strom基础-创新互联
strom 经典图谱:
strom基础
- Topologies
- Streams
- Spouts
- Bolts
- Stream groupings
- Reliability
- Tasks
- Workers
- Configuration
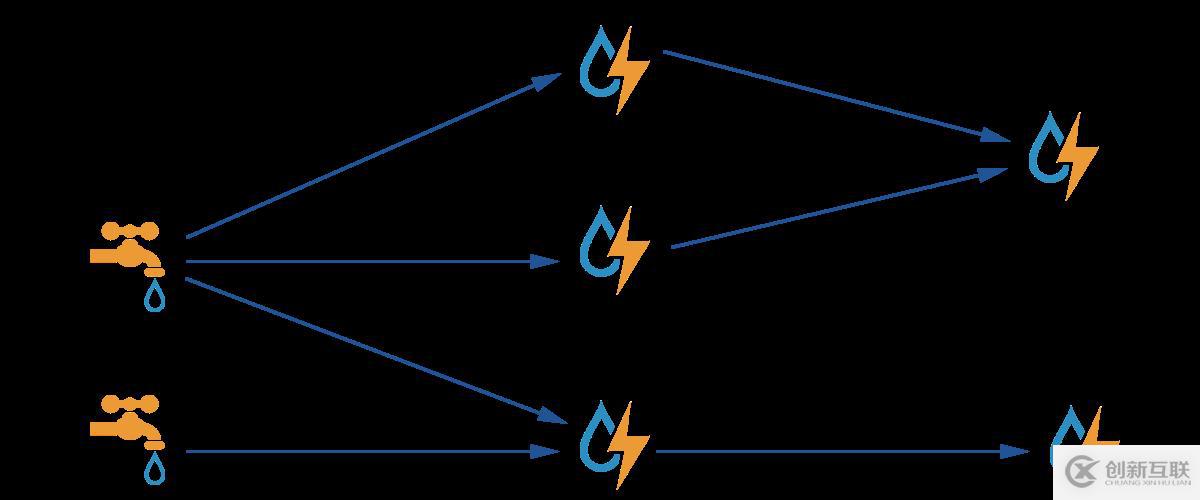
1、Topologies
一个topology是spouts和bolts组成的图, 通过stream groupings将图中的spouts和bolts连接起来,如下图:
一个topology会一直运行直到你手动kill掉,Storm自动重新分配执行失败的任务, 并且Storm可以保证你不会有数据丢失(如果开启了高可靠性的话)。如果一些机器意外停机它上面的所有任务会被转移到其他机器上。
运行一个topology很简单。首先,把你所有的代码以及所依赖的jar打进一个jar包。然后运行类似下面的这个命令:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2这个命令会运行主类: backtype.strom.MyTopology, 参数是arg1, arg2。这个类的main函数定义这个topology并且把它提交给Nimbus。storm jar负责连接到Nimbus并且上传jar包。
Topology的定义是一个Thrift结构,并且Nimbus就是一个Thrift服务, 你可以提交由任何语言创建的topology。上面的方面是用JVM-based语言提交的最简单的方法。
2、Streams
消息流stream是storm里的关键抽象。一个消息流是一个没有边界的tuple序列, 而这些tuple序列会以一种分布式的方式并行地创建和处理。通过对stream中tuple序列中每个字段命名来定义stream。在默认的情况下,tuple的字段类型可以是:integer,long,short, byte,string,double,float,boolean和byte array。你也可以自定义类型(只要实现相应的序列化器)。
每个消息流在定义的时候会被分配给一个id,因为单向消息流使用的相当普遍, OutputFieldsDeclarer定义了一些方法让你可以定义一个stream而不用指定这个id。在这种情况下这个stream会分配个值为‘default’默认的id 。
Storm提供的最基本的处理stream的原语是spout和bolt。你可以实现spout和bolt提供的接口来处理你的业务逻辑。
3、Spouts
消息源spout是Storm里面一个topology里面的消息生产者。一般来说消息源会从一个外部源读取数据并且向topology里面发出消息:tuple。Spout可以是可靠的也可以是不可靠的。如果这个tuple没有被storm成功处理,可靠的消息源spouts可以重新发射一个tuple, 但是不可靠的消息源spouts一旦发出一个tuple就不能重发了。
消息源可以发射多条消息流stream。使用OutputFieldsDeclarer.declareStream来定义多个stream,然后使用SpoutOutputCollector来发射指定的stream。
Spout类里面最重要的方法是nextTuple。要么发射一个新的tuple到topology里面或者简单的返回如果已经没有新的tuple。要注意的是nextTuple方法不能阻塞,因为storm在同一个线程上面调用所有消息源spout的方法。
另外两个比较重要的spout方法是ack和fail。storm在检测到一个tuple被整个topology成功处理的时候调用ack,否则调用fail。storm只对可靠的spout调用ack和fail。
4、Bolts
所有的消息处理逻辑被封装在bolts里面。Bolts可以做很多事情:过滤,聚合,查询数据库等等。
Bolts可以简单的做消息流的传递。复杂的消息流处理往往需要很多步骤,从而也就需要经过很多bolts。比如算出一堆图片里面被转发最多的图片就至少需要两步:第一步算出每个图片的转发数量。第二步找出转发最多的前10个图片。(如果要把这个过程做得更具有扩展性那么可能需要更多的步骤)。
Bolts可以发射多条消息流, 使用OutputFieldsDeclarer.declareStream定义stream,使用OutputCollector.emit来选择要发射的stream。
Bolts的主要方法是execute, 它以一个tuple作为输入,bolts使用OutputCollector来发射tuple,bolts必须要为它处理的每一个tuple调用OutputCollector的ack方法,以通知Storm这个tuple被处理完成了,从而通知这个tuple的发射者spouts。 一般的流程是: bolts处理一个输入tuple, 发射0个或者多个tuple, 然后调用ack通知storm自己已经处理过这个tuple了。storm提供了一个IBasicBolt会自动调用ack。
5、Stream groupings
定义一个topology的其中一步是定义每个bolt接收什么样的流作为输入。stream grouping就是用来定义一个stream应该如果分配数据给bolts上面的多个tasks。
Storm里面有7种类型的stream grouping
- Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
- Fields Grouping:按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts里的一个task, 而不同的userid则会被分配到不同的bolts里的task。
- All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
- Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
- Non Grouping:不分组,这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
- Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
6、Reliability
Storm保证每个tuple会被topology完整的执行。Storm会追踪由每个spout tuple所产生的tuple树(一个bolt处理一个tuple之后可能会发射别的tuple从而形成树状结构),并且跟踪这棵tuple树什么时候成功处理完。每个topology都有一个消息超时的设置,如果storm在这个超时的时间内检测不到某个tuple树到底有没有执行成功, 那么topology会把这个tuple标记为执行失败,并且过一会儿重新发射这个tuple。
为了利用Storm的可靠性特性,在你发出一个新的tuple以及你完成处理一个tuple的时候你必须要通知storm。这一切是由OutputCollector来完成的。通过emit方法来通知一个新的tuple产生了,通过ack方法通知一个tuple处理完成了。
Storm的可靠性我们在第四章会深入介绍。
7、Tasks
每一个spout和bolt会被当作很多task在整个集群里执行。每一个executor对应到一个线程,在这个线程上运行多个task,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。你可以调用TopologyBuilder类的setSpout和setBolt来设置并行度(也就是有多少个task)。
8、Workers
一个topology可能会在一个或者多个worker(工作进程)里面执行,每个worker是一个物理JVM并且执行整个topology的一部分。比如,对于并行度是300的topology来说,如果我们使用50个工作进程来执行,那么每个工作进程会处理其中的6个tasks。Storm会尽量均匀的工作分配给所有的worker。
9、Configuration
Storm里面有一堆参数可以配置来调整Nimbus, Supervisor以及正在运行的topology的行为,一些配置是系统级别的,一些配置是topology级别的。default.yaml里面有所有的默认配置。你可以通过定义个storm.yaml在你的classpath里来覆盖这些默认配置。并且你也可以在代码里面设置一些topology相关的配置信息(使用StormSubmitter)。
另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
网页标题:strom基础-创新互联
网站路径:https://www.cdcxhl.com/article4/cescie.html
成都网站建设公司_创新互联,为您提供域名注册、网站内链、网站营销、软件开发、虚拟主机、App设计
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 百度快照、网站权重、网站排名三者之间是怎样的联系呢 2021-03-01
- 德州网站排名企业SEO优化可以从哪些方面晋升网站权重? 2023-01-15
- 让你的网站排名超越竞争对手 2021-09-29
- 网站排名优化:如何为企业网站带来更多的咨询量? 2022-04-29
- 网站优化修改标题对网站排名有何影响? 2023-04-09
- 昆山seo优化让你的网站排名更好更受欢迎 2020-12-14
- 网站排名稳定的优化方法有哪些? 2015-12-23
- 怎么利用高质量的外链资源提升网站排名 2021-06-15
- 【网站排名优化】社会化媒体在网络营销zhong有什 2016-11-12
- 网站排名不到首页?用户体验、内容质量你真的做好了吗? 2023-04-10
- 网站排名不稳定的原因有哪些? 2015-12-22
- 一个网站排名是否做得上去,TDK的设置很重要! 2023-04-18