hadoopHdfs的数据磁盘大小不均衡怎么处理
这篇文章主要讲解了“hadoop Hdfs的数据磁盘大小不均衡怎么处理”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“hadoop Hdfs的数据磁盘大小不均衡怎么处理”吧!
成都创新互联是一家网站设计公司,集创意、互联网应用、软件技术为一体的创意网站建设服务商,主营产品:自适应网站建设、成都品牌网站建设、成都营销网站建设。我们专注企业品牌在网站中的整体树立,网络互动的体验,以及在手机等移动端的优质呈现。成都网站设计、网站建设、移动互联产品、网络运营、VI设计、云产品.运维为核心业务。为用户提供一站式解决方案,我们深知市场的竞争激烈,认真对待每位客户,为客户提供赏析悦目的作品,网站的价值服务。
现象描述
建集群的时候,datanode的节点数据磁盘总共是四块磁盘做矩阵成了一个7.2TB的sdb1(data1),两块通过矩阵做了一个3.6TB的sdc1(data2)磁盘,运维做的,历史原因。刚开始没有发现,然后集群过了一段时间,随着数据量的增加,发现集群有很多磁盘超过使用率90%告警,浪尖设置磁盘告警阈值是90%,超过阈值就会发短信或者微信告警,提醒我们磁盘将要满了进行预处理,但是通过hadoop的监控指标获取的磁盘利用率维持在55%+,这种情况下不应该发生告警的。磁盘的使用率在hadoop的hdfs的namnode的web ui也可以看到,如下:

这个时候,大家的怀疑会集中于hdfs的某些datanode节点数据存储过于集中,导致某些节点磁盘告警。但是大家都知道,hdfs允许datanode节点接入时datanode之间磁盘异构,数据存储hadoop会自动在datanode之间进行均衡。所以这个怀疑可以排除。
登录告警节点,发现确实data2磁盘使用率超过了90%,但是data1使用率维持在不足50%。
这时候问题就显而易见了,hadoop3.0之前hdfs数据存储只支持在datanode节点之间均衡,而不支持datanode内部磁盘间的数据存储均衡。

那么这个时候怎么办呢?
起初
浪尖想的是将data1那个矩阵,拆分成两块由两块磁盘组成的矩阵,然后重新滚动上下线Datanode(数据迁移或者通过副本变动让其进行均衡)。但是,后来很快否定了这种方法,原因是很简单。几百TB的数据,在集群中均衡,即使是滚动重启,那么多机器也要持续好久,然后在数据迁移或者均衡的时候,整个几群的带宽和磁盘都是会增加很大负担,导致集群的可用性降低。
接着
通过hadoop官网发现hadoop 3.0不仅支持datanode之间的数据均衡,也支持datanode内部管理的多磁盘的之间的数据均衡。

这个时候,可以考虑升级hadoop集群到hadoop3.0,但是思考再三浪尖觉得浪费时间,不划算,最终放弃这种方案。
最后
几经思考,终于想出了一个原本就很简单的方案,只需要重启datanode,就可以实现提高大磁盘利用率的方法。首先,要知道的是datanode管理磁盘,是根据我们dfs.data.dir参数指定的目录。那么,我们的思路就很简单了,给data1多个目录,不就可以增加其写入的概率,进而提升磁盘的使用率了么。配置方式如下:
<property>
<name>dfs.data.dir</name>
<value>/data1/dfs/dn,/data1/dfs/dn1,/data2/dfs/dn</value>
</property>
配置结束之后,重启datanode集群,过一定时间查看该目录的大小,然后发现有数据写入。
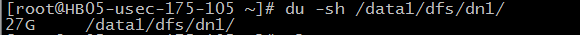
由此证明,想法是可行的。
此方法的缺点是,原有的数据不会进行均衡,增加目录的方式只是增加了新数据写入大磁盘的概率,但是这样就可以了,等着原有数据自动删除即可。
感谢各位的阅读,以上就是“hadoop Hdfs的数据磁盘大小不均衡怎么处理”的内容了,经过本文的学习后,相信大家对hadoop Hdfs的数据磁盘大小不均衡怎么处理这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是创新互联,小编将为大家推送更多相关知识点的文章,欢迎关注!
文章标题:hadoopHdfs的数据磁盘大小不均衡怎么处理
文章网址:https://www.cdcxhl.com/article36/ghdssg.html
成都网站建设公司_创新互联,为您提供手机网站建设、用户体验、网站策划、Google、软件开发、标签优化
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 网站营销的网站营销方面存在的弊病 2020-11-01
- 网站SEO优化是为了排名还是用户体验? 2013-11-28
- 用户体验对于网站SEO有多重要? 2013-11-12
- 【SEO关键词推广】建立网站时选虚拟主机的6大注 2016-11-14
- 掌握这几个百度SEO优化技巧:让你的网站排名挤进首页前三 2016-11-10
- 用一篇软文实现将网站改版关键词做到百度前三 2013-11-12
- 为什么SEO要用静态网站? 2015-05-12
- 网站优化注重用户体验 2016-08-23
- 新站SEO优化怎么做可以快速被收录? 2015-10-12
- 成都做网站营销型网站建设的基础条件 2017-03-02
- 营销型网站建设价格偏贵 为什么我们还要做 2016-08-17
- 网站SEO经验:子目录收录时百度与谷歌的差异 2016-08-02