一文掌握fastapi微服务开发-创新互联
目录

一、概述
1.1 微服务
1.1.1 微服务的优势
1.1.2 微服务的缺点
1.2 为何使用Python开发微服务
1.3 FastAPI概述
二、开发
2.1 安装FastAPI
2.1.1 安装虚拟环境
2.1.2 创建虚拟环境
2.1.3 激活虚拟环境
2.1.4 安装FastAPI
2.2 FastAPI简单使用
2.2.1 查询
2.2.2 添加
2.2.3 修改
2.2.4 删除
2.3 代码组织
2.4 使用PostgreSQL数据库
2.4.1 安装PostgreSQL数据库
2.4.2 在FastAPI中连接PostgreSQL数据库
2.5 微服务中的数据管理
三、小结
一、概述 1.1 微服务
如果你是一名Python Web开发人员,那么肯定听说过微服务这个名词,并且希望通过Python来构建微服务。那么到底什么是微服务呢?
微服务(Microservice)是一种构建高可伸缩应用程序的架构,是一种将大型单一应用程序分解为专门针对特定服务、功能的单个应用程序的方法。举例来说,假如我们需要给自己的家进行装修,我们以前的做法就是找一家全包的装修公司将家里的水电、门窗、家具等全部交给这家装修公司,这家装修公司跟我们签订合同以后就统筹来安排所有的装修细节,我们后续的对接直接跟这家装修公司沟通就行了。装修时,所有的材料费都由这家装修公司统一采购和支出。这种方式在web开发领域就是典型的单片体系结构,每个业务逻辑(门窗装修、水电装修、家具装修)都驻留在同一个应用程序中(同一家装修公司负责),并且使用相同的数据库(所有装修的采购和财务由公司统一管理)。微服务架构则与这种单片体系结构不同,在微服务体系结构中,应用程序被分解为几个独立的服务,这些服务在不同的进程中运行。同样以装修为例,如果我们对这家公司的整体装修水平是认同的,但是,对他们打的家具不满意,我们想用别家专门做家具的来给我们打一套家具,那么我们就可以把打家具这项装修任务摘出去,交给另一家专门做家具的公司。很显然,我们完全可以将各个装修子任务都采用这种方式交给专门的装修公司。水电的交给专门做水电的、家具的交给专门做家具的、门窗的交给专门做门窗的。这种“细分”的方式能够让我们得到更满意的装修成果,毕竟术业有专攻,这种方式最终的性价比会更高。但是有个问题,全部任务分散以后我们必须规划好各个任务的进度和接口对接。例如,对于装修来说,我们一般是先装修水电再装修门窗家具,这里就有一个时间调度的安排。另外,水电的一些接口位置也必须提前规划好,因为后面设计门窗时也要考虑水电的位置安排。总之,这些各个分散的独立服务之间需要有效“沟通”才能真正发挥微服务的作用。微服务对于应用程序的不同功能有一个不同的数据库,根据每个服务的性质,微服务使用HTTP、AMQP或类似TCP的二进制协议相互通信,也可以使用RabbitMQ、Kafka或Redis等消息队列执行服务间通信。
1.1.1 微服务的优势- 松耦合
松散耦合的应用程序意味着可以使用最适合它们的技术来构建不同的服务。因此,开发团队可以根据每个子服务最适合的技术来开发。
- 易控制
术业有专攻,微服务可以使整个应用程序更容易理解和控制。
- 易扩展
使用微服务可以使应用程序扩展变得更容易,因为如果其中一个服务需要高GPU使用率,那么只有包含该服务的服务器需要高GPU,而其他服务器可以在普通服务器上运行。这一点在当今的人工智能时代尤其重要,因为我们经常需要部署一些基于AI这种高性能计算的微服务。
1.1.2 微服务的缺点微服务并不是万能的,它也有一些不足。
- 数据库同步
由于不同的服务使用不同的数据库,因此涉及多个微服务的数据库事务提交需要保证一致性。
- 微服务拆分
在第一次尝试时很难实现服务的完美分割,到底哪些功能应该单独拆出来组成一个微服务才是最佳的,这些都需要迭代测试。
- 通信速度
由于微服务之间使用网络交互进行通信,这使得应用程序容易因为网络延迟和服务速度慢而变慢。
1.2 为何使用Python开发微服务Python是构建微服务的完美工具,因为它具有强大的社区、易于学习的曲线和大量的第三方库。
Python是一种面向对象的、解释型的、通用的、开源的脚本编程语言,它之所以非常流行,主要有三点原因:
- Python 简单易用,学习成本低,看起来非常优雅干净;
- Python 标准库和第三库众多,功能强大,既可以开发小工具,也可以开发企业级应用;
- Python 站在了人工智能和大数据的风口上,流行度广。
举个简单的例子来说明一下 Python 的简单。比如要实现某个功能,C语言可能需要 100 行代码,而 Python 可能只需要几行代码,因为C语言什么都要得从头开始编写,而 Python 已经内置了很多常见功能,我们只需要导入包,然后调用一个函数即可。简单就是 Python 的巨大魅力之一,是它的杀手锏。正因为python的简洁,很多著名的web应用也开始陆续的采用python进行开发,例如豆瓣和知乎。但是,Python也有缺陷,就是它的速度相比其它语言要慢。虽然Python的速度问题一直被人诟病,但是由于Python引入了异步编程,因此近来出现了性能与GO和Node.js同等的web框架:Fastapi。
1.3 FastAPI概述FastAPI是近几年基于Python推出的一款高性能web框架,使用Python 3.6+并基于标准的Python进行构建。它的优势如下:
快速:可与NodeJS和Go比肩的极高性能(归功于 Starlette 和 Pydantic),使其超越django和flask成为最快的python web框架之一。
高效编码:提高功能开发速度约200%至300%。
- 更少 bug:减少约40%的人为(开发者)错误。
- 智能:极佳的编辑器支持。处处皆可自动补全,减少调试时间。
- 简单:设计的易于使用和学习。
- 简短:使代码重复最小化。
- 健壮:生产可用级别的代码。还有自动生成的交互式文档。
具体可参考FastAPI官方文档。
本教程将使用python web框架FastAPI来构建一个微服务应用。相关环境说明如下所示:
编程语言:Python 3.6.1
操作系统:Windows 7
二、开发 2.1 安装FastAPI 2.1.1 安装虚拟环境虚拟环境是Python解释器的一个副本环境,在这个环境中可以安装其它第三方Python包,在虚拟环境中安装的Python包不会影响全局环境中的包。打个比方,如果我同时接手两个团队的活:团队A和团队B,A团队的项目依赖了人工智能的tensorflow库(非常流行的深度学习库),B团队的项目也依赖了tensorflow,但是不巧的是A团队使用的是tensorflow 1版本,而B团队使用的是tensorflow 2版本,两个版本的兼容性非常差,那么两个项目同时在我自己的电脑上操作我该安装哪个库呢。假设两个库能同时安装在电脑上,具体执行的时候Python解释器也不知道到底该调用哪个tensorflow库。有没有什么办法把两个库在同一台电脑上隔离开,需要用哪个库就切换到哪个,这样,我就可以在一台电脑上同时开发两个不同环境的项目了。这个解决办法就是虚拟环境。
简单理解,虚拟环境就像一个容器,在某个虚拟环境中安装的python包可以独立于其它环境。
Windows平台下的虚拟环境需要使用第三方工具virtualenv来创建,打开命令终端,输入下面的命令即可完成安装:
pip install virtualenv安装完成后检查是否成功安装,继续输入命令如下:
virtualenv --version效果如下图所示:

此时会输出virtualenv的版本号,上面的版本号为20.4.2。
2.1.2 创建虚拟环境现在我们假定有一个项目工程,该工程位于文件夹micropro中,我们现在的目标就是在这个micropro项目中创建python虚拟环境,这个虚拟环境是专门为micropro项目成立的。在命令行终端中通过cd命令进入项目目录中(假设micropro文件夹位于D盘目录下),如下图所示:

输入下面的命令用来创建名为venv的虚拟环境:
virtualenv venv成功效果图如下所示:
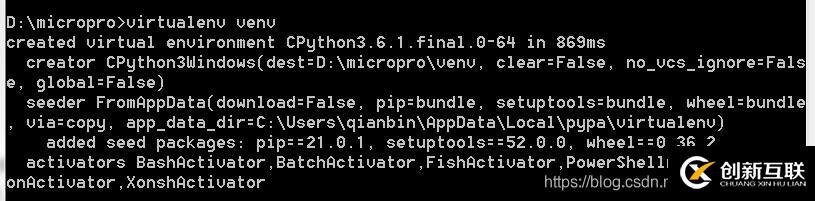
这样我们就在micrppro文件夹下有了一个名为venv的子文件夹,它保存一个全新的虚拟环境,其中有一个私有的Python解释器位于micropro/venv/Scripts,在该虚拟环境中安装的python包会存放在micropro/venv/Lib路径下。
2.1.3 激活虚拟环境Windows平台下激活虚拟环境的命令如下:
venv\Scripts\activate成功激活之后,虚拟环境解释器的路径就被加入PATH中,但这种改变不是永久的,他只会影响当前的命令行终端。为了提醒用户已经激活了虚拟环境,如下图所示,会修改命令行的提示符,加入环境名:
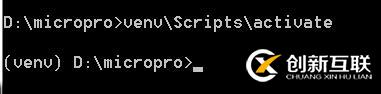
像上述这种前面带()的命令行就说明已经在虚拟环境中了。
2.1.4 安装FastAPI在虚拟环境中,我们使用下面的命令安装FastAPI:
pip install fastapi由于FastAPI没有内置web服务,所以需要安装uvicorn才能运行web应用。uvicorn是一个ASGI服务器,它允许我们使用异步特性。
使用以下命令安装uvicorn:
pip install uvicorn本小节先简单介绍和熟悉下FastAPI的基本使用方法。
在新创建的micropro目录中创建一个新目录app和一个新文件main.py,然后在main.py中添加以下代码:
from fastapi import FastAPI
app = FastAPI()
@app.get('/')
async def index():
return {"Real": "Python"}上述代码首先导入并实例化FastAPI,然后注册根网址/,然后返回JSON。
我们可以使用uvicorn运行应用程序服务器:
uvicorn app.main:app这里app.main表示使用app目录中的main.py文件,:app表示程序中定义的FastAPI实例名称。
成功启动后效果如下:

然后我们可以在浏览器中访问 http://127.0.0.1:8000,最终效果如下:
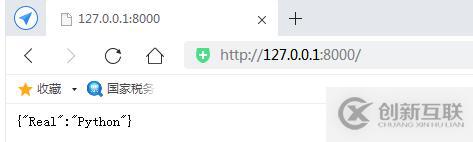
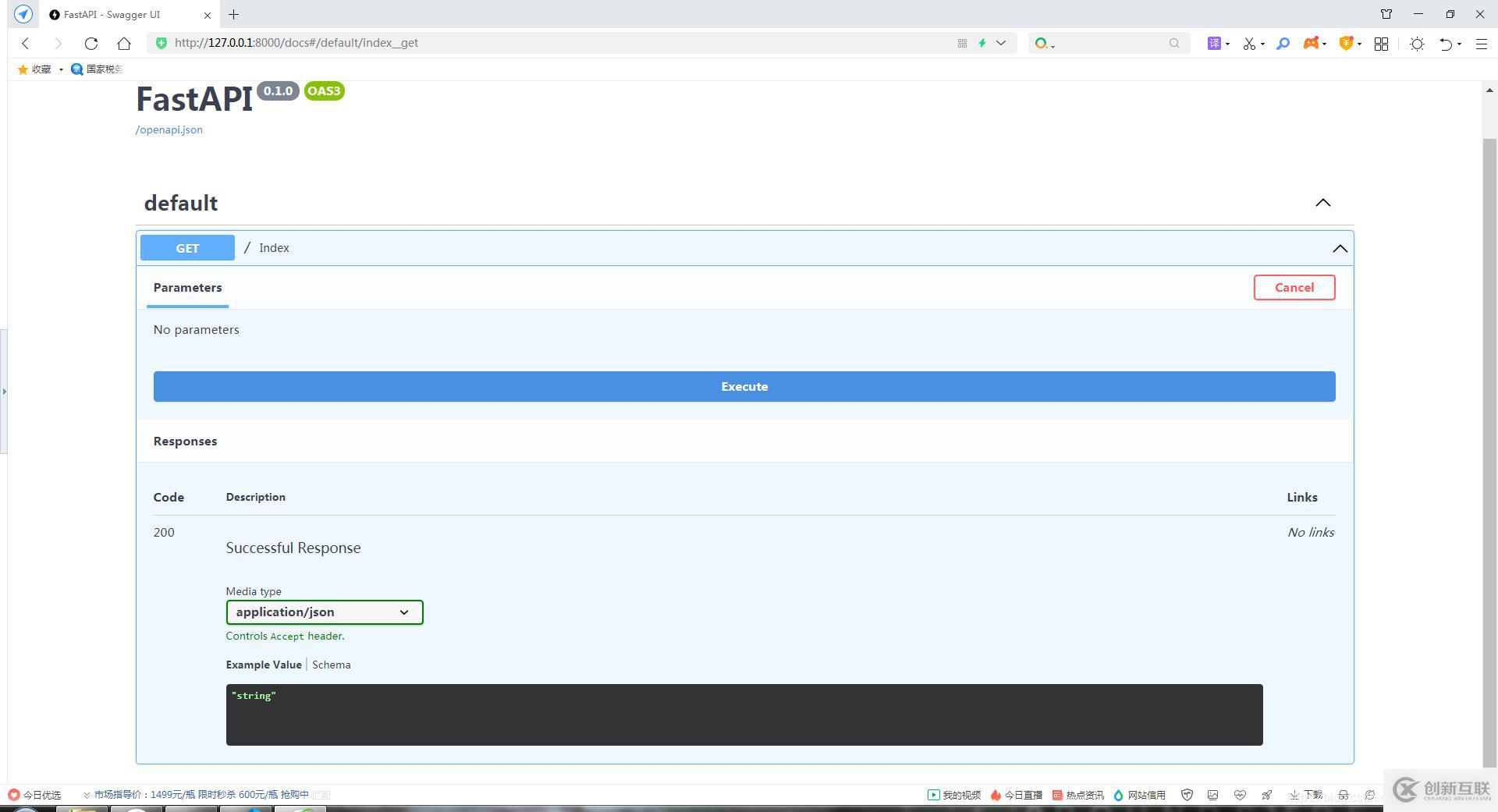
我们也可以访问http://127.0.0.1:8000/docs 来查看当前的所有访问路由并进行测试:
接下来,我们再深入扩展一下,在脚本中定义一个电影类Movie,代码如下所示:
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List
app = FastAPI()
fake_movie_db = [{
'name': 'Star Wars: Episode IX - The Rise of Skywalker', #电影名
'genres': ['Action', 'Adventure', 'Fantasy'], #题材
'casts': ['Daisy Ridley', 'Adam Driver'] # 演员阵容
}]
class Movie(BaseModel):
name: str
genres: List[str]
casts: List[str]
@app.get('/', response_model=List[Movie])
async def index():
return fake_movie_db上述代码中我们创建了一个新的类电影Movie,它从pydantic扩展了BaseModel。电影模型包含名称、题材和演员阵容。Pydantic内置了FastAPI,使得定义模型并对模型进行请求验证变得容易。我们在定义路由时额外使用了response_model=List[Movie],表明我们想要返回类Movie对应的实例对象列表,这里我们返回fake_movie_db。
我们重新运行服务器,然后访问 http://127.0.0.1:8000/docs ,可以看到如下效果:
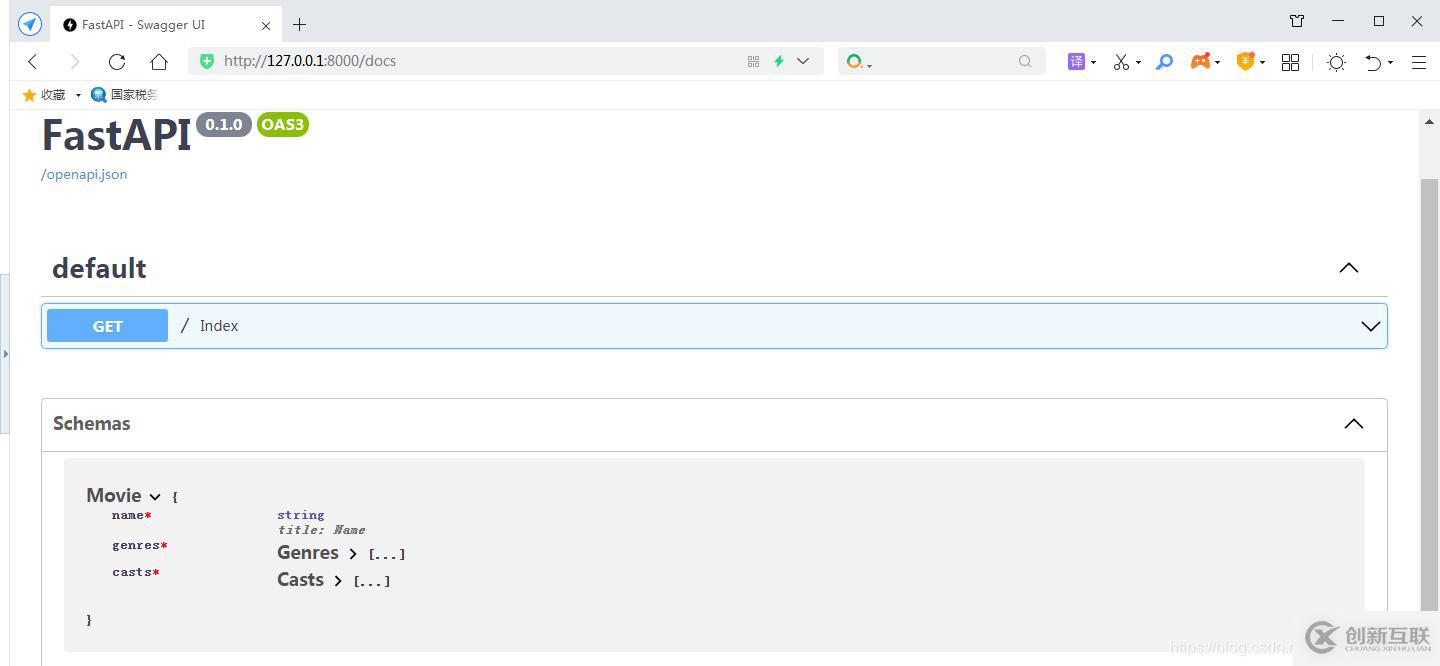
我们可以看到示例响应部分中已经生成了电影模型的字段。
2.2.2 添加接下来,我们添加路由,可以将电影添加到电影列表中。添加新的路由定义来处理POST请求:
@app.post('/', status_code=201)
async def add_movie(payload: Movie):
movie = payload.dict()
fake_movie_db.append(movie)
return {'id': len(fake_movie_db) - 1}重新启动服务器然后测试这个新的API。
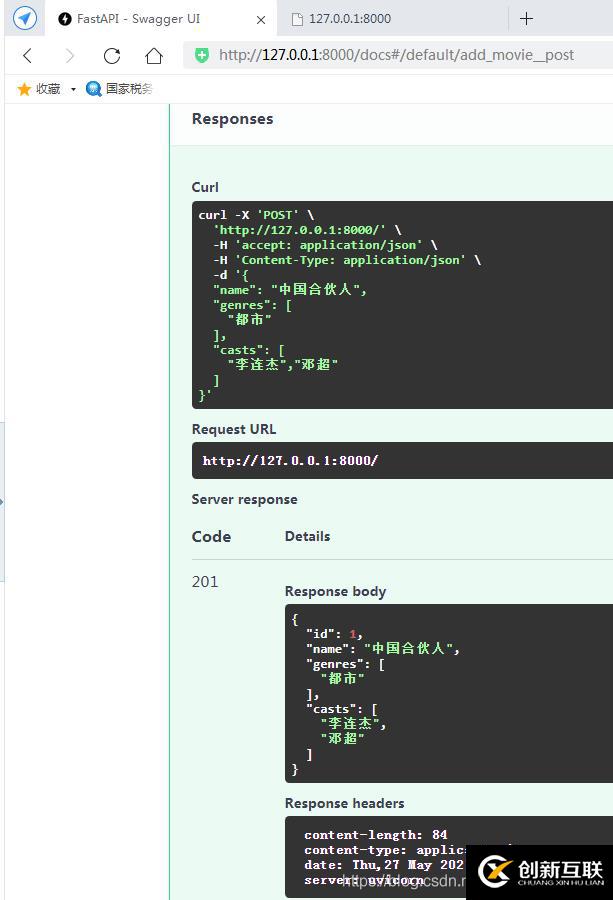
我们先访问http://127.0.0.1:8000/docs,然后测试一下刚添加的api,输入数据如下图所示:
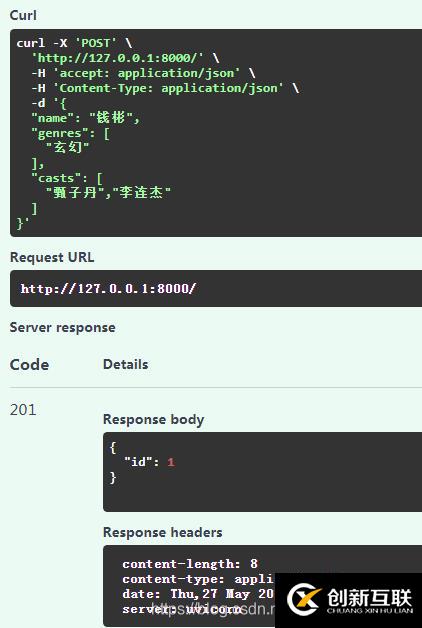
可以看到,系统成功返回了信息。我们成功的添加了一条电影信息。我们重新访问http://127.0.0.1:8000,查询效果如下图所示:

可以看到,我们刚添加的信息已经成功返回了。
2.2.3 修改接下来,我们希望能够通过请求来修改电影列表中的数据,添加代码如下:
from fastapi import HTTPException
@app.put('/{id}')
async def update_movie(id: int, payload: Movie):
movie = payload.dict()
movies_length = len(fake_movie_db)
if 0<= id< movies_length:
fake_movie_db[id] = movie
return None
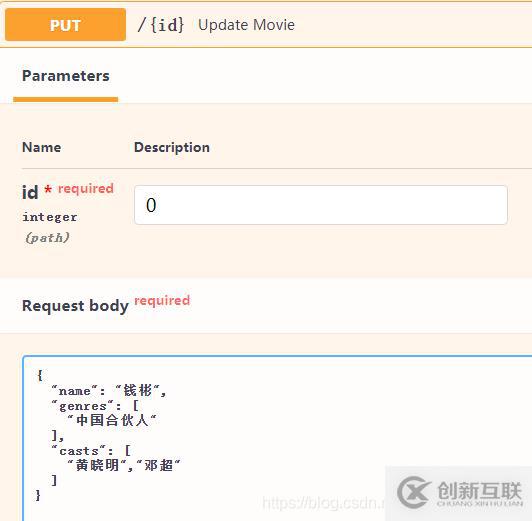
raise HTTPException(status_code=404, detail="Movie with given id not found")上述代码中的id是我们的电影列表中某部电影的索引。我们重新启动服务器,来看下效果。提交数据如下所示:
然后我们重新访问http://127.0.0.1:8000,可以看到效果如下:
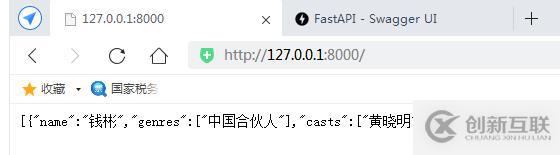
我们看到信息已经被修改了过来。
2.2.4 删除最后我们定义删除接口,添加代码如下:
@app.delete('/{id}')
async def delete_movie(id: int):
movies_length = len(fake_movie_db)
if 0<= id< movies_length:
del fake_movie_db[id]
return None
raise HTTPException(status_code=404, detail="Movie with given id not found")然后我们重新启动服务器,首先使用前面的Post接口添加3条数据,效果如下:

然后使用刚添加的删除接口,首先删除id=0的电影:
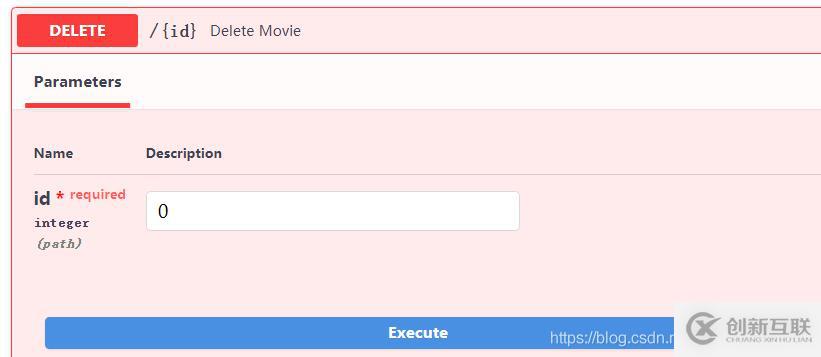
重新访问http://127.0.0.1:8000,效果如下:

可以看到,第一部电影已经删除掉了。
2.3 代码组织通过2.2节我们熟悉了FastAPI基本的增删查改操作,前面我们的代码都是在一个脚本里编写的,这对于大型项目来说是不合适的,我们需要重新组织代码结构,使其更符合大型项目开发需求。
紧接着2.2节的内容。在应用程序中创建新文件夹api,并在api文件夹中创建新的movies.py。将所有与路由相关的代码从main.py移动到movies.py。调整后的movies.py如下所示:
#~/micropro/app/api/movies.py
from typing import List
from fastapi import Header, APIRouter
from fastapi import HTTPException
from app.api.models import Movie
fake_movie_db = [
{
'name': 'Star Wars: Episode IX - The Rise of Skywalker',
'plot': 'The surviving members of the resistance face the First Order once again.',
'genres': ['Action', 'Adventure', 'Fantasy'],
'casts': ['Daisy Ridley', 'Adam Driver']
}
]
movies = APIRouter()
@movies.get('/', response_model=List[Movie])
async def index():
return fake_movie_db
@movies.post('/', status_code=201)
async def add_movie(payload: Movie):
movie = payload.dict()
fake_movie_db.append(movie)
return {'id': len(fake_movie_db) - 1}
@movies.put('/{id}')
async def update_movie(id: int, payload: Movie):
movie = payload.dict()
movies_length = len(fake_movie_db)
if 0<= id< movies_length:
fake_movie_db[id] = movie
return None
raise HTTPException(status_code=404, detail="Movie with given id not found")
@movies.delete('/{id}')
async def delete_movie(id: int):
movies_length = len(fake_movie_db)
if 0<= id< movies_length:
del fake_movie_db[id]
return None
raise HTTPException(status_code=404, detail="Movie with given id not found")上述代码我们使用FastAPI中的APIRouter来注册新的API路由。另外,在api中创建一个新文件models.py,我们将在这个文件中保存我们定义的Pydantic模型。
接下来在main.py文件中注册这些新的路由:
#~/micropro/app/main.py
from fastapi import FastAPI
from app.api.movies import movies
app = FastAPI()
app.include_router(movies)最终我们的应用结构如下:
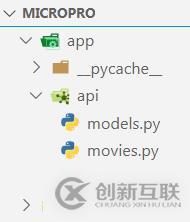
最后,我们重新启动,查看下是否各项功能都正常。
2.4 使用PostgreSQL数据库前面的案例中为了简单我们使用假的Python list来添加电影,在本小节我们将使用更实际的数据库来实现这个功能。本小节我们将使用PostgreSQL数据库。
2.4.1 安装PostgreSQL数据库PostgreSQL是一个功能强大的开源对象关系型数据库系统,他使用和扩展了SQL语言,并结合了许多安全存储和扩展最复杂数据工作负载的功能。PostgreSQL的起源可以追溯到1986年,作为加州大学伯克利分校POSTGRES项目的一部分,并且在核心平台上进行了30多年的积极开发。PostgreSql提供了许多功能,旨在帮助开发人员构建应用程序,管理员保护数据完整性并且构建容错环境,并帮助你管理数据,无论数据集的大小。除了免费和开源之外,Postgre SQL还具有高度的可扩展性。
进入下载页面:PostgreSQL: Downloads,由于我们使用windows系统,因此选择Windows对应的版本下载。下载完成后按照提示进行安装即可。安装完成后我们从开始菜单中找到pgAdmin4,这是PostgreSQL对应的数据库管理软件。
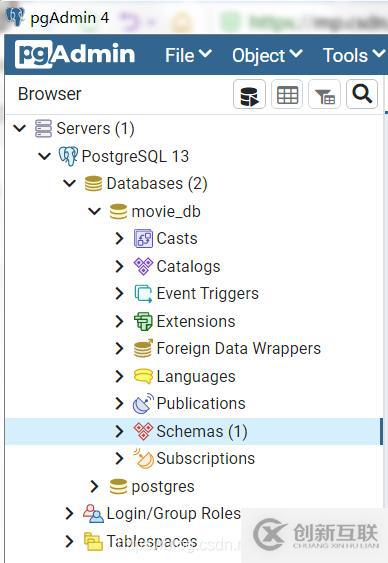
输入密码登陆pgAdmin4以后,我们创建一个名为movie_db数据库用于我们项目的数据管理。如下图所示:
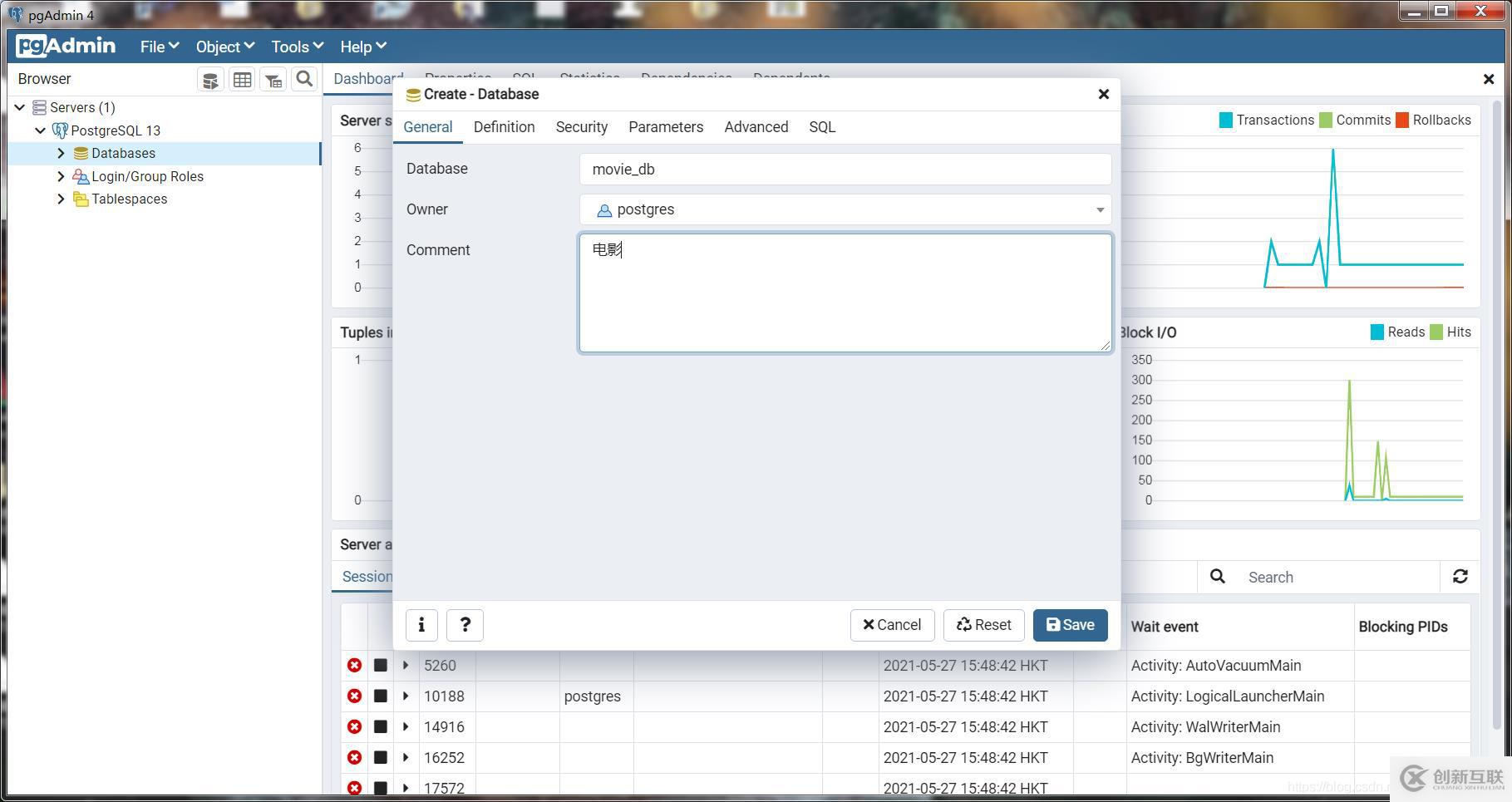
最终效果如下:
为了能够在python中连接PostgreSQL数据库,我们需要依赖第三方库,使用下面的命令安装所需的库:
pip install 'databases[postgresql]'
pip install psycopg2上述命令将同时安装sqlalchemy和asyncpg,这是后面使用PostgreSQL所必需的。
在api中创建一个新文件并将其命名为db.py,这个文件将包含REST API的实际数据库模型:
from sqlalchemy import (Column, Integer, MetaData, String, Table,
create_engine, ARRAY)
from databases import Database
DATABASE_URL = 'postgresql://movie_user:movie_password@localhost/movie_db'
engine = create_engine(DATABASE_URL)
metadata = MetaData()
movies = Table(
'movies',
metadata,
Column('id', Integer, primary_key=True),
Column('name', String(50)),
Column('genres', ARRAY(String)),
Column('casts', ARRAY(String))
)
database = Database(DATABASE_URL)这里,DATABASE_URL是用于连接到PostgreSQL数据库的URL。这里movie_user是数据库用户的名称,movie_password是数据库用户的密码,movie_db是数据库的名称。默认的用户名为postgres,密码即为安装PostgreSQL时设置的密码。上述代码中创建了Movie对应的table。
更新main.py来连接数据库。main.py代码如下所示:
#~/micropro/app/main.py
from fastapi import FastAPI
from app.api.movies import movies
from app.api.db import metadata, database, engine
metadata.create_all(engine)
app = FastAPI()
@app.on_event("startup")
async def startup():
await database.connect()
@app.on_event("shutdown")
async def shutdown():
await database.disconnect()
app.include_router(movies)FastAPI提供了一些事件处理程序,可以在应用程序启动时使用这些处理程序连接到我们的数据库,并在应用程序关闭时断开连接。
接下来我们更新movies.py文件,使其使用数据库而不是Python列表:
#~/micropro/app/api/movies.py
from typing import List
from fastapi import Header, APIRouter,HTTPException
from app.api.models import MovieIn, MovieOut
from app.api import db_manager
movies = APIRouter()
@movies.get('/', response_model=List[MovieOut])
async def index():
return await db_manager.get_all_movies()
@movies.post('/', status_code=201)
async def add_movie(payload: MovieIn):
movie_id = await db_manager.add_movie(payload)
response = {
'id': movie_id,
**payload.dict()
}
return response
@movies.put('/{id}')
async def update_movie(id: int, payload: MovieIn):
movie = await db_manager.get_movie(id)
if not movie:
raise HTTPException(status_code=404, detail="Movie not found")
update_data = payload.dict(exclude_unset=True)
movie_in_db = MovieIn(**movie)
updated_movie = movie_in_db.copy(update=update_data)
return await db_manager.update_movie(id, updated_movie)
@movies.delete('/{id}')
async def delete_movie(id: int):
movie = await db_manager.get_movie(id)
if not movie:
raise HTTPException(status_code=404, detail="Movie not found")
return await db_manager.delete_movie(id)接下来添加db_manager.py文件用于操作数据库:
from app.api.models import MovieIn, MovieOut, MovieUpdate
from app.api.db import movies, database
async def add_movie(payload: MovieIn):
query = movies.insert().values(**payload.dict())
return await database.execute(query=query)
async def get_all_movies():
query = movies.select()
return await database.fetch_all(query=query)
async def get_movie(id):
query = movies.select(movies.c.id==id)
return await database.fetch_one(query=query)
async def delete_movie(id: int):
query = movies.delete().where(movies.c.id==id)
return await database.execute(query=query)
async def update_movie(id: int, payload: MovieIn):
query = (
movies
.update()
.where(movies.c.id == id)
.values(**payload.dict())
)
return await database.execute(query=query)最后更新models.py,以便可以将Pydantic模型与sqlalchemy表一起使用:
#~/micropro/api/models.py
from pydantic import BaseModel
from typing import List, Optional
class MovieIn(BaseModel):
name: str
genres: List[str]
casts: List[str]
class MovieOut(MovieIn):
id: int
class MovieUpdate(MovieIn):
name: Optional[str] = None
genres: Optional[List[str]] = None
casts: Optional[List[str]] = None这里MovieIn是用于将电影添加到数据库的基础类。当我们从数据库取出数据时我们需要使用MovieOut类。MovieUpdate类允许我们将模型中的值设置为可选的,以便在更新电影数据时只更新需要更新的字段。
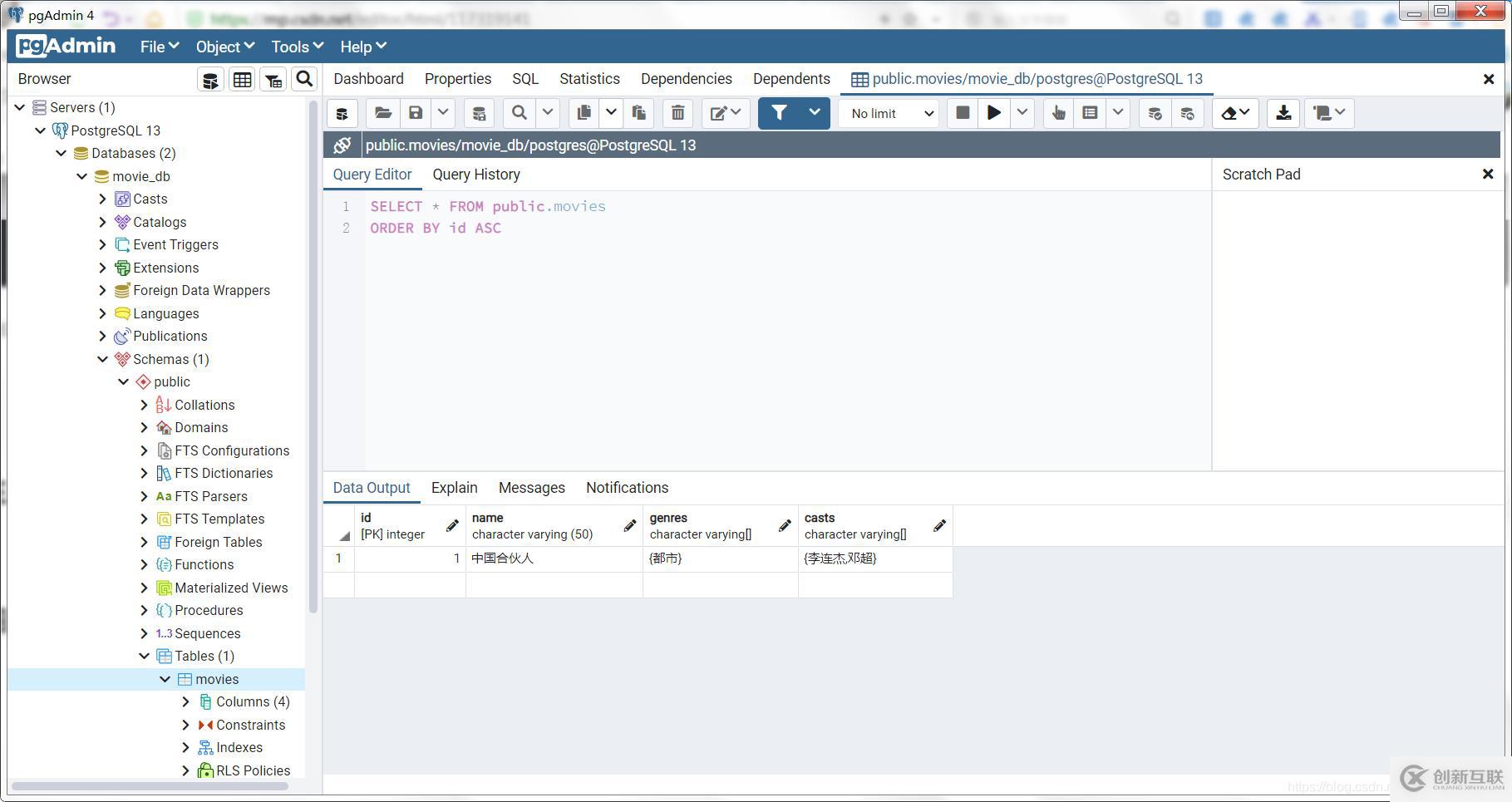
最后,我们启动服务器,然后按照之前的方法添加数据,最后我们在pdAdmin4中查看有没有添加成功,效果如下图所示:
微服务中的数据库管理是一个难点。在构建整个应用时如何拆分数据?如何构建不同微服务的数据库?哪些数据是各个微服务共享的?这些在开发前都需要先仔细的考虑好。本小节给出一些基本的方案和优缺点介绍:
- 一个微服务管理一个独立的数据库
如果希望微服务尽可能松耦合,那么为每个微服务提供一个独立的数据库是比较好的方案。每个微服务有一个不同的数据库允许我们独立地扩展不同的服务。涉及多个数据库的数据操作可以通过微服务之间良好的api实现。这种方式的缺点就是实现涉及多个微服务的业务数据操作比较麻烦,另外,网络开销的增加使得这种方式使用效率降低。
- 共享数据库
如果有很多数据操作涉及多个微服务,那么最好使用共享数据库。这带来了高度一致的应用程序的好处,但也丧失了微服务体系结构带来的大部分好处。在一个微服务上工作的开发人员需要与其他服务中的模式更改相协调。
- API组合
在涉及多个数据库的操作中,API组合充当API网关,并按所需顺序执行对其他微服务的API调用。最后,每个微服务的结果在内存中执行连接后返回给客户机。这种方法的缺点是在内存中进行这种大型数据的链接效率比较低。
总之,到底该选用哪种数据拆分方式并没有一个绝对完美的指导方案,需要根据项目类型、项目复杂度等综合来考量,也需要在试错和实践中来改进。用好微服务架构能够给整个项目带来超强性能的效果。
三、小结本文针对FastAPI微服务开发作了简单介绍,想要快速上手FastAPI的读者可以通过本文快速掌握FastAPI框架特性,能够依样“画葫芦”的将相关功能揉进自己的项目中去。除了数据库相关操作以外,FastAPI最有特色的功能就是集成机器学习和深度学习模型,完成线上AI推理,有兴趣的读者可以参考我的另一篇博文。
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
网站栏目:一文掌握fastapi微服务开发-创新互联
网站路径:https://www.cdcxhl.com/article4/eggoe.html
成都网站建设公司_创新互联,为您提供响应式网站、微信公众号、品牌网站制作、App设计、定制开发、外贸建站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 创新互联网站建设中手机网站制作分屏设计 2016-10-16
- 网站制作关于优化收录点有哪些 2021-08-17
- 上海网站制作都需要注意些什么? 2020-12-02
- 网站制作之服务器知识你了解多少 2021-11-07
- 企业网站制作最容易被忽视的细节有哪些 2021-09-03
- 网站只收录首页有哪些原因 2016-11-03
- 网站制作简单的方法是什么? 2022-08-21
- 成都网站制作浅析网页广告理论与法则 2016-10-19
- 为什么深圳网站制作要设置404页面 2021-10-31
- 微信小程序是怎样颠覆传统电商的? 2014-06-05
- 简述企业的网站制作 2023-03-04
- 手机网站建设,手机网站制作 2023-02-21