如何使用正则表达式实现网页爬虫
这期内容当中小编将会给大家带来有关如何使用正则表达式实现网页爬虫,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
德阳ssl适用于网站、小程序/APP、API接口等需要进行数据传输应用场景,ssl证书未来市场广阔!成为创新互联建站的ssl证书销售渠道,可以享受市场价格4-6折优惠!如果有意向欢迎电话联系或者加微信:028-86922220(备注:SSL证书合作)期待与您的合作!
思路:
1.为模拟网页爬虫,我们可以现在我们的tomcat服务器端部署一个1.html网页。(部署的步骤:在tomcat目录的webapps目录的ROOTS目录下新建一个1.html。使用notepad++进行编辑,编辑内容为:
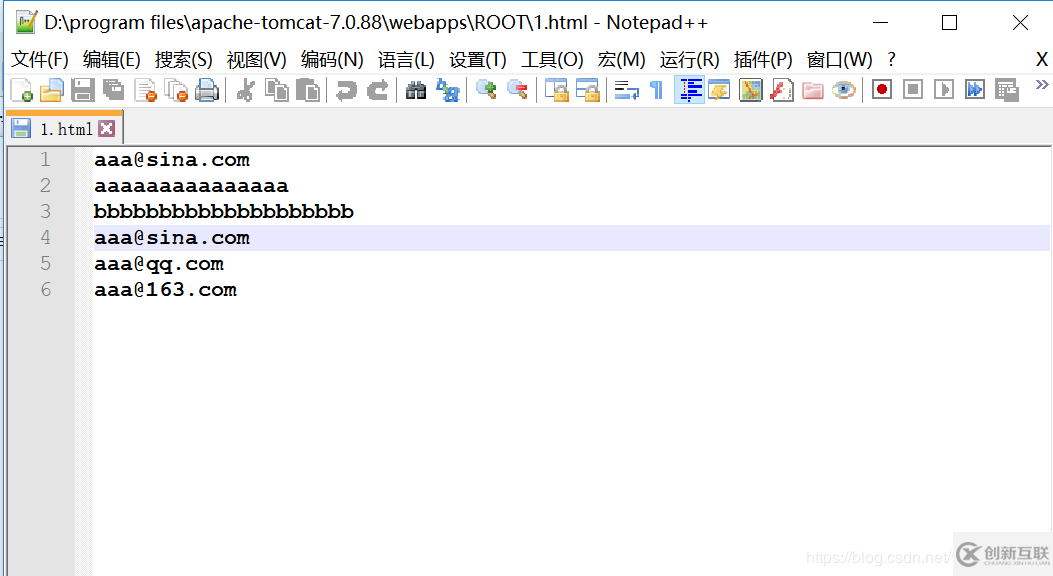 )
)
2.使用URL与网页建立联系
3.获取输入流,用于读取网页中的内容
4.建立正则规则,因为这里我们是爬去网页中的邮箱信息,所以建立匹配 邮箱的正则表达式:String regex="\w+@\w+(\.\w+)+";
5.将提取到的数据放到集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String[] args) throws Exception {
List<String> list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List<String> getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List<String> list=new ArrayList<String>();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}注意:在执行前需要先开启tomcat服务器
运行结果:
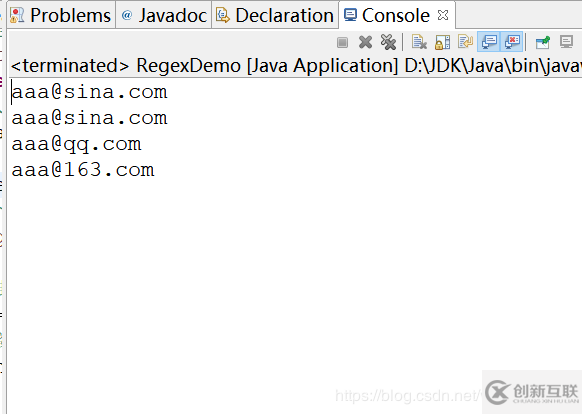
上述就是小编为大家分享的如何使用正则表达式实现网页爬虫了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注创新互联行业资讯频道。
名称栏目:如何使用正则表达式实现网页爬虫
网页网址:https://www.cdcxhl.com/article38/ipgjsp.html
成都网站建设公司_创新互联,为您提供企业建站、微信小程序、网站改版、电子商务、动态网站、微信公众号
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 笑看某同行的电动车商城互联网解决方案 2022-10-26
- 创新互联分享如何根据用户心理特点设计网站及解决方案 2021-04-25
- 5个常见的Ajax问题的解决方案 2016-08-20
- 研究所网站建设的解决方案应该包括哪些内容 2016-09-25
- 提前做好网站解决方案十分有必要 2023-02-21
- ssl证书不受信任怎么办?ssl证书不受信任解决方案有什么? 2022-10-05
- 如何预定完善并极有特色的酒店网站解决方案 2023-03-11
- 资本财富公司金融行业网站制作解决方案 2023-02-26
- 美妆行业微信小程序商城解决方案 2022-08-24
- 百度不收录新网站的原因及解决方案 2020-11-03
- 创新互联干货分享|DNS解析错误的解决方案 2023-02-07
- 英文网站制作中常见的问题及解决方案 2022-06-01