记一次不太成功的爬取dingtalk上的企业的信息
首先打开这个链接https://www.dingtalk.com/qiye/1.html,可以网页列出了很多企业,点击企业,就看到了企业的信息。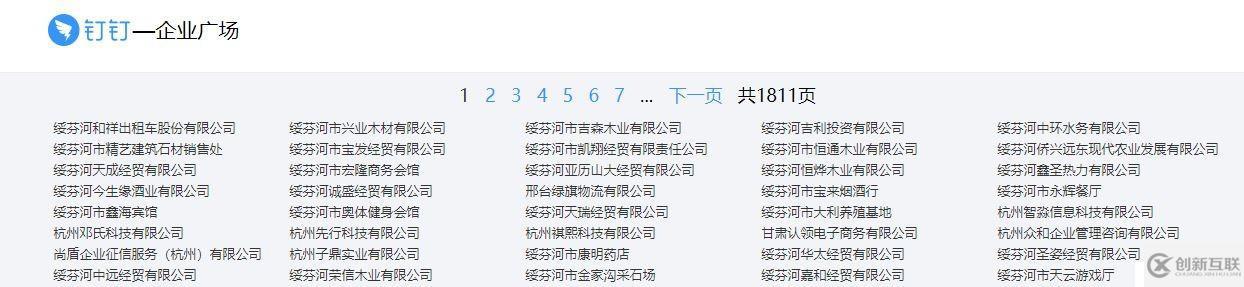
所以,我们的思路就很明确了,通过https://www.dingtalk.com/qiye/1.html这个入口链接获取企业的URL,然后通过访问企业的URL获取企业的信息。在jupyter notebook中试一下。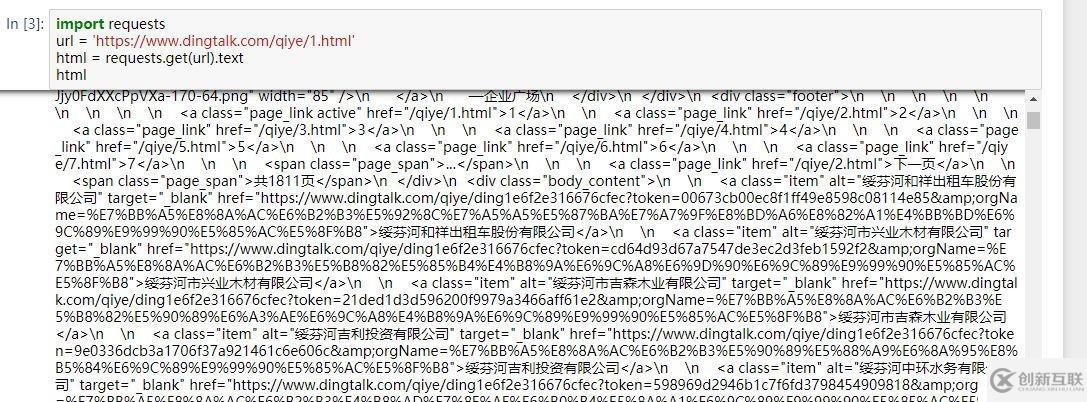
企业的URL已经获取到了,然后再访问企业的URL,看看能否获取到企业的信息。
没有。
写请求头,请求头包含两项,一个是cookie,一个user-agent。加上请求头再试试看,有了。
发现企业信息在js代码里,写正则表达式
创新互联公司服务电话:18980820575,为您提供成都网站建设网页设计及定制高端网站建设服务,创新互联公司网页制作领域十载,包括护栏打桩机等多个行业拥有丰富的网站制作经验,选择创新互联公司,为网站保驾护航。
patterns = r'"businessInfoData":{"enterpriseName":"(.*?)","frName":"(.*?)","enterpriseType":"(.*?)","enterpriseStatus":"(.*?)","regCap":"(.*?)","regCapCur":"(.*?)","esDate":"(.*?)","regOrg":"(.*?)","operateScope":"(.*?)","address":"(.*?)","regNo":"(.*?)","creditCode":"(.*?)","region":"(.*?)"}'
results = re.findall(patterns, html)ok,成功匹配出来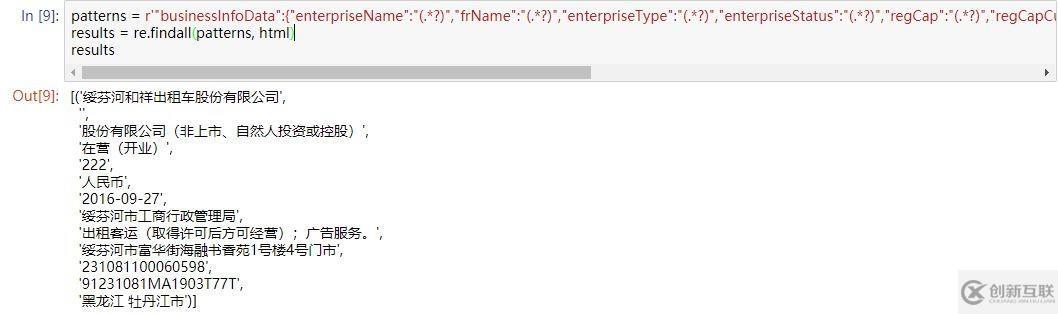
到此,发现很简单了,立马就把代码给写了出来,但发现一些问题,只有一部分企业的信息爬取了出来,大部分企业信息都获取失败了。这是咋回事呢,原来啊,有的企业URL源码里有企业信息,而有的没有。

然后,我查看完整企业信息,发现这个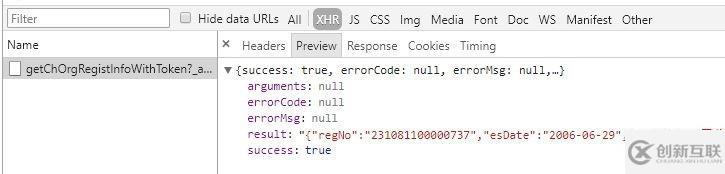
但是,我无法构造这个链接,忧伤。
所以,整个爬虫到此为止。写代码的时候,原本想用入口链接不断下一页获取所有企业URL,但一想,算了吧,直接简单粗暴一点。然后呢,爬取的时候,爬取速度好慢。
最后,附上垃圾的源码github。
分享标题:记一次不太成功的爬取dingtalk上的企业的信息
网页地址:https://www.cdcxhl.com/article36/ghodsg.html
成都网站建设公司_创新互联,为您提供网站收录、品牌网站建设、网站营销、网站设计、网站维护、网站建设
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- Vestacp整合WHMCS实现自动销售开通虚拟主机服务教程 2022-10-07
- BCH云虚拟主机模板预装功能上线,使网站上云更轻松 2016-02-18
- 北京网站建设之服务器和虚拟主机空间常见问题? 2021-05-31
- 虚拟主机和云服务器的区别,它们各自的优缺点是什么 2021-02-11
- 虚拟主机与独立IP网站优化所需要的SEO技巧 2021-11-09
- 什么是虚拟主机空间进程工作数? 2021-02-08
- 什么是云虚拟主机以及和云服务器之间的区别 2022-10-03
- 企业网站采用什么样的虚拟主机更合适? 2022-01-31
- 虚拟主机空间怎么选择? 2022-10-09
- 建网站的虚拟主机怎样挑选 2022-06-23
- 虚拟主机对公司网站优化有哪些影响? 2016-11-11
- 虚拟主机能干什么 2018-07-18