Session重叠问题学习(三)--优化
接前文
http://blog.itpub.net/29254281/viewspace-2150229/
前文中的算法想了一天半,终于在昨天晚上得出了正确的结果.
在我的环境中,耗时90s ,还有进一步优化的空间.
首选是生成 t1 和 t2的方式.
之前使用create table 方式 导致类型不对,
因为是临时作用的表,所以可以预先创建表结构
CREATE TABLE `t1` (
`roomid` int(11) NOT NULL DEFAULT '0',
`userid` bigint(20) NOT NULL DEFAULT '0',
`s` timestamp ,
`e` timestamp,
primary KEY (`roomid`,`userid`,`s`,`e`),
KEY (`roomid`,`s`,`e`)
) ;
CREATE TABLE `t2` (
`roomid` int(11) NOT NULL DEFAULT '0',
`userid` bigint(20) NOT NULL DEFAULT '0',
`s` timestamp ,
`e` timestamp,
primary KEY (`roomid`,`userid`,`s`,`e`),
KEY (`roomid`,`s`,`e`)
) ;
前文中的第一步可以封装为一个过程
函数修改如下
原来是针对每天每个房间处理,经过优化对某天的所有房间进行处理,批量的形式更快
另外在中间过程增加了类型转换,可以更好的利用索引
select roomid,CAST(starttime as DATETIME) starttime,CAST(endtime as DATETIME) endtime
另外第7行 原来没有 distinct 可能导致bug
select distinct v6.roomid,v6.userid,greatest(s,starttime) s,least(e,endtime) e
调用时执行:
truncate table t1;
truncate table t2;
call p;
select f(s) from (
select distinct date(s) s from t1
) t
两步的执行时间:
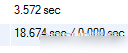
今天优化了一天,从90s优化到25s以内,已经达到了预期。
我觉得在单线程环境,基本上已经达到最优.
如果还想优化到极致,第二步的函数执行,可以通过JAVA程序多线程一起跑,只要服务器CPU核数多,优化效果应该还是很明显的。
http://blog.itpub.net/29254281/viewspace-2150229/
前文中的算法想了一天半,终于在昨天晚上得出了正确的结果.
在我的环境中,耗时90s ,还有进一步优化的空间.
首选是生成 t1 和 t2的方式.
之前使用create table 方式 导致类型不对,
因为是临时作用的表,所以可以预先创建表结构
CREATE TABLE `t1` (
`roomid` int(11) NOT NULL DEFAULT '0',
`userid` bigint(20) NOT NULL DEFAULT '0',
`s` timestamp ,
`e` timestamp,
primary KEY (`roomid`,`userid`,`s`,`e`),
KEY (`roomid`,`s`,`e`)
) ;
CREATE TABLE `t2` (
`roomid` int(11) NOT NULL DEFAULT '0',
`userid` bigint(20) NOT NULL DEFAULT '0',
`s` timestamp ,
`e` timestamp,
primary KEY (`roomid`,`userid`,`s`,`e`),
KEY (`roomid`,`s`,`e`)
) ;
前文中的第一步可以封装为一个过程
- DELIMITER $$
- CREATE DEFINER=`root`@`localhost` PROCEDURE `p`()
- BEGIN
- insert into t1
- select distinct
- roomid,
- userid,
- if(date(s)!=date(e) and id>1,date(s+interval id-1 date(s+interval id-1 date(e) ,e,date_format(s+interval id-1 '%Y-%m-%d 23:59:59')) e
- from (
- SELECT DISTINCT s.roomid, s.userid, s.s, (
- SELECT MIN(e)
- FROM (SELECT DISTINCT roomid, userid, roomend AS e
- FROM u_room_log a
- WHERE NOT EXISTS (SELECT *
- FROM u_room_log b
- WHERE a.roomid = b.roomid
- AND a.userid = b.userid
- AND a.roomend >= b.roomstart
- AND a.roomend < b.roomend)
- ) s2
- WHERE s2.e > s.s
- AND s.roomid = s2.roomid
- AND s.userid = s2.userid
- ) AS e
- FROM (SELECT DISTINCT roomid, userid, roomstart AS s
- FROM u_room_log a
- WHERE NOT EXISTS (SELECT *
- FROM u_room_log b
- WHERE a.roomid = b.roomid
- AND a.userid = b.userid
- AND a.roomstart > b.roomstart
- AND a.roomstart <= b.roomend)
- ) s, (SELECT DISTINCT roomid, userid, roomend AS e
- FROM u_room_log a
- WHERE NOT EXISTS (SELECT *
- FROM u_room_log b
- WHERE a.roomid = b.roomid
- AND a.userid = b.userid
- AND a.roomend >= b.roomstart
- AND a.roomend < b.roomend)
- ) e
- WHERE s.roomid = e.roomid
- AND s.userid = e.userid
- ) t1 ,
- nums
- where nums.id<=datediff(e,s)+1
- ;
- END
函数修改如下
- DELIMITER $$
- CREATE DEFINER=`root`@`localhost` FUNCTION `f`(pTime timestamp) RETURNS int(11)
- BEGIN
- declare pResult bigint;
- insert into t2
- select distinct v6.roomid,v6.userid,greatest(s,starttime) s,least(e,endtime) e
- from (
- select roomid,as DATETIME) starttime,as DATETIME) endtime from (
- select @d as starttime,@d:=d,v3.roomid,v3.d endtime from (
- select distinct roomid,
- when nums.id=1 then v1s
- when nums.id=2 then v1e
- when nums.id=3 then v2s
- when nums.id=4 then v2e
- end d from (
- select v1.roomid, v1.s v1s,v1.e v1e,v2.s v2s,v2.e v2e
- from t1 v1
- inner join t1 v2 on ((v1.s between v2.s and v2.e or v1.e between v2.s and v2.e ) and v1.roomid=v2.roomid)
- where v2.roomid in(select distinct roomid from t1 where date(s)=pTime)
- and v2.s>=pTime and v2.s<(pTime+interval '1' and (v2.roomid,v2.userid,v2.s,v2.e)!= (v1.roomid,v1.userid,v1.s,v1.e)
- ) a,nums where nums.id<=4
- order by roomid,d
- ) v3,(select @d:='') vars
- ) v4 where starttime!=''
- ) v5 inner join t1 v6 on(v5.starttime between v6.s and v6.e and v5.endtime between v6.s and v6.e and v5.roomid=v6.roomid)
- ;
- select row_count() into pResult;
- RETURN pResult;
- END
原来是针对每天每个房间处理,经过优化对某天的所有房间进行处理,批量的形式更快
另外在中间过程增加了类型转换,可以更好的利用索引
select roomid,CAST(starttime as DATETIME) starttime,CAST(endtime as DATETIME) endtime
另外第7行 原来没有 distinct 可能导致bug
select distinct v6.roomid,v6.userid,greatest(s,starttime) s,least(e,endtime) e
调用时执行:
truncate table t1;
truncate table t2;
call p;
select f(s) from (
select distinct date(s) s from t1
) t
两步的执行时间:
今天优化了一天,从90s优化到25s以内,已经达到了预期。
我觉得在单线程环境,基本上已经达到最优.
如果还想优化到极致,第二步的函数执行,可以通过JAVA程序多线程一起跑,只要服务器CPU核数多,优化效果应该还是很明显的。
文章题目:Session重叠问题学习(三)--优化
路径分享:https://www.cdcxhl.com/article36/ijjcsg.html
成都网站建设公司_创新互联,为您提供微信公众号、微信小程序、用户体验、面包屑导航、定制开发、云服务器
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 成都外贸网站建设都有哪些途径获取有效流量? 2016-03-28
- 外贸网站建设:外贸网站制作价格范围,外贸网络推广和运营方式解决方案。 2021-05-13
- 外贸网站建设公司如何选择? 2022-06-20
- 外贸网站建设价格选择 2015-12-25
- 成都外贸网站建设 2022-07-09
- 外贸网站建设需要注意的几个方面 2016-11-08
- 网站建设公司模板,外贸网站建设公司 2022-11-22
- 外贸网站建设的主要规划目标 2023-02-27
- 成都外贸网站建设需要注意什么? 2017-11-19
- 外贸网站建设如何提高网站转化 2023-03-22
- 外贸网站建设开发不容忽视的因素与注意事项 2022-05-02
- 成都外贸网站建设值得注意的四个方面 2018-02-25