node实现爬虫的几种简易方式-创新互联
说到爬虫大家可能会觉得很NB的东西,可以爬小电影,羞羞图,没错就是这样的。在node爬虫方面,我也是个新人,这篇文章主要是给大家分享几种实现node

爬虫的方式。第一种方式,采用node,js中的 superagent+request + cheerio。cheerio是必须的,它相当于node版的jQuery,用过jQuery的同学会非常容易上手。它
主要是用来获取抓取到的页面元素和其中的数据信息。superagent是node里一个非常方便的、轻量的、渐进式的第三方客户端请求代理模块,用他来请求目标页面。
node中,http模块也可作为客户端使用(发送请求),第三方模块request对其使用方法进行了封装,操作更方便。以下是三者的引入方法:

接下来我们开始请求要爬取的目标页面。申明目标页面比如新浪网首页:

如新浪首页部分代码
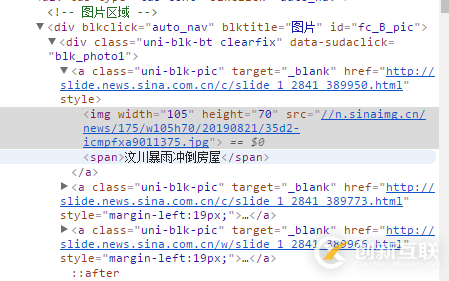
通过superagent请求目标网站,获取到网站内容,通过cheerio.load方法引入要解析的html
cheerio中的有关DOM操作的方式

此处采用 .each(function(index,element){...})方式遍历需要的元素

返回结果如下:
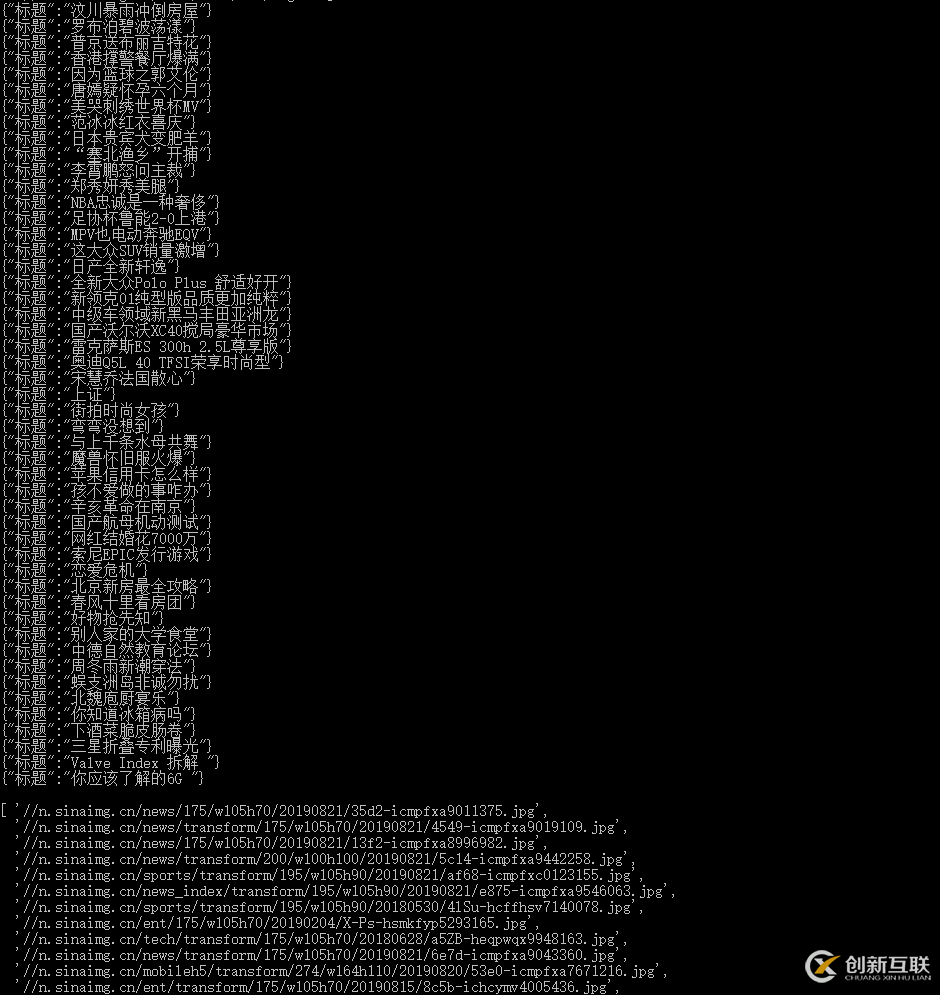
若要将文字内容存储可采用以下方式:
引入fs模块const fs= require("fs")
引入path模块 const path=require("path")
Node.js 内置的fs模块就是文件系统模块,负责读写文件。和所有其他JS模块不同的是,fs模块同时提供了异步和同步的方法。
在上述方法中调用存储文字内容mkdirs方法
//存放数据
mkdirs('./content2',saveContent); (注: content2是新建文件名;saveContent是回调函数)另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
网站题目:node实现爬虫的几种简易方式-创新互联
网站链接:https://www.cdcxhl.com/article36/dhcopg.html
成都网站建设公司_创新互联,为您提供App设计、服务器托管、网站排名、全网营销推广、动态网站、ChatGPT
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 如何打响品牌网站制作的知名度 2021-12-11
- 品牌网站制作应该体现企业文化和个性 2021-08-12
- 品牌网站制作常见的布局方式! 2022-05-11
- 湛江品牌网站制作:做好品牌网站制作方案有哪些要点? 2021-12-23
- 高端品牌网站制作策划方案 2021-10-09
- 如何做好品牌网站制作 2021-11-16
- 周口品牌网站建设:在品牌网站制作的过程中有哪些值得注意的问题? 2021-09-10
- 品牌网站制作为什么只能选择网站定制 2021-10-04
- 品牌网站制作解决方案 2016-09-12
- 高端品牌网站制作离不开独特新颖的设计 2016-10-30
- 保定品牌网站制作:如何做好一个成功的品牌网站? 2021-08-27
- 企业官方品牌网站制作需要遵循的三大原则 2023-03-02