如何进行基于bs4的拉勾网AI相关工作爬虫实现
本篇文章给大家分享的是有关如何进行基于bs4的拉勾网AI相关工作爬虫实现,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
创新互联2013年开创至今,是专业互联网技术服务公司,拥有项目成都网站设计、成都做网站网站策划,项目实施与项目整合能力。我们以让每一个梦想脱颖而出为使命,1280元刚察做网站,已为上家服务,为刚察各地企业和个人服务,联系电话:028-86922220
年初大家可能是各种跳槽吧,看着自己身边的人也是一个个的要走了,其实是有一点伤感的。人各有志吧,不多评论。这篇文章主要是我如何抓取拉勾上面AI相关的职位数据,其实抓其他工作的数据原理也是一样的,只要会了这个,其他的都可以抓下来。一共用了不到100行代码,主要抓取的信息有“职位名称”,“月薪”,“公司名称”,“公司所属行业”,“工作基本要求(经验,学历)”,“岗位描述”等。涉及的工作有“自然语言处理”,“机器学习”,“深度学习”,“人工智能”,“数据挖掘”,“算法工程师”,“机器视觉”,“语音识别”,“图像处理”等几大类。
下面随便截个图给大家看下,我们想要的信息
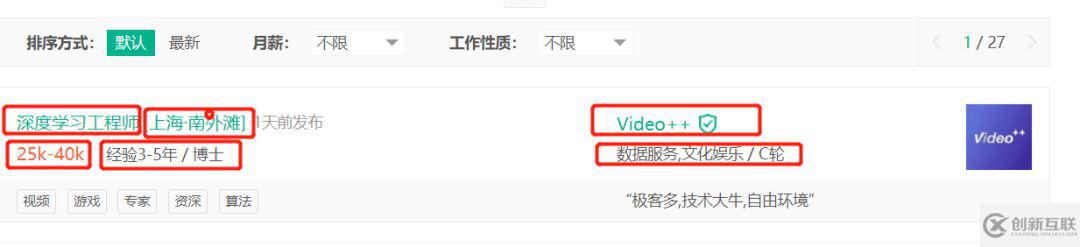

然后看下我们要的信息在哪里
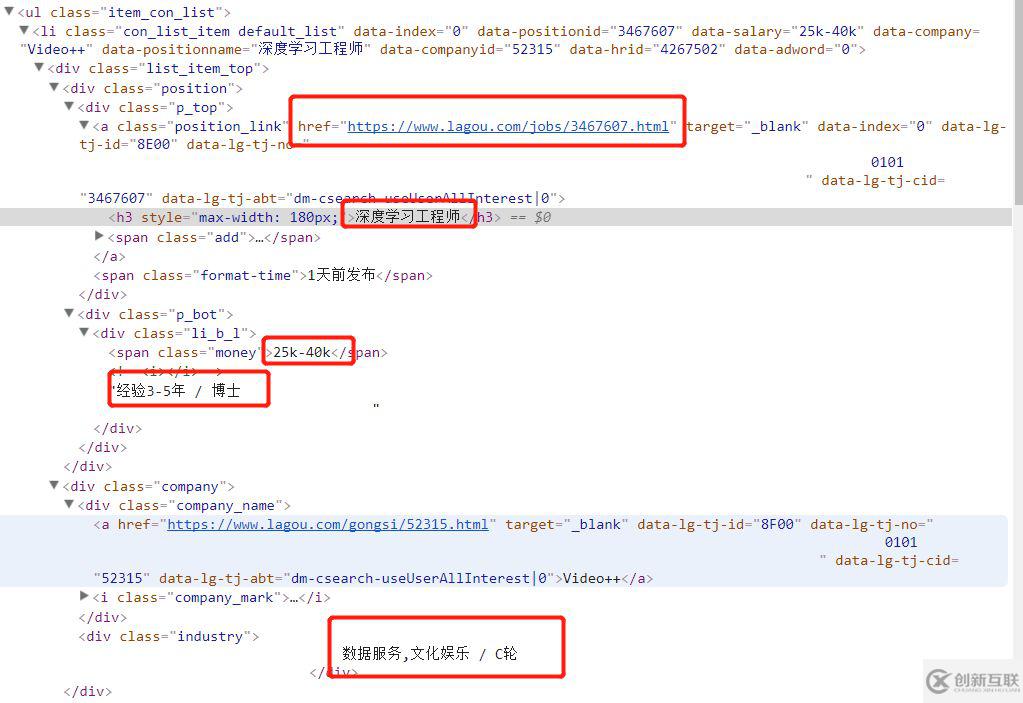
然后职位详细信息是的url就在那个href里面,所以关键是要取到那个href就OK了。
下面直接上代码
首先我们需要判断一个url是不是合法的url,就是isurl方法。
urlhelper方法是用来提取url的html内容,并在发生异常时,打一条warning的警告信息
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd
import requests
from collections import OrderedDict
from tqdm import tqdm, trange
import urllib.request
from urllib import error
import logging
logging.basicConfig(level=logging.WARNING)
def isurl(url):
if requests.get(url).status_code == 200:
return True
else:
return False
def urlhelper(url):
try:
req = urllib.request.Request(url)
req.add_header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64)"
" AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/45.0.2454.101 Safari/537.36")
req.add_header("Accept", "*/*")
req.add_header("Accept-Language", "zh-CN,zh;q=0.8")
data = urllib.request.urlopen(req)
html = data.read().decode('utf-8')
return html
except error.URLError as e:
logging.warning("{}".format(e))
下面就是爬虫的主程序了,里面需要注意的是异常的处理,很重要,不然万一爬了一半挂了,前面爬的又没保存就悲剧了。还有一个是想说BeautifulSoup这个类真的是十分方便,熟练使用能节省很多时间。
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd
import requests
from collections import OrderedDict
from tqdm import tqdm, trange
import urllib.request
from urllib import error
import logging
names = ['ziranyuyanchuli', 'jiqixuexi', 'shenduxuexi', 'rengongzhineng',
'shujuwajue', 'suanfagongchengshi', 'jiqishijue', 'yuyinshibie',
'tuxiangchuli']
for name in tqdm(names):
savedata = []
page_number = 0
for page in range(1, 31):
page_number += 1
if page_number % 5 == 0:
print(page_number)
rooturl = 'https://www.lagou.com/zhaopin/{}/{}/'.format(name, page)
if not isurl(rooturl):
continue
html = urlhelper(rooturl)
soup = BeautifulSoup(html, "lxml")
resp = soup.findAll('div', attrs={'class': 's_position_list'})
resp = resp[0]
resp = resp.findAll('li', attrs={'class': 'con_list_item default_list'})
for i in trange(len(resp)):
position_link = resp[i].findAll('a', attrs={'class': 'position_link'})
link = position_link[0]['href']
if isurl(link):
htmlnext = urlhelper(link)
soup = BeautifulSoup(htmlnext, "lxml")
try:
# 职位描述
job_bt = soup.findAll('dd',
attrs={'class': 'job_bt'})[0].text
except:
continue
try:
# 工作名称
jobname = position_link[0].find('h4').get_text()
except:
continue
try:
# 工作基本要求
p_bot = resp[i].findAll('div',
attrs={'class': 'p_bot'})[0].text
except:
continue
try:
# 月薪
money = resp[i].findAll('span',
attrs={'class': 'money'})[0].text
except:
continue
try:
# 行业
industry = resp[i].findAll('div',
attrs={'class': 'industry'})[0].text
except:
continue
try:
# 公司名字
company_name = resp[i].findAll(
'div', attrs={'class': 'company_name'})[0].text
except:
continue
rows = OrderedDict()
rows["jobname"] = jobname.replace(" ", "")
rows["money"] = money
rows["company_name"] = company_name.replace("\n", "")
rows["p_bot"] = p_bot.strip().replace(" ", ""). \
replace("\n", ",").replace("/", ",")
rows["industry"] = industry.strip().\
replace("\t", "").replace("\n", "")
rows["job_bt"] = job_bt
savedata.append(rows)
# 保存到本地
df = pd.DataFrame(savedata)
df.to_csv("./datasets/lagou/{}.csv".format(name), index=None)
以上就是如何进行基于bs4的拉勾网AI相关工作爬虫实现,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注创新互联行业资讯频道。
文章标题:如何进行基于bs4的拉勾网AI相关工作爬虫实现
文章出自:https://www.cdcxhl.com/article40/jdsdeo.html
成都网站建设公司_创新互联,为您提供企业建站、标签优化、用户体验、网站排名、网站设计、网站设计公司
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 域名注册后备案要注销该怎么操作? 2023-03-26
- 建站时域名注册和网站空间要在同一个服务商买吗? 2016-10-13
- 重庆网络公司: 低价不是网站建设和域名注册的最优选择 2015-05-11
- 域名注册细节您了解么?教您如何避免损失 2021-05-14
- 制作营销型网站时注册域名有哪些注意事项 2016-09-06
- 域名注册和空间购买的技巧 2021-03-02
- 网站域名注册-域名注册应该注意哪些事项? 2016-11-09
- 多个.com域名被上万收购折射未来域名注册商机 2022-11-11
- 成都建网站详解GOV.CN域名注册 2022-06-13
- 域名注册需知 2022-07-13
- 建站初期注意禁忌网址域名注册 2022-07-26
- 谈谈网站注册域名对搜索引擎的影响 2015-05-24