web开发中如何创建和遍历二叉树
这篇文章给大家分享的是有关web开发中如何创建和遍历二叉树的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
创新互联建站是专业的鄢陵网站建设公司,鄢陵接单;提供做网站、成都网站建设,网页设计,网站设计,建网站,PHP网站建设等专业做网站服务;采用PHP框架,可快速的进行鄢陵网站开发网页制作和功能扩展;专业做搜索引擎喜爱的网站,专业的做网站团队,希望更多企业前来合作!
0. 前言
二叉树的创建及遍历的代码实现,其中包括递归遍历和栈遍历。
1. 二叉树的实现思路
1.0. 顺序存储数组实现
前面介绍了满二叉树和完全二叉树,我们对其进行了编号从 0 到 n 的不中断顺序编号,而恰好,数组也有一个这样的编号数组下标,只要我们把二者联合起来,数组就能存储二叉树了。
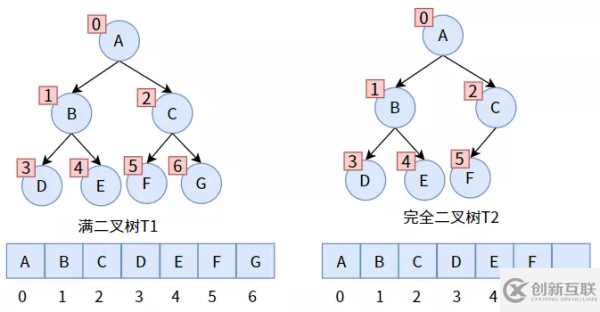
那么非满、非完全二叉树怎么使用数组存储呢?
我们可以在二叉树中补上一些虚构的结点,构造出来一个满/完全二叉树来,存储到数组中时,虚构的结点对应的数组元素不存储数据(# 代表虚构的不存在)。如下图:
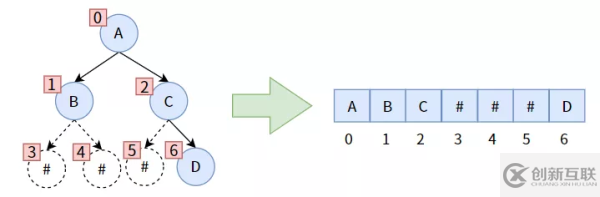
这样存储的缺点是,数组中可能会有大量空间未用到,造成浪费。
1.1. 链式存储——链表实现
我们画树的图时,采用的都是结点加箭头的方式,结点表示数据元素,箭头表示结点之间的关系,清晰明了。如果你对链表熟悉,那么肯定能觉察到这是典型的链式结构。链式结构完美解决了顺序结构中可能会浪费空间的缺点,而且也不会有数组空间限制。
下面来分析一下结点的结构。
树的结点包括一个数据元素和若干指向其子树分支。二叉树的结点相对简单,包括:
数据元素
左子树分支(结点的左孩子)
右子树分支(结点的右孩子)
怎么来实现呢?单链表的结点是使用一个指向其后继结点的指针来表示其关系的。同样地,我们也可以使用指针来表示结点和其左孩子、右孩子的关系。
分析到这,二叉树的结点就清晰了:
一个存储数据的变量data
一个指向其左孩子结点的指针left_child
一个指向其右孩子结点的指针right_child
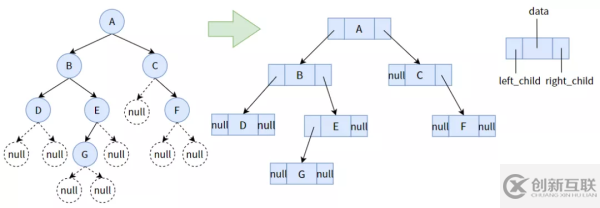
用 C 语言的结构体实现二叉树的结点(为了方便起见,我们的数据全为字符类型):
/*二叉树的结点的结构体*/ typedef struct Node { char data; //数据域 struct Node *left_child; //左孩子指针 struct Node *right_child; //右孩子指针 } TreeNode;2. 二叉树的创造
二叉树的定义是递归的定义,所以如果你想要创造一个二叉树,也可以借助递归去创造。如何递归创造呢?在现实中,一棵树先长根、再长枝干、最后长叶子。我们用代码创造树时,也遵守这个原则,即先创造根结点,然后左子树,最后右子树。整个过程和先序遍历相似。
我以前写过的文章中有二叉树创建过程的动态图[1],这里不再赘述。
这里以创造下图中的树为例:
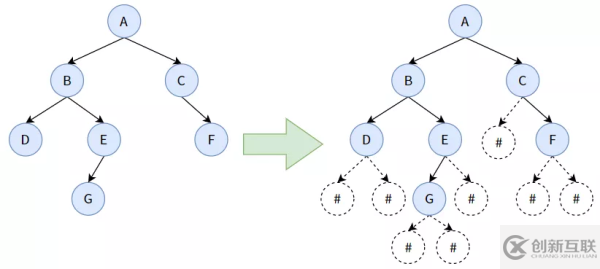
说明:当我们看到如左图的二叉树时,要立即能脑补出对应的右图。#结点是什么?
前面我们已经画出了类似的图,当时是 NULL 结点,它的作用是标识某个结点没有孩子,它是我们虚构出来的。在实际使用 C 语言创造二叉树时,需要使用 #或者什么其他的符号来代替 NULL.
上图的先序遍历顺序为:ABDEGCF,如果加上 # 结点,则为:ABD##EG###C#F##. 我们按照此顺序来创造二叉树。
代码如下:
/** * 创造一个二叉树 * root: 指向根结点的指针的指针 */ void create_binary_tree(TreeNode **root) { char elem; scanf("%c", &elem); if (elem == '#') { *root = NULL; } else { *root = create_tree_node(elem); //创造一个二叉结点 create_binary_tree(&((*root)->left_child)); create_binary_tree(&((*root)->right_child)); } }请注意,函数 create_binary_tree 接受的是一个指向根结点的指针的指针,至于为什么要使用指针的指针,理由在介绍单链表的初始化时已经解释了。
3. 二叉树的遍历
在文章【二叉树的概念和原理】中已经介绍了遍历的原理了,下面使用 C 语言实现它。
3.0. 遍历实质
二叉树的定义是递归的定义,即在二叉树的定义中又用到了二叉树的定义。所以无论是在创造二叉树,还是在遍历二叉树,我们要做的只有三件事:访问根结点、找左子树、找右子树。所谓先序、中序、后序遍历,无非是这三件事的顺序罢了。
3.1. 递归实现
我们如果使用递归代码,很容易就能实现遍历,而且代码非常简洁。
【先序遍历】
/** * 先序遍历 * root: 指向根结点的指针 */ void preorder_traversal(TreeNode *root) { if (root == NULL) { //若二叉树为空,做空操作 return; } printf("%c ", root->data); //访问根结点 preorder_traversal(root->left_child); //递归遍历左子树 preorder_traversal(root->right_child); //递归遍历右子树 }【中序遍历】
/** * 中序遍历 * root: 指向根结点的指针 */ void inorder_traversal(TreeNode *root) { if (root == NULL) { //若二叉树为空,做空操作 return; } inorder_traversal(root->left_child); //递归遍历左子树 printf("%c ", root->data); //访问根结点 inorder_traversal(root->right_child); //递归遍历右子树 }【后序遍历】
/** * 后序遍历 * root: 指向根结点的指针 */ void postorder_traversal(TreeNode *root) { if (root == NULL) { //若二叉树为空,做空操作 return; } postorder_traversal(root->left_child); //递归遍历左子树 postorder_traversal(root->right_child); //递归遍历右子树 printf("%c ", root->data); //访问根结点 }事实上,大部分使用递归做的事,使用栈也可以做到。下面介绍遍历的栈实现。
3.2. 栈实现
我们利用了栈的后进先出的特性,
栈实现的代码较复杂,受篇幅限制,这里只介绍先序遍历和后序遍历,详细代码请移步至代码仓库查看。
【先序遍历】
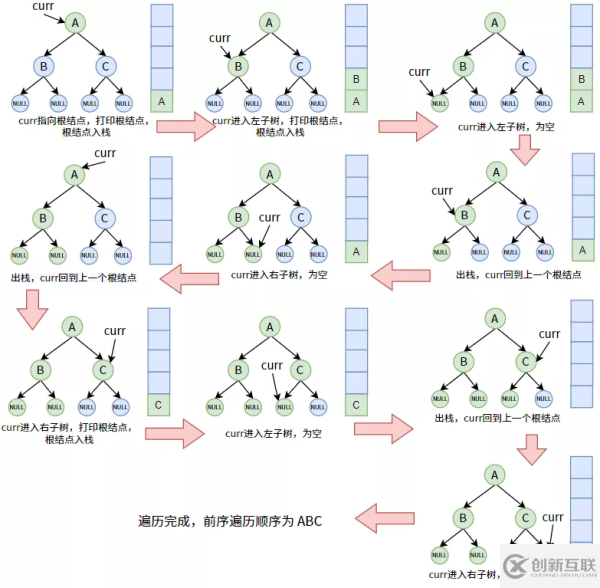
使用栈的先序遍历
我们的树的结点是要全部都入栈的(暂不管顺序如何),那么入栈的条件是什么?就是该结点可以被看作某棵树(子树)的根结点的时候。即,curr 指针指向的结点一定为某颗树(子树)的根结点。
在【二叉树的概念和原理】中,我们已经看到了,遍历完某个子树时,一定要回到其双亲结点。这种回溯如何实现?可以利用栈的先进后出、后进先出的特点,这个特点能在栈中完美保存结点在树中父子关系,栈顶元素即为当前子树的双亲结点。
/** * 使用栈实现的先序遍历 */ void preorder_traversal_by_stack(TreeNode *root) { //创造并初始化栈 Stack stack; init_stack(&stack); TreeNode *curr = root; //辅助指针curr while (curr != NULL || !stack_is_empty(&stack)) { while (curr != NULL) { printf("%c", curr->data); //打印根结点 push(&stack, curr); //根结点入栈 curr = curr->left_child; //进入左子树 } if (!stack_is_empty(&stack)) { pop(&stack, &curr); //出栈,回到上一个根结点 curr = curr->right_child; //进入右子树 } } }【后序遍历】
后序遍历相较于前序和中序较为麻烦,不像前序和中序遍历那样。因为前序和中序的根结点在右子树之前,所以我们可以在出栈的时候同时进行打印根结点和进入右子树。
后序遍历的根结点在右子树之后,这就要求我们再遍历完左子树后,先返回到根结点,然后进入右子树,遍历完右子树之后,再回到根结点,才能打印它。
关键之处还在于左子树、右子树、根结点的顺序。
所以当 curr 指针遍历完左子树后,我们不能直接将根结点出栈,而是先从栈顶读取到根结点,然后 curr 指针返回到根结点,然后 curr 指针进入右子树进行遍历,当右子树遍历完成后,将根结点出栈,才能打印根结点。
这样一来,后序遍历就有两次回到根结点的动作,且这两次的后续动作不一样。第一次通过读取栈顶回到根结点,然后进入右子树;第二次通过出栈回到根结点,然后打印根结点。
这样看似解决了后序遍历的顺序问题,但其实又得到了一个新的问题,即,我们如何知道右子树被遍历完了?
我们有两次回到根结点的动作,对于写代码的人来说,我们知道两次回到根结点之后该干什么,知道右子树是否被遍历完了。但是对于 curr 指针来说,它不知道,两次回到根结点,它都不知道右子树是否被遍历完成了。
此时,对于curr 指针来说,就像有两条路摆在它面前让它选择其中一条,它难以抉择。如果当其中一条有过它的脚印,那么它就很容易选择那条没走过的路了。
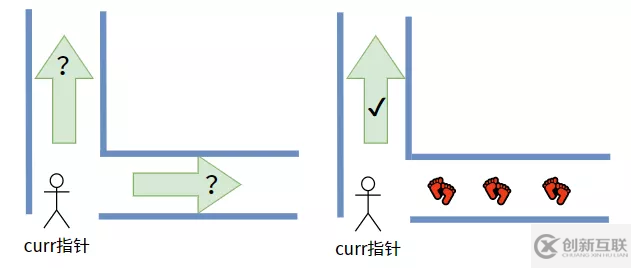
所以我们现在还需要一个“脚印”指针——prev,prev指针用来记录 curr访问过的结点。
当 curr 指针第二次回到根结点的时候,一看,哦!我的脚印留在那呢!(prev指针指在右子树那里)curr 指针就直接放心打印根结点了。
/** * 使用栈实现的后序遍历 */ void postorder_traversal_by_stack(TreeNode *root) { Stack stack; init_stack(&stack); TreeNode *curr = root; //辅助指针curr,记录当前访问结点 TreeNode *prev = NULL; //脚印指针prev,记录上一个访问过的结点 while (curr != NULL || !stack_is_empty(&stack)) { if (curr != NULL) { push(&stack, curr); //根结点入栈 curr = curr->left_child; //进入左子树 } else { get_top(&stack, &curr); //读栈顶元素,不是出栈 //右子树不为空,且右子树没被遍历 if (curr->right_child != NULL && curr->right_child != prev) { curr = curr->right_child; //进入右子树 push(&stack, curr); //根结点入栈 curr = curr->left_child; //进入左子树 } else { //右子树已被遍历或者右子树为空,可以打印根结点了 pop(&stack, &curr); //根结点出栈 printf("%c", curr->data); //打印根结点 prev = curr; //记录 curr = NULL; //置空,进入下一轮循环 } } } }感谢各位的阅读!关于“web开发中如何创建和遍历二叉树”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
网站题目:web开发中如何创建和遍历二叉树
网址分享:https://www.cdcxhl.com/article36/ijjesg.html
成都网站建设公司_创新互联,为您提供面包屑导航、虚拟主机、域名注册、网站收录、网站策划、搜索引擎优化
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联
