mmseg4j-1.9solr4的bug怎么处理
这篇文章主要讲解了“mmseg4j-1.9 solr4的bug怎么处理 ”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“mmseg4j-1.9 solr4的bug怎么处理 ”吧!
创新互联建站一直秉承“诚信做人,踏实做事”的原则,不欺瞒客户,是我们最起码的底线! 以服务为基础,以质量求生存,以技术求发展,成交一个客户多一个朋友!为您提供成都网站制作、网站设计、成都网页设计、小程序定制开发、成都网站开发、成都网站制作、成都软件开发、app软件开发公司是成都本地专业的网站建设和网站设计公司,等你一起来见证!
目前 中文分词mmseg4j 在 solr4 下是不能正常工作的。
解决方法可简单了, 只是solr4 接口有点变化 。
中文分词mmseg4插件的作者 没及时的跟上"solr4 接口"变化。 虽然分词算法是对的,添加的文档不能建索引。
源码80M读是读不懂的。在源码里猜测查找 不能新建索引这个的原因,比较费劲,差点没找到,结果还是“凑巧”给找到了。
bug描述:
(1)java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.l
ucene.analysis.Tokenizer.reset
报错信息:
http://code.google.com/p/mmseg4j/issues/detail?id=31 我是在分词测试时碰到这样的错误的。
解决方法:
这里的这个文件里的setReader 是新版solr4提供的。旧的接口reset 已经过期。
(2)
不能建索引 的相关描述:http://code.google.com/p/mmseg4j/issues/detail?id=38
原因:MMSegTokenizer 还是按以前版本的的solr 接口的。
MMSegTokenizer 在solr 里是缓存的,它和词库都是启动时就缓存了。 在后续有新的的短语要分词时,就会调用这个MMSegTokenizer.reset 方法把新词传进来,传给MMSegTokenizer。 但新版solr4里已经不调用这个reset方法了(也就是上图显示的那个reset方法),而是调用setReader ,这样MMSegTokenizer 实际分词的对象mmSeg就得不到新数据。于是 我加了下面的hack 代码,让mmSeg能得到新数据。
解决方法:
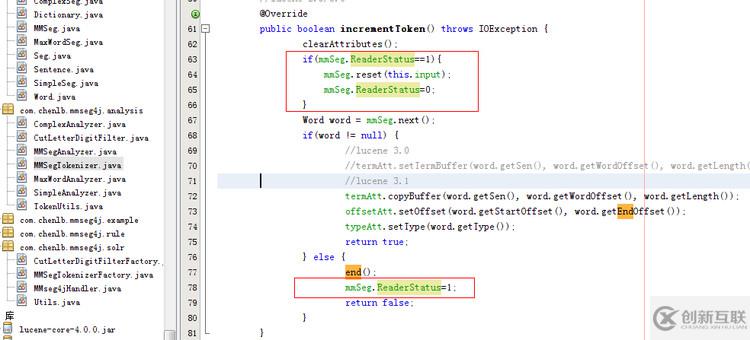
找到MMSegTokenizer.java 这个文件打开 上图 框里的内容是我新加的。 自己找到mmSeg对象加上一个ReaderStatus 属性默认值填0。
然后编译这个包。再放到solr 里去。重启tomcat 就能工作了。
感谢各位的阅读,以上就是“mmseg4j-1.9 solr4的bug怎么处理 ”的内容了,经过本文的学习后,相信大家对mmseg4j-1.9 solr4的bug怎么处理 这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是创新互联,小编将为大家推送更多相关知识点的文章,欢迎关注!
新闻标题:mmseg4j-1.9solr4的bug怎么处理
网页网址:https://www.cdcxhl.com/article40/ijpjeo.html
成都网站建设公司_创新互联,为您提供App设计、静态网站、企业建站、面包屑导航、动态网站、网站策划
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- HTML5手机网站开发页面宽度解决方案 2018-01-21
- 如何优雅的制作一套网站改版解决方案 2022-11-11
- 微信公众平台探索电子发票报销可行性解决方案 2022-06-06
- 百度不收录新网站的原因及解决方案 2020-11-03
- 网站定制功能解决方案 2020-07-17
- 8个顶级云安全解决方案 2021-03-03
- 最专业的学校网站建设解决方案 2017-06-18
- 农村农业电商商城网站建设制作开发解决方案 2021-02-22
- 旅游网站建设解决方案 2020-11-12
- 电器行业网站建设解决方案 2022-12-23
- 成都学车驾校网站建设解决方案 2023-02-17
- 什么是p2p网贷?p2p网站建设解决方案有哪些? 2023-02-02