Python中怎么分析网站日志数据
Python中怎么分析网站日志数据,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
在武夷山等地区,都构建了全面的区域性战略布局,加强发展的系统性、市场前瞻性、产品创新能力,以专注、极致的服务理念,为客户提供成都做网站、网站制作 网站设计制作定制开发,公司网站建设,企业网站建设,品牌网站建设,全网营销推广,成都外贸网站制作,武夷山网站建设费用合理。
数据来源
import numpy as np import pandas as pd import matplotlib.pyplot as plt import apache_log_parser # 首先通过 pip install apache_log_parser 安装库 %matplotlib inline
fformat = '%V %h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %T' # 创建解析器
p = apache_log_parser.make_parser(fformat)sample_string = 'koldunov.net 85.26.235.202 - - [16/Mar/2013:00:19:43 +0400] "GET /?p=364 HTTP/1.0" 200 65237 "http://koldunov.net/?p=364" "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11" 0' data = p(sample_string) #解析后的数据为字典结构 data

datas = open(r'H:\python数据分析\数据\apache_access_log').readlines() #逐行读取log数据 log_list = [] # 逐行读取并解析为字典 for line in datas: data = p(line) data['time_received'] = data['time_received'][1:12]+' '+data['time_received'][13:21]+' '+data['time_received'][22:27] #时间数据整理 log_list.append(data) #传入列表
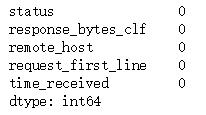
log = pd.DataFrame(log_list) #构造DataFrame log = log[['status','response_bytes_clf','remote_host','request_first_line','time_received']] #提取感兴趣的字段 log.head() #status 状态码 response_bytes_clf 返回的字节数(流量)remote_host 远端主机IP地址 request_first_line 请求内容t ime_received 时间数据
log['time_received'] = pd.to_datetime(log['time_received']) #把time_received字段转换为时间数据类型,并设置为索引
log = log.set_index('time_received')
log.head()
log['status'] = log['status'].astype('int') # 转换为int类型log['response_bytes_clf'].unique() array(['26126', '10532', '1853', ..., '66386', '47413', '48212'], dtype=object)
log[log['response_bytes_clf'] == '-'].head() #对response_bytes_clf字段进行转换时报错,查找原因发现其中含有“-”
def dash3nan(x): # 定义转换函数,当为“-”字符时,将其替换为空格,并将字节数据转化为M数据 if x == '-': x = np.nan else: x = float(x)/1048576 return x
log['response_bytes_clf'] = log['response_bytes_clf'].map(dash3nan) log.head()
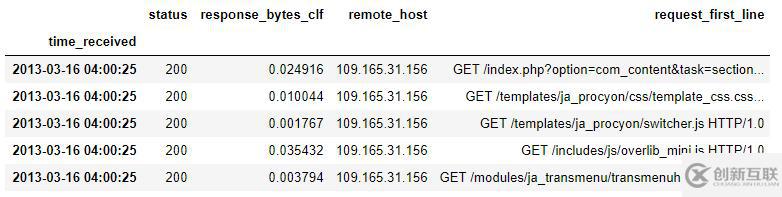
log.dtypes
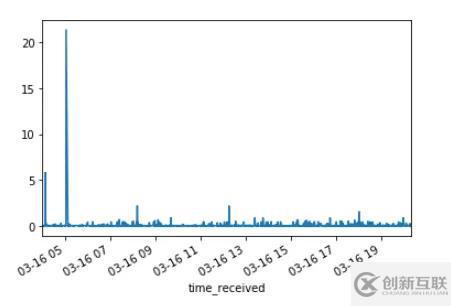
流量起伏不大,但有一个极大的峰值超过了20MB。
log[log['response_bytes_clf']>20] #查看流量峰值
t_log = log['response_bytes_clf'].resample('30t').count()
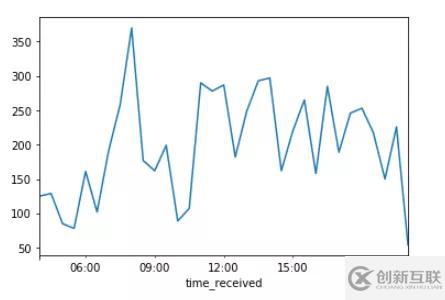
t_log.plot()对时间重采样(30min),并计数 ,可看出每个时间段访问的次数,早上8点访问次数最多,其余时间处于上下波动中。
h_log = log['response_bytes_clf'].resample('H').count()
h_log.plot()当继续转换频率到低频率时,上下波动不明显。
d_log = pd.DataFrame({'count':log['response_bytes_clf'].resample('10t').count(),'sum':log['response_bytes_clf'].resample('10t').sum()})
d_log.head()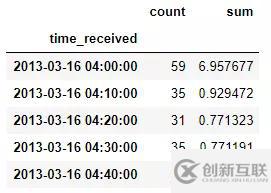
构造访问次数和访问流量的 DataFrame。
plt.figure(figsize=(10,6)) #设置图表大小 ax1 = plt.subplot(111) #一个subplot ax2 = ax1.twinx() #公用x轴 ax1.plot(d_log['count'],color='r',label='count') ax1.legend(loc=2) ax2.plot(d_log['sum'],label='sum') ax2.legend(loc=0)
绘制折线图,有图可看出,访问次数与访问流量存在相关性。
IP地址分析
ip_count = log['remote_host'].value_counts()[0:10] #对remote_host计数,并取前10位 ip_count

ip_count.plot(kind='barh') #IP前十位柱状图
import pygeoip # pip install pygeoip 安装库
# 同时需要在网站上(http://dev.maxmind.com/geoip/legacy/geolite)下载DAT文件才能解析IP地址
gi = pygeoip.GeoIP(r'H:\python数据分析\数据\GeoLiteCity.dat', pygeoip.MEMORY_CACHE)
info = gi.record_by_addr('64.233.161.99')
info #解析IP地址
ips = log.groupby('remote_host')['status'].agg(['count']) # 对IP地址分组统计
ips.head()ips.drop('91.224.246.183',inplace=True)
ips['country'] = [gi.record_by_addr(i)['country_code3'] for i in ips.index] # 将IP解析的国家和经纬度写入DataFrame
ips['latitude'] = [gi.record_by_addr(i)['latitude'] for i in ips.index]
ips['longitude'] = [gi.record_by_addr(i)['longitude'] for i in ips.index]
ips.head()country = ips.groupby('country')['count'].sum() #对country字段分组统计
country = country.sort_values(ascending=False)[0:10] # 筛选出前10位的国家
country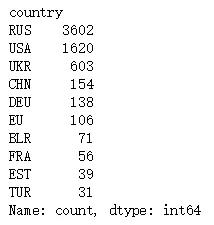
country.plot(kind='bar')
俄罗斯的访问量最多,可推断该网站来源于俄罗斯。
from mpl_toolkits.basemap import Basemap
plt.style.use('ggplot')
plt.figure(figsize=(10,6))
map1 = Basemap(projection='robin', lat_0=39.9, lon_0=116.3,
resolution = 'l', area_thresh = 1000.0)
map1.drawcoastlines()
map1.drawcountries()
map1.drawmapboundary()
map1.drawmeridians(np.arange(0, 360, 30))
map1.drawparallels(np.arange(-90, 90, 30))
size = 0.03
for lon, lat, mag in zip(list(ips['longitude']), list(ips['latitude']), list(ips['count'])):
x,y = map1(lon, lat)
msize = mag * size
map1.plot(x, y, 'ro', markersize=msize)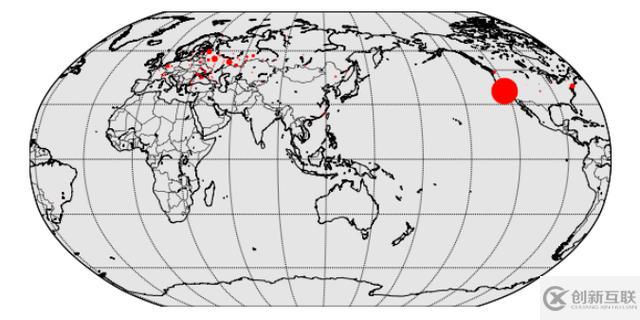
关于Python中怎么分析网站日志数据问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注创新互联行业资讯频道了解更多相关知识。
本文名称:Python中怎么分析网站日志数据
文章地址:https://www.cdcxhl.com/article38/johcsp.html
成都网站建设公司_创新互联,为您提供外贸建站、网站改版、电子商务、关键词优化、App设计、微信小程序
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 品牌网站制作的价格为什么那么高呢? 2016-10-28
- 高端品牌网站制作离不开独特新颖的设计 2016-10-30
- 品牌网站制作常见的布局方式 2022-03-22
- 中小企业品牌网站制作与塑造 2021-12-06
- 如何做好品牌网站制作 2021-11-16
- 广州品牌网站制作有什么特点? 2022-12-20
- 品牌网站制作怎么建设更高效 2021-08-27
- 品牌网站制作想要满意 必须要懂得的三点沟通技巧 2015-08-24
- 品牌网站制作常见的布局方式! 2022-05-11
- 品牌网站制作好方法好步骤有哪些? 2022-06-27
- 品牌网站制作解决方案 2016-09-12
- 高端品牌网站制作策划方案 2021-10-09