爬虫是什么-创新互联
创新互联www.cdcxhl.cn八线动态BGP香港云服务器提供商,新人活动买多久送多久,划算不套路!

这篇文章将为大家详细讲解有关爬虫是什么,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
一、爬虫是什么?
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序。
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
二、爬虫的基本流程
用户获取网络数据的方式:
方式1:浏览器提交请求—>下载网页代码—>解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2。
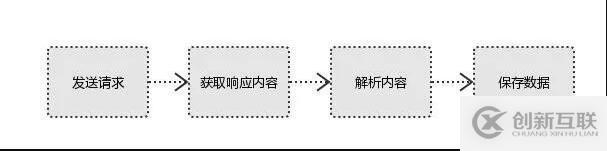
1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)
文件
三、http协议 请求与响应
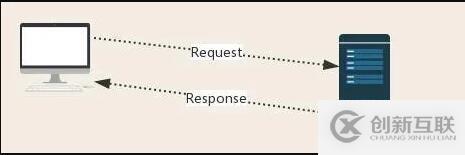
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
四、 request
1、请求方式:
常见的请求方式:GET / POST
2、请求的URL
url全球统一资源定位符,用来定义互联网上一个唯一的资源 例如:一张图片、一个文件、一段视频都可以用url唯一确定
url编码
https://www.baidu.com/s?wd=图片
图片会被编码(看示例代码)
网页的加载过程是:
加载一个网页,通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
3、请求头
User-agent:请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户host;
cookies:cookie用来保存登录信息
注意:一般做爬虫都会加上请求头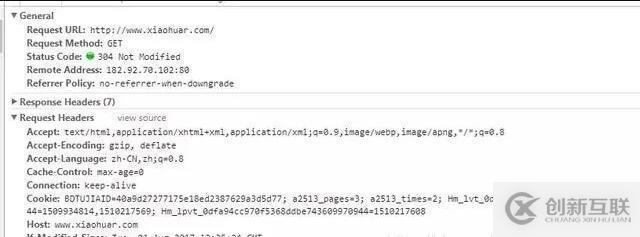

请求头需要注意的参数:
(1)Referrer:访问源至哪里来(一些大型网站,会通过Referrer 做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问的浏览器(要加上否则会被当成爬虫程序)
(3)cookie:请求头注意携带
4、请求体
请求体如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)如果是post方式,请求体是format dataps:1、登录窗口,文件上传等,信息都会被附加到请求体内2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应Response
1、响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:无权限访问
502:服务器错误
2、respone header
响应头需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/:可能有多个,是来告诉浏览器,把cookie保存下来
(2)Content-Location:服务端响应头中包含Location返回浏览器之后,浏览器就会重新访问另一个页面
3、preview就是网页源代码
JSO数据
如网页html,图片
二进制数据等
六、总结
1、总结爬虫流程:
爬取—>解析—>存储
2、爬虫所需工具:
请求库:requests,selenium(可以驱动浏览器解析渲染CSS和JS,但有性能劣势(有用没用的网页都会加载);) 解析库:正则,beautifulsoup,pyquery 存储库:文件,MySQL,Mongodb,Redis
关于爬虫是什么就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
文章题目:爬虫是什么-创新互联
地址分享:https://www.cdcxhl.com/article44/ecphe.html
成都网站建设公司_创新互联,为您提供微信小程序、域名注册、网站改版、面包屑导航、软件开发、网站营销
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 品牌网站设计制作过程中要注意哪些问题? 2020-12-03
- 品牌网站设计定制解决方案 2021-08-16
- 品牌网站设计的页脚样式是什么 2021-06-20
- 品牌网站设计中大小标题之间的色彩关系 2022-12-03
- 品牌网站设计的四大原则 2013-09-05
- 如何做好品牌网站设计,成都网站建设公司来帮您。 2022-08-20
- 深圳品牌网站设计:如何制作设计一个好的网站 2021-08-17
- 品牌网站设计如何在同行业中脱颖而出? 2016-01-18
- 成都企业品牌网站设计的常见布局方式 2023-03-25
- 如何制作自己的网站 企业品牌网站设计思路 2021-05-05
- 品牌网站设计的意义是什么,如何起到这种效果? 2022-09-30
- 怎样做成都品牌网站设计才有效果? 2016-12-27