Flume框架的示例分析
这篇文章给大家分享的是有关Flume框架的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
创新互联一直通过网站建设和网站营销帮助企业获得更多客户资源。 以"深度挖掘,量身打造,注重实效"的一站式服务,以成都网站设计、做网站、移动互联产品、成都全网营销推广服务为核心业务。十年网站制作的经验,使用新网站建设技术,全新开发出的标准网站,不但价格便宜而且实用、灵活,特别适合中小公司网站制作。网站管理系统简单易用,维护方便,您可以完全操作网站资料,是中小公司快速网站建设的选择。
Flume是一个分布式的海量数据收集框架.
Flume框架流程图
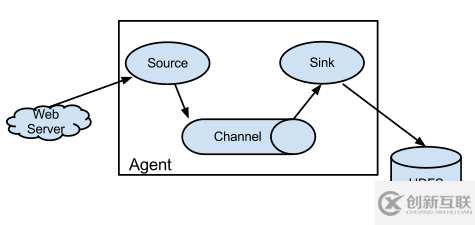
Channel是缓存的数据,如果Sink传送给了HDFS,Channel中缓存的数据就会删除,如果没有传送成功,Channel相当于做了备份,Sink重复从Channel中取数据.
在hadoop0上部署一个Flume agent
1、把apache-flume-1.4.0-bin.tar.gz和apache-flume-1.4.0-src.tar.gz在hadoop0上解压缩.
2、把解压缩后的apache-flume-1.4.0-src文件夹中的内容全部复制到apache-flume-1.4.0.-bin文件夹中.
3、修改conf目录下的两个文件的名称,一个是flume-env.sh,一个是flume-conf.properties.
其中在flume-env.sh中设置了JAVA_HOME值.
4、实例:把磁盘文件夹中文件通过flume上传到HDFS中.
4.1 在conf目录下创建一个文件,叫做test.conf,文件内容如下:
#配置代理
#a1是一个代理名称,s1是source的名称,sink1是sink的名称,c1是channel的名称
a1.sources = s1
a1.sinks = sink1
a1.channels = c1
#配置一个专用于从文件夹中读取数据的source
a1.sources.s1.type = spooldir
a1.sources.s1.spoolDir = /apache_logs #值apache_logs表示数据文件的目录
a1.sources.s1.fileSuffix=.abc #值.abc表示数据文件被处理完后,被重命名的文件名后缀
a1.sources.s1.channels = c1 #值c1表示source接收数据后送到的channel的名称
#配置一个专用于把输入写入到hdfs的sink
a1.sinks.sink1.type = hdfs
a1.sinks.sink1.hdfs.path=hdfs://hadoop0:9000/apache_logs #值表示目的地
a1.sinks.sink1.hdfs.fileType=DataStream #值DataStream表示文件类型,是不经过压缩的
a1.sinks.sink1.hdfs.writeFormat=Text #值表示写出文件原内容
a1.sinks.sink1.channel = c1 #值c1表示sink处理数据的来源
#配置一个内存中处理的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
运行:[root@hadoop conf]# ../bin/flume-ng agent --conf conf --conf-file test.conf --name a1 -Dflume.root.looger=DEBUG,console
感谢各位的阅读!关于“Flume框架的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
分享标题:Flume框架的示例分析
当前链接:https://www.cdcxhl.com/article36/jgscpg.html
成都网站建设公司_创新互联,为您提供网站内链、App开发、外贸网站建设、响应式网站、手机网站建设、定制开发
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 智能手环APP开发的重要性 2020-12-31
- 成都蛋糕店APP开发实现了用户什么需求? 2023-02-06
- 成都电影app开发 2022-06-23
- APP开发与网站建设开发都有哪些区别? 2016-09-09
- 互联网宣传,成都app开发还是平台开发? 2022-07-13
- 郑州词典APP开发提供哪些功能呢? 2023-02-20
- 石家庄app开发应该选择原生开发还是混合开发? 2023-03-25
- 成都APP开发:让营销变得更简单 2022-07-09
- 枣庄商城APP开发选原生还是混合开发? 2020-12-06
- 北京APP开发:在线课程的功能要点 2023-02-25
- 江西APP开发多少钱?什么价格才算合理 2020-12-30
- 成都APP开发需要多少钱?开发一款APP费用如何算的? 2022-06-24