有哪些难懂的Python库
这篇文章主要讲解了“有哪些难懂的Python库”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“有哪些难懂的Python库”吧!
让客户满意是我们工作的目标,不断超越客户的期望值来自于我们对这个行业的热爱。我们立志把好的技术通过有效、简单的方式提供给客户,将通过不懈努力成为客户在信息化领域值得信任、有价值的长期合作伙伴,公司提供的服务项目有:域名与空间、网页空间、营销软件、网站建设、瓯海网站维护、网站推广。
1. Scrapy
每位数据科学家的项目都是从处理数据开始的,而互联网就是最大、最丰富、最易访问的数据库。但可惜的是,除了通过pd.read_html函数来获取数据时,一旦涉及从那些数据结构复杂的网站上抓取数据,数据科学家们大多都会毫无头绪。
Web爬虫常用于分析网站结构和存储提取信息,但相较于重新构建网页爬虫,Scrapy使这个过程变得更加容易。
Scrapy用户界面非常简洁使用感极佳,但其最大优势还得是效率高。Scrapy可以异步发送、调度和处理网站请求,也就是说:它在花时间处理和完成一个请求的同时,也可以发送另一个请求。Scrapy通过同时向一个网站发送多个请求的方法,使用非常快的爬行,以最高效的方式迭代网站内容。
除上述优点外,Scrapy还能让数据科学家用不同的格式(如:JSON,CSV或XML)和不同的后端(如:FTP,S3或local)导出存档数据。

图源:unsplash
2. Statsmodels
到底该采用何种统计建模方法?每位数据科学家都曾对此犹豫不决,但Statsmodels是其中必须得了解的一个选项,它能实现Sci-kit Learn等标准机器学习库中没有的重要算法(如:ANOVA和ARIMA),而它最有价值之处在于其细节化处理和信息化应用。
例如,当数据科学家要用Statsmodels算一个普通最小二乘法时,他所需要的一切信息,不论是有用的度量标准,还是关于系数的详细信息,Statsmodels都能提供。库中实现的其他所有模型也是如此,这些是在Sci-kit learn中无法得到的。
OLSRegressionResults ============================================================================== Dep. Variable: Lottery R-squared: 0.348 Model: OLS Adj. R-squared: 0.333 Method: LeastSquares F-statistic: 22.20 Date: Fri, 21Feb2020 Prob (F-statistic): 1.90e-08 Time: 13:59:15 Log-Likelihood: -379.82 No. Observations: 86 AIC: 765.6 DfResiduals: 83 BIC: 773.0 DfModel: 2 CovarianceType: nonrobust =================================================================================== coef std err t P>|t| [0.025 0.975] ----------------------------------------------------------------------------------- Intercept 246.4341 35.233 6.995 0.000 176.358 316.510 Literacy -0.4889 0.128 -3.832 0.000 -0.743 -0.235 np.log(Pop1831) -31.3114 5.977 -5.239 0.000 -43.199 -19.424 ============================================================================== Omnibus: 3.713 Durbin-Watson: 2.019 Prob(Omnibus): 0.156 Jarque-Bera (JB): 3.394 Skew: -0.487 Prob(JB): 0.183 Kurtosis: 3.003 Cond. No. 702. ==============================================================================
对于数据科学家来说,掌握这些信息意义重大,但他们的问题是常常太过信任一个自己并不真正理解的模型。因为高维数据不够直观,所以在部署这些数据之前,数据科学家有必要深入了解数据与模型。如果盲目追求像准确度或均方误差之类的性能指标,可能会造成严重的负面影响。
Statsmodels不仅具有极其详细的统计建模,而且还能提供各种有用的数据特性和度量。例如,数据科学家们常会进行时序分解,它可以帮助他们更好地理解数据,以及分析何种转换和算法更为合适,或者也可以将pinguoin用于一个不太复杂但非常精确的统计函数。
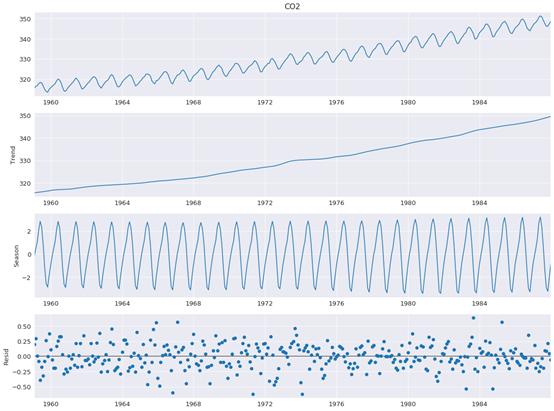
图源:Statsmodels
3. Pattern
一些成熟完善的网站用来检索数据的方法可能更为具体,在这种情况下用Scrapy编写Web爬虫就有点“大材小用”了,而Pattern就是Python中更高级的Web数据挖掘和自然语言处理模块。
Pattern不仅能无缝整合谷歌、推特和维基百科三者的数据,而且还能提供一个不太个性化的Web爬虫和HTML DOM解析器。它采用了词性标注、n-grams搜索、情感分析和WordNet。不论是聚类分析,还是分类处理,又或是网络分析可视化,经Pattern预处理后的文本数据都可用于各种机器学习算法。
从数据检索到预处理,再到建模和可视化,Pattern可以处理数据科学流程中的一切问题,而且它也能在不同的库中快速传输数据。
图源:unsplash
4. Mlxtend
Mlxtend是一个任何数据科学项目都可以应用的库。它可以说是Sci-kit learn库的扩展,能自动优化常见的数据科学任务:
全自动提取与选择特征。
扩展Sci-kit learn库现有的数据转换器,如中心化处理和事务编码器。
大量的评估指标:包括偏差方差分解(即测量模型中的偏差和方差)、特征点检测、McNemar测试、F测试等。
模型可视化,包括特征边界、学习曲线、PCA交互圈和富集图绘。
含有许多Sci-kit Learn库中没有的内置数据集。
图像与文本预处理功能,如名称泛化器,可以识别并转换具有不同命名系统的文本(如:它能识别“Deer,John”,“J.Deer”,“J.D.”和“John Deer”是相同的)。
Mlxtend还有非常实用的图像处理功能,比如它可以提取面部标志:
再来看看它的决策边界绘制功能:
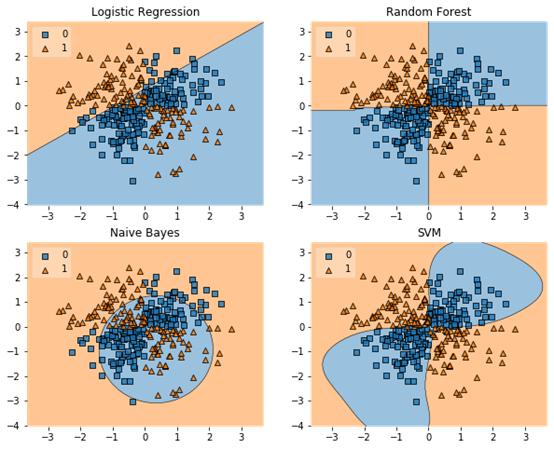
图源:Mlxtend
5. REP
与Mlxtend一样,REP也可以被看作是Sci-kit学习库的扩展,但更多的是在机器学习领域。首先,它是一个统一的Python包装器,用于从Sci-kit-learn扩展而来的不同机器学习库。它可以将Sci-kit learn与XGBoost、Pybrain、Neurolab等更专业的机器学习库整合在一起。
例如,当数据科学家想要通过一个简单的包装器将XGBoost分类器转换为Bagging分类器,再将其转换为Sci-kit-learn模型时,只有REP能做到,因为在其他库中无法找到像这种易于包装和转换的算法。
from sklearn.ensemble importBaggingClassifier from rep.estimators importXGBoostClassifier, SklearnClassifier clf =BaggingClassifier(base_estimator=XGBoostClassifier(), n_estimators=10) clf =SklearnClassifier(clf)
除此之外,REP还能实现将模型从任何库转换为交叉验证(折叠)和堆叠模型。它有一个极快的网格搜索功能和模型工厂,可以帮助数据科学家在同一个数据集里有效地使用多个机器学习分类器。同时使用REP和Sci-kit learn,能帮助我们更轻松自如地构建模型。
感谢各位的阅读,以上就是“有哪些难懂的Python库”的内容了,经过本文的学习后,相信大家对有哪些难懂的Python库这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是创新互联,小编将为大家推送更多相关知识点的文章,欢迎关注!
文章名称:有哪些难懂的Python库
地址分享:https://www.cdcxhl.com/article38/ihhisp.html
成都网站建设公司_创新互联,为您提供小程序开发、用户体验、响应式网站、虚拟主机、云服务器、网站排名
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 哪一家网站制作公司最专业 2015-03-31
- 建站公司的价格会受到哪些因素的影响 2016-10-21
- 成都网站建设:企业网站制作后都有哪些维护工作 2016-10-26
- 网站维护是网站建设后一个不容忽视的问题 2021-04-26
- 网站维护技巧 2021-06-03
- 企业网站维护的现状 2020-07-12
- 网站运营技巧中 如何选择网站虚拟主机 2013-07-31
- 网站制作者就是最好的网站维护者 2021-12-26
- 网站改版需要注意的事项 2013-05-22
- 这款收藏小程序,除了不收钱,别的都收 2014-04-27
- 网站维护是网站建设后不可忽视的问题 2017-02-13
- 建网站应该从哪几个方面提升用户体验 2014-06-30