取到VIPadvert_int 1:定义检测间隔时间为1秒authentication:定义心跳检查时所使用的认证信息auth_type PASS:定义认证类型为密码auth_pass 123456:定义具体的密码
virtual_ipaddress:定义虚拟IP(VIP),需要为同一网段下的IP,并且每个节点需要一致
完成以上配置后,启动keepalived服务:
[root@Haproxy-Master ~]# systemctl start keepalived当keepalived服务启动成功,使用ip addr命令可以查看到网卡绑定的虚拟IP: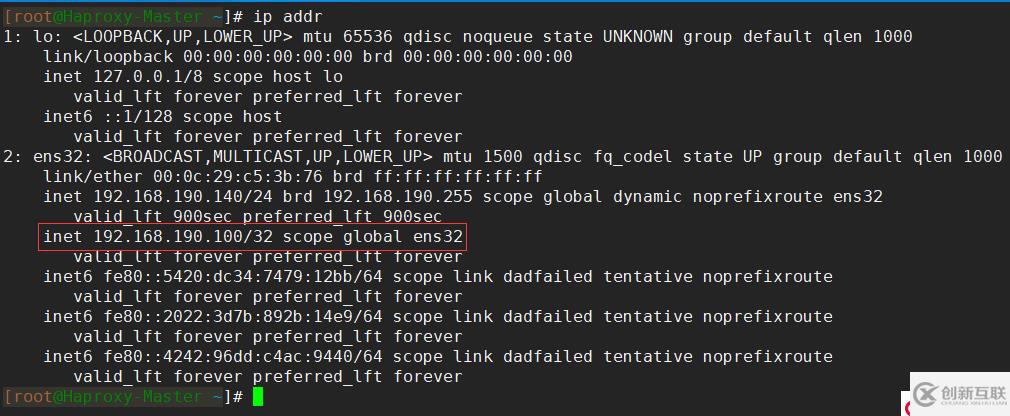
另一个节点也是使用以上的步骤进行安装和配置,这里就不再重复了。
测试Keepalived
以上我们完成了Keepalived的安装与配置,最后我们来测试Keepalived服务是否正常可用,以及测试Haproxy是否已具有高可用性。
首先,在其他节点上测试虚拟IP能否正常ping通,如果不能ping通就需要检查配置了。如图,我这里是能正常ping通的: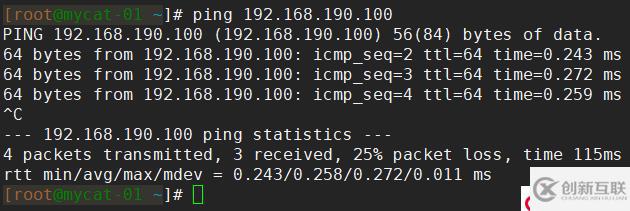
常见的虚拟IP ping不通的情况:
- 防火墙配置有误,没有正确开启VRRP协议
- 配置的虚拟IP与其他节点的IP不处于同一网段
- Keepalived配置有误,或Keepalived根本没启动成功
确认能够从外部ping通Keepalived的虚拟IP后,使用Navicat测试能否通过虚拟IP连接到Mycat: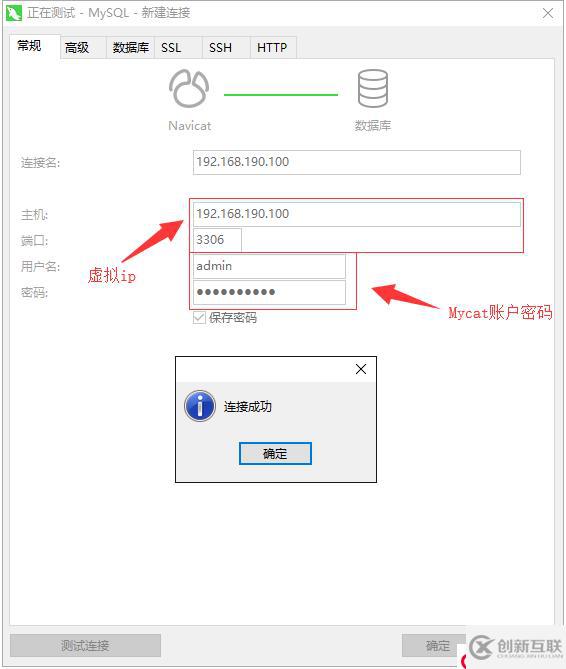
连接成功后,执行一些语句测试能否正常插入、查询数据: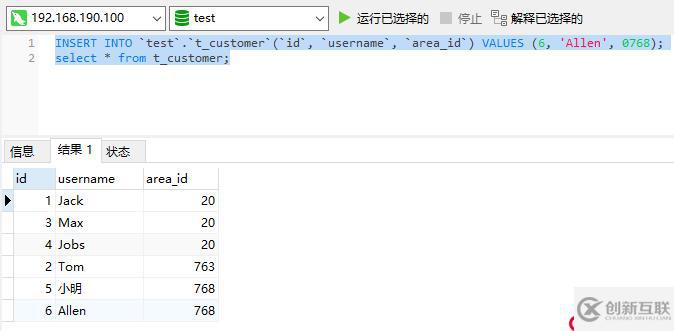
到此就基本没什么问题了,最后测试一下Haproxy的高可用性,将其中一个Haproxy节点上的keepalived服务给关掉:
[root@Haproxy-Master ~]# systemctl stop keepalived然后再次执行执行一些语句测试能否正常插入、查询数据,如下能正常执行代表Haproxy节点已具有高可用性: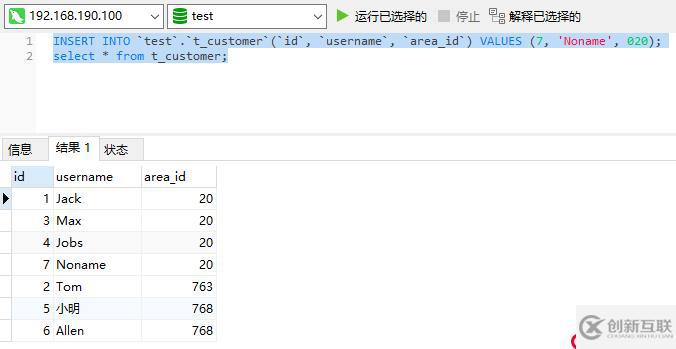
名称栏目:为PXC集群引入Mycat并构建完整的高可用集群架构
链接URL:https://www.cdcxhl.com/article44/igedhe.html
成都网站建设公司_创新互联,为您提供自适应网站、网站制作、App设计、网站排名、外贸网站建设、全网营销推广
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 成都建站公司分享如何仿制文章被盗用 2016-12-27
- 如何选择建站公司? 2021-11-02
- 建站公司有哪些主要的职位分工? 2022-05-21
- 互联网上面的建站公司是否可以信任 2022-11-24
- 为什么不同类型的建站公司价格有差别? 2016-11-24
- 咨询了100家建站公司,原来建站价格标准是这样定义的 2021-02-07
- 创新互联:成都市建站公司怎样解决 建站客户流量焦虑情绪 2016-11-13
- 为什么有些建站公司报价非常低? 2021-06-06
- 广州创新互联:怎么选择网站建站公司 2022-07-06
- 企业网站设计开发时建站公司与企业如何做到高效率的沟通? 2022-05-22
- 建站公司网站制作流程 2016-10-26
- 如何选择一家专业的上海建站公司? 2021-10-16