CUDA编程笔记(2)-创新互联
- 前言
- 1.CUDA的基本框架
- 直接使用c++编写的数组相加的程序
- 使用cuda核函数的数组相加的程序
- 函数执行空间标识符
- 总结
- 参考:
前言
cuda程序的基本框架
1.CUDA的基本框架头文件
常量定义(或者宏定义)
C++自定义函数和cuda核函数的声明
int main()
{a分配主机与设备内存
初始化主机中的数据
将某些数据从主机复制到设备
调用核函数在设备中进行计算
将某些数据从设备复制到主机
释放主机与设备内存
}
c++自定义函数和cuda核函数的实现下面通过列子来体现这个框架
直接使用c++编写的数组相加的程序这里直接使用c++编写程序的习惯写的数组相加的程序:
#include#include#includeconst double EP = 1.0e-15;
const double a = 1.23;
const double b = 2.34;
const double c = 3.57;
void add(const double *x,const double *y,double *z,const int N);
void check(const double *z,const int N);
int main()
{const int N = 100000000;
const int M = sizeof(double)*N;
// 分配内存
double *x = (double *)malloc(M);
double *y = (double *)malloc(M);
double *z = (double *)malloc(M);
// double *x = new double[M];
// double *y = new double[M];
// double *z = new double[M];
// 初始化
for(int n=0;nx[n] = a;
y[n] = b;
}
// 数组求和
add(x,y,z,N);
check(z,N);
// 释放内存
free(x);
free(y);
free(z);
// delete []x;
// delete []y;
// delete []z;
return 0;
}
void add(const double *x,const double *y,double *z,const int N)
{for(int n=0;nz[n] = x[n] + y[n];
}
}
void check(const double *z, const int N)
{bool has_error = false;
for(int n=0;nif(fabs(z[n]-c)>EP)
{has_error = true;
}
}
printf("%s\n",has_error?"HAS_ERROR":"NO_ERROR");
}
// 头文件
#include#include#include// 常量定义
const double EP = 1.0e-15;
const double a = 1.23;
const double b = 2.34;
const double c = 3.57;
// c++自定义函数和cuda核函数的声明
__global__ void add(const double *x,const double *y,double *z);
void check(const double *z,const int N);
int main()
{const int N = 100000000;
const int M = sizeof(double)*N;
// 分配主机内存
double *h_x = (double *)malloc(M);
double *h_y = (double *)malloc(M);
double *h_z = (double *)malloc(M);
// double *h_x = new double[M];
// double *h_y = new double[M];
// double *h_z = new double[M];
// 分配设备内存
double *d_x,*d_y,*d_z;
// printf("%p",d_x);
cudaMalloc((void **)&d_x,M);
cudaMalloc((void **)&d_y,M);
cudaMalloc((void **)&d_z,M);
// 初始化主机上的数据
for(int n=0;nh_x[n] = a;
h_y[n] = b;
}
// 将某些数据从主机复制到设备上
cudaMemcpy(d_x,h_x,M,cudaMemcpyHostToDevice);
cudaMemcpy(d_y,h_y,M,cudaMemcpyHostToDevice);
// 调用核函数在设备中进行计算,数组求和
const int block_size = 128; // 不同型号的GPU有线程限制,开普勒到图灵大为1024
const int gride_size = N/block_size;
add<<>>(d_x,d_y,d_z);
// 将某些数据从设备复制到主机上,这个数据传输函数隐式的起到了同步主机与设备的作用,所以后面用不用cudaDeviceSynchronize都可以
cudaMemcpy(h_z,d_z,M,cudaMemcpyDeviceToHost);
check(h_z,N);
// 释放内存
free(h_x);
free(h_y);
free(h_z);
// delete []h_x;
// delete []h_y;
// delete []h_z;
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
return 0;
}
__global__ void add(const double *x,const double *y,double *z)
{// 单指令-多线程,注意核函数中数据与线程的对应关系
const int n = blockDim.x * blockIdx.x + threadIdx.x;
z[n] = x[n] + y[n];
}
void check(const double *z, const int N)
{bool has_error = false;
for(int n=0;nif(fabs(z[n]-c)>EP)
{has_error = true;
}
}
printf("%s\n",has_error?"HAS_ERROR":"NO_ERROR");
} // 单指令-多线程,注意核函数中数据与线程的对应关系
const int n = blockDim.x * blockIdx.x + threadIdx.x;
blockDim指的是每个线程块的线程总固定大小;
blockIdx指的是线程块的索引;
threadIdx指的是线程的索引;
所以具体的一维线程索引会等于上面代码式子所计算的索引核函数中数据与线程的对应关系时,注意到保存相应数据类型的内存大小N是自己定义的,所以就存在一个问题,如果gride_size = N/block_size不是刚好整数倍时,就有可能引发错误(越界)。所以,尽可能让定义的线程个数多于元素个数,然后通过条件语句来规避不需要的线程操作。可以写成
int gride_size = (N%block_size==0?(N/block_size):(N/block_size + 1));
// 简化成
int gride_size = (N-1) / block_size + 1; //or
int gride_size = (N+block_size-1) / block_size;同时,在核函数里使用if条件语句规避不需要的线程操作:
// 参数传入了 N
void __global__ add(const double *x, const double *y, double *z, const int N)
{const int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n< N)
{z[n] = x[n] + y[n];
}
}编译的时候,用nvcc编译会将设备代码编译为PTX(parallel thread execution)伪汇编代码,再将伪汇编代码编译成二进制的cubin代码。在编译为PTX代码时,需要指定GPU架构的计算能力。默认是2.0,可以自己看看自己GPU的算力,用nvcc编译时,加上-arch=sm_XY语句。如:
nvcc -g -arch=sm_75 xxx.cu -o xxx // GeForce RTX2080是7.5的通过结合上面的基本框架流程和未使用cuda核函数的c++程序进行比较:
- (1)使用cuda核函数的程序,要使用cudaMalloc分配设备内存并将数据复制到设备内存中。同样和c++分配内存空间一样,malloc与free要配套,cudaMalloc和cudaFree配套。c++中的另一种动态分配内存的new和delete可以替换malloc与free.
- (2)主机与设备间的数据传递使用cudaMemcpy,将主机(或设备)中的数据复制到设备(或主机)中的内存地址中。
- (3)注意核函数中数据与线程的对应关系,单指令-多线程的操作需要注意对应操作关系。
上面的cuda运行的api可以在官方文档查看使用说明:
https://docs.nvidia.com/cuda/cuda-runtime-api
如cudaMalloc,直接在搜索框里搜索,然后点进去查看说明: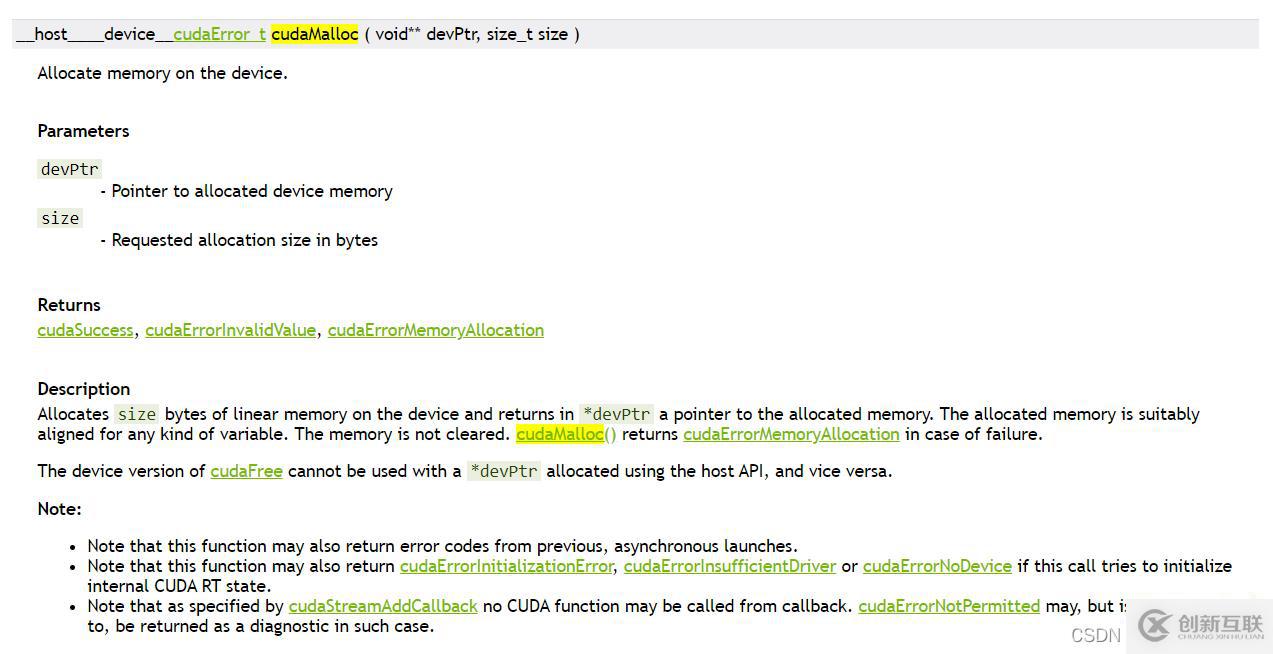
这里关注下返回值和输入参数:返回值是一个cudaError_t类型的信息,表示是否成功运行此api,对于后面的程序检查有用,输入参数void **devPtr,因为返回值已经使用了,所以输入参数使用一个双重指针,指向指针的指针来指向数据原地址。
在cuda程序中,可以使用标识符确定一个函数在哪里被调用和执行。
(1)用__global__修饰的函数称为核函数。一般由主机调用,在设备中执行。动态并行时,也可以在核函数中互相调用。
(2)用__device__修饰的函数称为设备函数,只能被核函数或其他设备函数调用,在设备中执行。
(3)用__host__修饰的函数就是主机端的普通C++函数,在主机中调用,在主机中执行。也可以省略,之所以提供这个修饰符,主要是有时可以用__host__和__device__同时修饰一个函数,这样可以避免代码的冗余。
(4)可以使用修饰符__noinline__或者__forceinline__建议一个设备函数为非内联函数或内联函数。
注意:
1.不能同时使用__global__和__device__修饰同一个函数。
2.不能同时使用__global__和__host__修饰同一个函数。
熟悉cuda程序的基本框架。
参考:如博客内容有侵权行为,可及时联系删除!
CUDA 编程:基础与实践
https://docs.nvidia.com/cuda/
https://docs.nvidia.com/cuda/cuda-runtime-api
https://github.com/brucefan1983/CUDA-Programming
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
当前名称:CUDA编程笔记(2)-创新互联
路径分享:https://www.cdcxhl.com/article36/cdodpg.html
成都网站建设公司_创新互联,为您提供外贸网站建设、标签优化、网站设计公司、手机网站建设、全网营销推广、网站改版
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 品牌网站制作常见的布局方式 2022-03-22
- 为什么高端品牌网站制作公司越来越少了 2016-11-12
- 品牌网站制作为什么只能选择网站定制 2021-10-04
- 集团型网站建设品牌网站制作设计 2020-12-03
- 企业官方品牌网站制作需要遵循的三大原则 2023-03-02
- 湛江品牌网站制作:做好品牌网站制作方案有哪些要点? 2021-12-23
- 品牌网站制作之搜索引擎营销 2021-11-17
- 中小企业品牌网站制作与塑造 2021-12-06
- 深圳品牌网站制作营销重点 2021-09-28
- 企业品牌网站制作要注重哪些问题? 2023-04-18
- 品牌网站制作好方法好步骤? 2021-06-03
- 高端品牌网站制作策划方案 2021-10-09