go语言学习爬虫框架总结
最近主攻go的学习,在学完了基础语法,看完了无闻翻译的《The way to go》和ccmouse大神的慕课网课程后,感觉基础差不多了,继续深入挖掘ccmouse大神的爬虫项目,收获颇丰,感觉还是有一定的难度的,会继续啃下去,学习之余感觉自己实在是井底之蛙,无数光阴尽数浪费,无所建树,思维停留在最原始的层面,无法向前迈进;庆幸现在有所觉悟,人生匆匆几十载,时间是最宝贵的,不论哪个领域,选择一个自己认定的,低下头向前冲刺,丰富自己的头脑,提升自己的认知。好像扯得有点远了,下面是项目的总结。
成都创新互联公司-专业网站定制、快速模板网站建设、高性价比和田网站开发、企业建站全套包干低至880元,成熟完善的模板库,直接使用。一站式和田网站制作公司更省心,省钱,快速模板网站建设找我们,业务覆盖和田地区。费用合理售后完善,10年实体公司更值得信赖。
- 项目有一个main.go的入口文件,然后是各个子目录功能文件夹;如图:
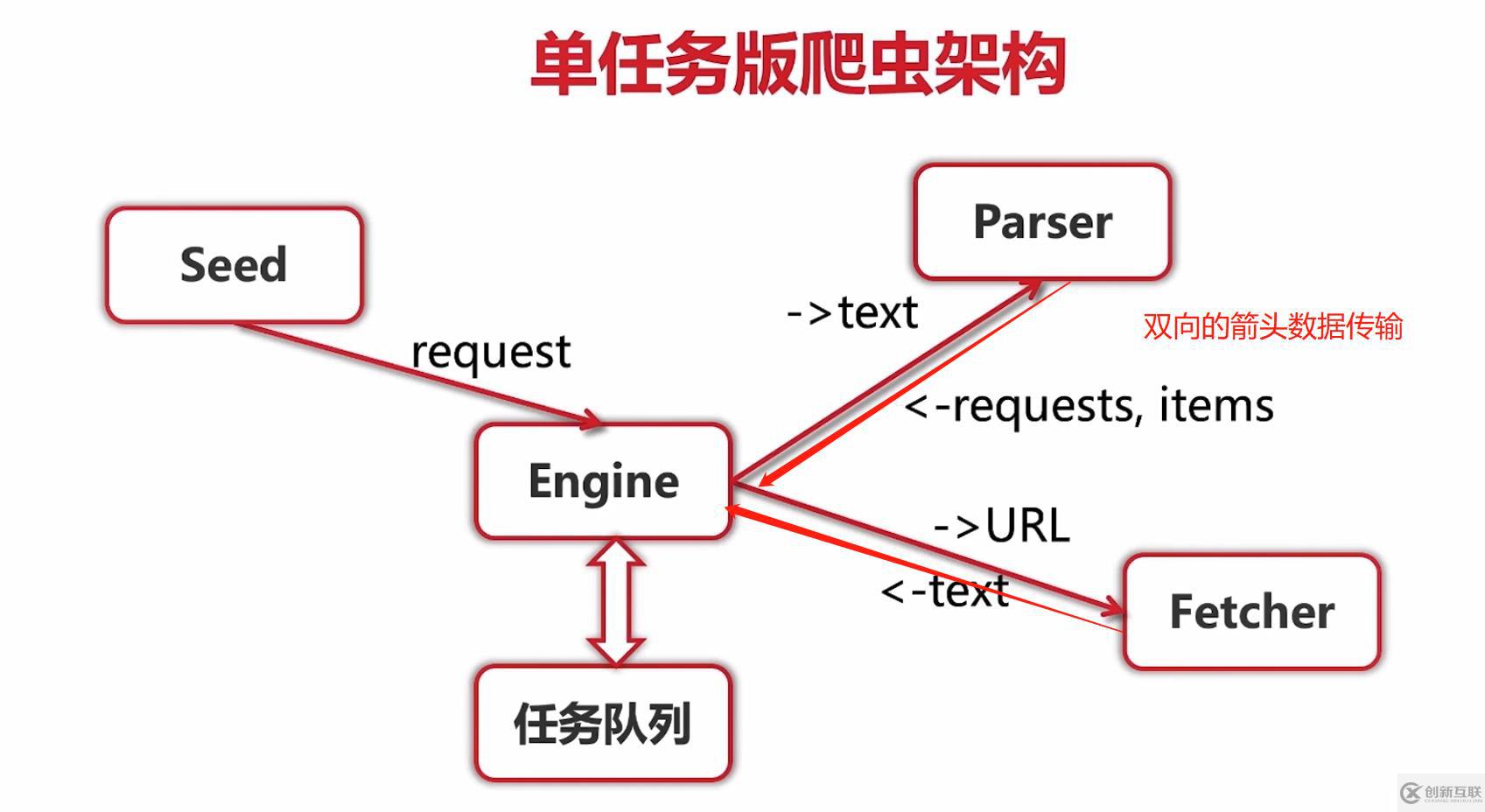
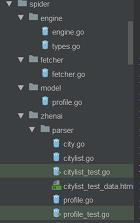 engine是总的控制文件,把请求和正则解析push到总的slice []request中,fetcher主要是通过http库去获取页面body信息,model是要保存的人的信息struct
engine是总的控制文件,把请求和正则解析push到总的slice []request中,fetcher主要是通过http库去获取页面body信息,model是要保存的人的信息struct - 说完了目录结构,接下来介绍下流程:
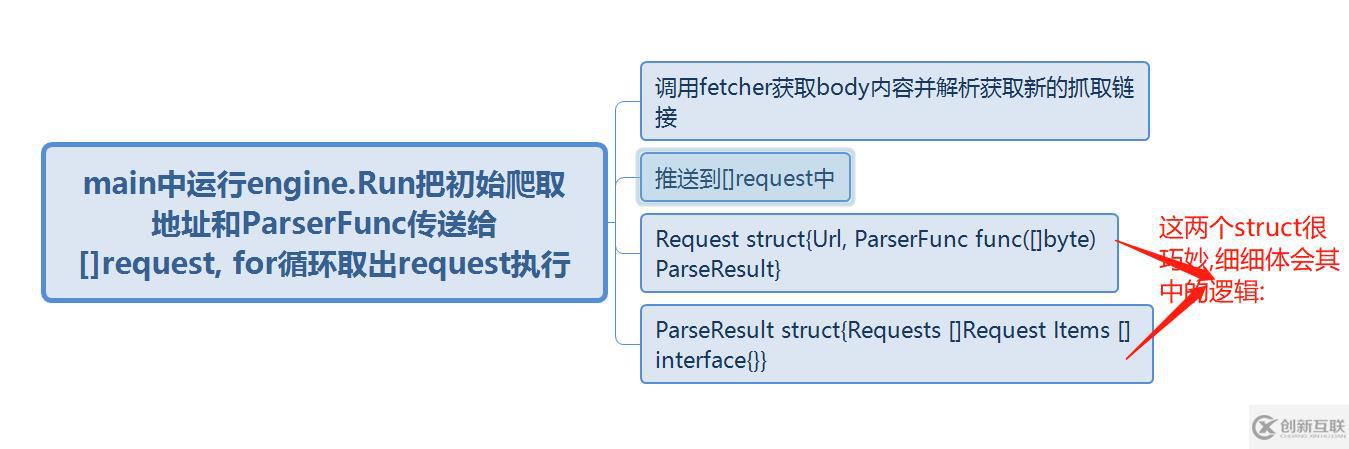
- 整个单机版爬虫项目比较简单,但对我来说收货还是比较大的,其中涉及到一些技术细节,如接口定义,结构方法的使用,
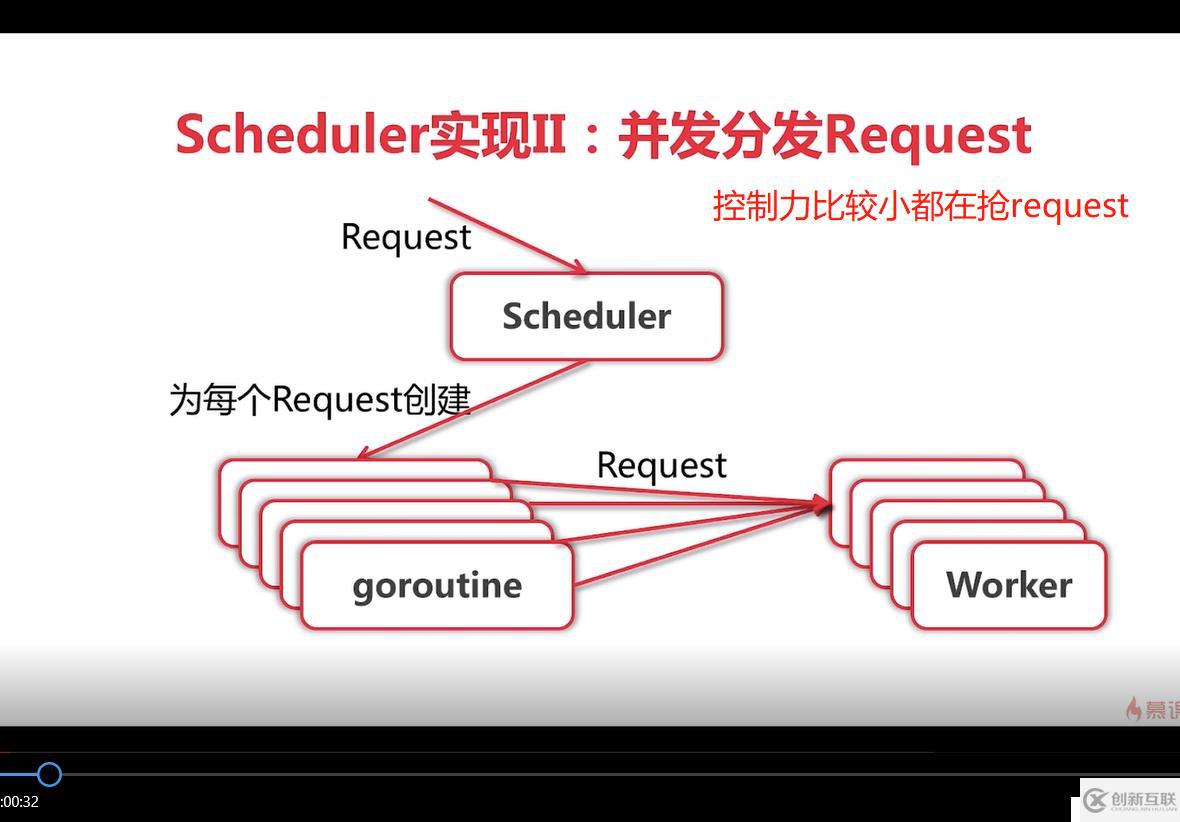
- 后面还有并发版本和分布式版本,就比较复杂了,并发版是充分使用go的goroutine和chan,要在大的方向上理清楚思路,抽象出一些公用的方法和结构,重要的正则解析要做test工作,然后在此指引下一步步构建,不可盲目前进。首先并发版需要两个chan,一个in :=chan Request和另一个out:=chan ParseResult,并发版启动WorkerCount个goroutine去并发获取in chan url内容并解析出新url推送到out chan,同时并发版有一个scheduler调度器, 将初始的爬取Request(包括url和对应的parser,因为每个网址的parser规则不同所以要成组传输)放进scheduler里的workerChan即前面定义的in chan, 他俩是一个chan, 程序开始并发执行,由于执行的比较快会被爬取网站断掉, 可以用time.Tike(time)来限制速度,另爬取时可能要设置相应的header头,否则会被屏蔽掉.
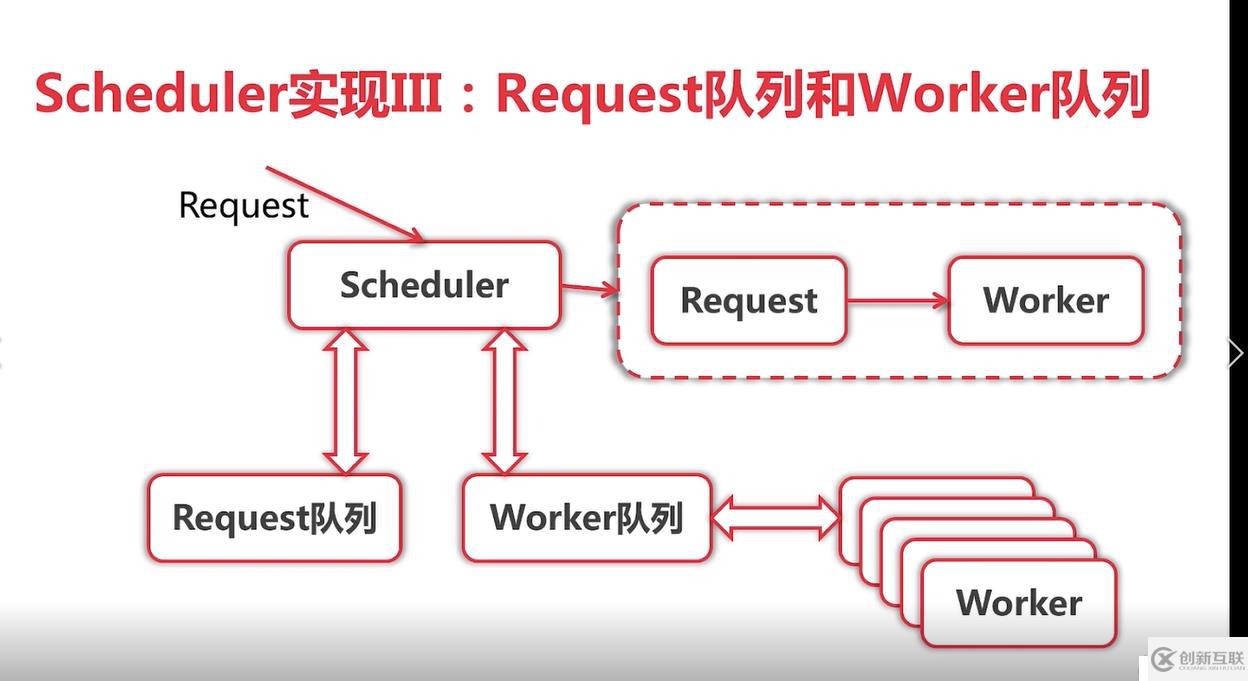
- 由于并发版多个worker都在争抢Request去执行,控制力度比较小,只适用于单机,不适合多机器分布式部署,故演化出第三个版本:队列实现.队列执行效率和并发版执行效率差不多. scheduler调度器中有rqquestChan chan Request 和 workerChan chan chan Request(
注意这里是两个chan), 在run方法中定义一个out chan ParseResult,和并发版相比而言,队列版多了workerChan 这个chan,主要用来实现队列的调度。试着描述下整个过程不一定清晰: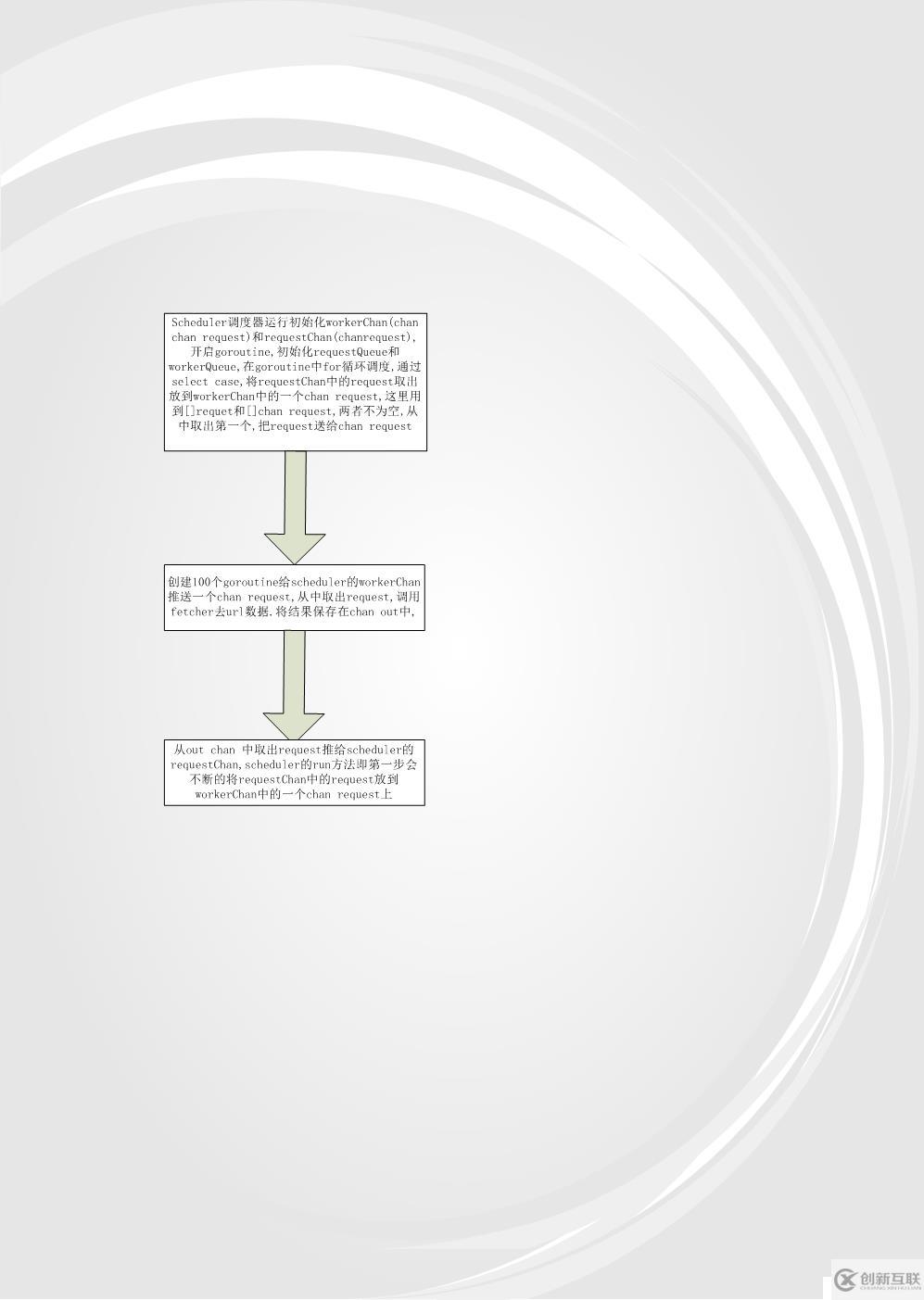
- 下面附上几张ccmouse大神的讲课ppt供大家理解,如有不清楚的欢迎下方留言讨论。
当前题目:go语言学习爬虫框架总结
网站地址:https://www.cdcxhl.com/article40/gheoho.html
成都网站建设公司_创新互联,为您提供企业网站制作、定制网站、虚拟主机、品牌网站设计、关键词优化、网站收录
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 设置合理的面包屑导航,可提高蜘蛛抓取网站的频率 2023-04-30
- 网站制作的过程中如何正确运用面包屑导航 2022-08-16
- 成都设计网站公司|面包屑导航的作用 2023-02-09
- 面包屑导航的作用和对购物体验的提升 2016-09-30
- 网站面包屑导航设计注意事项 2017-02-17
- 面包屑导航优化 2022-02-14
- 面包屑导航对于设计网站来说必不可少 2022-10-20
- 面包屑导航对网站建设的好处 2022-05-27
- 面包屑导航有什么作用? 2014-01-20
- 什么是面包屑,面包屑导航对seo有哪些作用 2022-08-12
- 网站设计中面包屑导航条的使用和设计 2016-03-17
- 上海网站建设网站优化先行官面包屑导航 2019-09-20