Spring循环依赖源码解析(深度理解)-创新互联
- 前言
- 本章目标
- 一、什么是循环依赖?
- 1、那么循环依赖是个问题吗?
- 2、但是在Spring中循环依赖就是一个问题了,为什么?
- 二、Bean的生命周期
- 2.1、在Spring中,Bean是如何生成的?
- 2.2、那么这个注入过程是怎样的?
- 2.3、Srping的依赖注入如何产生的?
- 三、什么是AOP
- 四、Spring三级缓存
- 五、Spring循环依赖的实现原理、源码解析
- 5.1、解决循环依赖思路分析
- 5.2、Spring为什么需要三级缓存(singletonFactories)呢?
- 5.3、Spring是如何解决循环依赖的
- 5.4、什么时候会调用getEarlyBeanReference方法呢?
- 5.5、如果提前进行了AOP,什么时候把AOP的代理对象放到单例池呢?
- 六、三级缓存总结
- 6.1、singletonObjects(一级缓存)
- 6.2、earlySingletonObjects(二级缓存)
- 6.3、singletonFactories(三级缓存)
- 6.4、earlyProxyReferences(是否进行了AOP缓存)
- 七、什么场景下spring循环依赖不行
- 7.1、循环依赖的2个类都为原型Bean
- 7.2、构造方法注入
- 7.3、如何处理构造方法注入解决?
- 八、spring只用二级循环能否解决循环依赖问题?
- 8.1、为什么需要singletonFactories?
- 8.2、那如果没有singletonFactories,该如何把原始对象或AOP之后的代理对象放入earlySingletonObjects中呢?何时放入呢?
- 九、循环依赖流程图

前言
本章目标
1、弄清楚什么是循环依赖?Spring的循环依赖是如何产生的?
2、Spring的循环依赖底层实现逻辑
3、Spring的三级缓存,每一级缓存分别干了啥,解决什么问题
4、Spring二级缓存能否搞定循环依赖?
5、Spring循环依赖什么场景搞不定
一、什么是循环依赖?
就是A对象依赖了B对象,B对象依赖了A对象。
比如:
// A依赖了B
class A{public B b;
}
// B依赖了A
class B{public A a;
}如果不考虑Spring,循环依赖并不是问题,因为对象之间相互依赖是很正常的事情。
比如
A a = new A();
B b = new B();
a.b = b;
b.a = a;这样,A,B就依赖上了。
2、但是在Spring中循环依赖就是一个问题了,为什么?
因为,在Spring中,一个对象并不是简单new出来了,而是会经过一系列的Bean的生命周期,就是因为Bean的生命周期所以才会出现循环依赖问题。
当然,在Spring中,出现循环依赖的场景很多,有的场景Spring自动帮我们解决了,而有的场景则需要程序员来解决。
要明白Spring中的循环依赖,得先明白Spring中Bean的生命周期。
二、Bean的生命周期
这里不会对Bean的生命周期进行详细的描述,只描述一下大概的过程。
PS:如需详细了解,可以点击传送门:Spring Bean生命周期文章来了解Spring Bean生命周期详细流程。
2.1、在Spring中,Bean是如何生成的?
被Spring管理的对象叫做Bean。Bean的生成步骤如下:
1、Spring扫描class得到BeanDefinition
2、根据得到的BeanDefinition去生成bean
3、首先根据class推断构造方法
4、根据推断出来的构造方法,反射,得到一个对象(暂时叫做原始对象)
5、填充原始对象中的属性(依赖注入)
6、如果原始对象中的某个方法被AOP了,那么则需要根据原始对象生成一个代理对象
7、把最终生成的代理对象放入单例池(源码中叫做singletonObjects)中,下次getBean时就直接从单例池拿即可
可以看到,对于Spring中的Bean的生成过程,步骤还是很多的,并且不仅仅只有上面的7步,还有很多很多,比如Aware回调、初始化等等,这里不详细讨论。
可以发现,在Spring中,构造一个Bean,包括了new这个步骤(第4步构造方法反射)。
得到一个原始对象后,Spring需要给对象中的属性进行依赖注入
2.2、那么这个注入过程是怎样的?
比如上文说的A类,A类中存在一个B类的b属性,
所以,
1、当A类生成了一个原始对象之后,就会去给b属性去赋值,
2、此时就会根据b属性的类型和属性名去BeanFactory中去获取B类所对应的单例bean。
3、如果此时BeanFactory中存在B对应的Bean,那么直接拿来赋值给b属性;
4、如果此时BeanFactory中不存在B对应的Bean,则需要生成一个B对应的Bean,然后赋值给b属性。
问题就出现在第二种情况,
2.3、Srping的依赖注入如何产生的?
如果此时B类在BeanFactory中还没有生成对应的Bean,那么就需要去生成,就会经过B的Bean的生命周期。
那么在创建B类的Bean的过程中,如果B类中存在一个A类的a属性,那么在创建B的Bean的过程中就需要A类对应的Bean,
但是,触发B类Bean的创建的条件是A类Bean在创建过程中的依赖注入,所以这里就出现了循环依赖:
ABean创建–>依赖了B属性–>触发BBean创建—>B依赖了A属性—>需要ABean(但ABean还在创建过程中)
从而导致ABean创建不出来,BBean也创建不出来。
这是循环依赖的场景,但是上文说了,在Spring中,通过某些机制帮开发者解决了部分循环依赖的问题,这个机制就是三级缓存。
三、什么是AOP
在了解为什么spring 循环依赖需要缓存之前,需要对aop有一个大概的了解
AOP就是通过一个BeanPostProcessor来实现的,这个BeanPostProcessor就是AnnotationAwareAspectJAutoProxyCreator,它的父类是AbstractAutoProxyCreator。
而在Spring中AOP利用的要么是JDK动态代理,要么CGLib的动态代理,所以如果给一个类中的某个方法设置了切面,那么这个类最终就需要生成一个代理对象。
一般过程就是:
A类—>生成一个普通对象–>属性注入–>基于切面生成一个代理对象–>把代理对象放入singletonObjects单例池中。
而AOP可以说是Spring中除开IOC的另外一大功能,而循环依赖又是属于IOC范畴的,所以这两大功能想要并存,Spring需要特殊处理。
如何处理的,就是利用了第三级缓存singletonFactories。
四、Spring三级缓存
这里先有个简单印象,三级缓存是通用的叫法。
一级缓存为:singletonObjects
二级缓存为:earlySingletonObjects
三级缓存为:singletonFactories
先稍微解释一下这三个缓存的作用,后面详细分析:
singletonObjects中缓存的是已经经历了完整生命周期的bean对象。
earlySingletonObjects比singletonObjects多了一个early,表示缓存的是早期的bean对象。
早期是什么意思?表示Bean的生命周期还没走完就把这个Bean放入了earlySingletonObjects。
singletonFactories中缓存的是ObjectFactory,表示对象工厂,表示用来创建早期bean对象的工厂。
五、Spring循环依赖的实现原理、源码解析 5.1、解决循环依赖思路分析
先来分析为什么缓存能解决循环依赖。
上文分析得到,之所以产生循环依赖的问题,主要是:
A创建时—>需要B---->B去创建—>需要A,从而产生了循环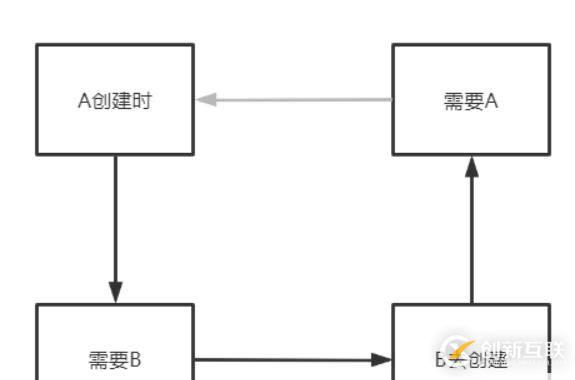
那么如何打破这个循环,加个中间人(缓存)
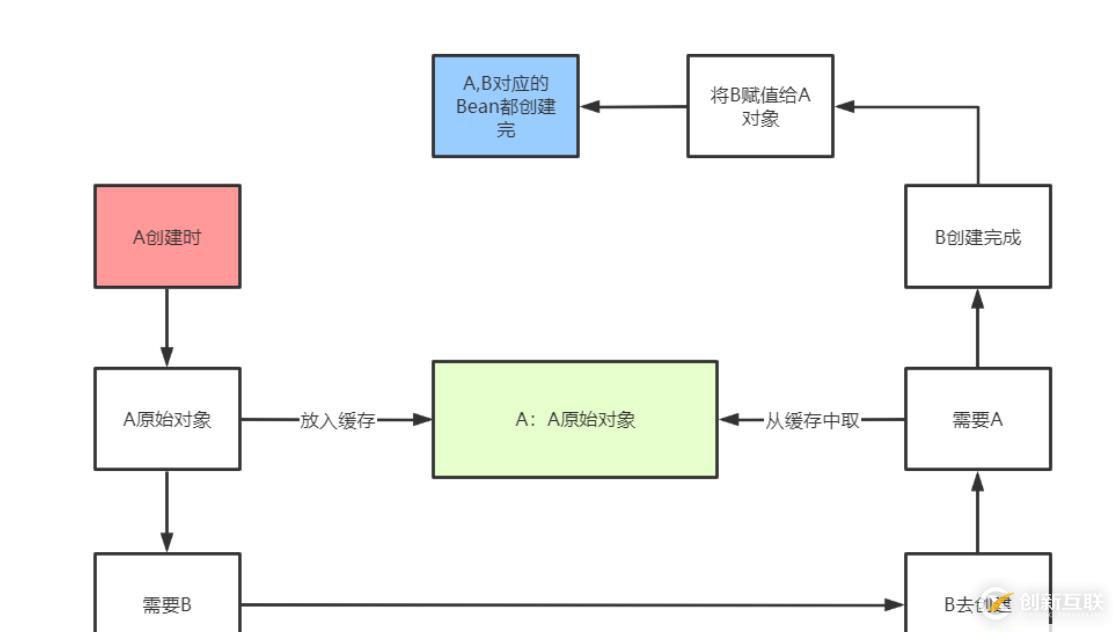
A的Bean在创建过程中,在进行依赖注入之前,
1、先把A的原始Bean放入缓存(提早暴露,只要放到缓存了,其他Bean需要时就可以从缓存中拿了)
2、放入缓存后,再进行依赖注入,此时A的Bean依赖了B的Bean,如果B的Bean不存在,则需要创建B的Bean,
3、而创建B的Bean的过程和A一样,也是先创建一个B的原始对象,然后把B的原始对象提早暴露出来放入缓存中
4、然后在对B的原始对象进行依赖注入A,此时能从缓存中拿到A的原始对象(虽然是A的原始对象,还不是最终的Bean),B的原始对象依赖注入完了之后,B的生命周期结束,那么A的生命周期也能结束。
因为整个过程中,都只有一个A原始对象,所以对于B而言,就算在属性注入时,注入的是A原始对象,也没有关系,因为A原始对象在后续的生命周期中在堆中没有发生变化。
从上面这个分析过程中可以得出,只需要一个缓存就能解决循环依赖了,那么为什么Spring中还需要singletonFactories呢?
5.2、Spring为什么需要三级缓存(singletonFactories)呢?
基于上面的场景想一个问题:
如果A的原始对象注入给B的属性之后,A的原始对象进行了AOP产生了一个代理对象,
此时就会出现,对于A而言,它的Bean对象其实应该是AOP之后的代理对象,而B的a属性对应的并不是AOP之后的代理对象,这就产生了冲突。
大概是这么个过程
创建A-》填充B-》创建B-》填充A-》从singletonFactories获取A-》B生命周期结束-》A初始化前和初始化-》进行AOP-》A放入单例池
经过上面的步骤后
B依赖的A和最终的A不是同一个对象。
5.3、Spring是如何解决循环依赖的
下面这个方法是在填充属性之前,会进行addSingletonFactory(beanName, () ->getEarlyBeanReference(beanName, mbd, bean));
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) { if (logger.isTraceEnabled()) { logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () ->getEarlyBeanReference(beanName, mbd, bean));
}其实就是把当前类A对象缓存到这个三级缓存里,因为这个对象如果实现了AOP,在后续他会从一个原始对象变成一个aop对象,所以采用了函数式接口,getEarlyBeanReference就是处理到底返回原始对象还是AOP的代理对象。
singletonFactories(三级缓存)中存的是某个beanName对应的ObjectFactory,在bean的生命周期中,生成完原始对象之后,就会构造一个ObjectFactory存入singletonFactories中。
这个ObjectFactory是一个函数式接口,所以支持Lambda表达式:() ->getEarlyBeanReference(beanName, mbd, bean)
上面的Lambda表达式就是一个ObjectFactory,执行该Lambda表达式就会去执行getEarlyBeanReference方法,而该方法如下:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {for (BeanPostProcessor bp : getBeanPostProcessors()) {if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}该方法会去执行SmartInstantiationAwareBeanPostProcessor中的getEarlyBeanReference方法,而这个接口下的实现类中只有两个类实现了这个方法,一个是AbstractAutoProxyCreator,一个是InstantiationAwareBeanPostProcessorAdapter,它的实现如下:
InstantiationAwareBeanPostProcessorAdapter的实现
@Override
public Object getEarlyBeanReference(Object bean, String beanName) throws BeansException {return bean;
}AbstractAutoProxyCreator的实现
@Override
public Object getEarlyBeanReference(Object bean, String beanName) {Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
return wrapIfNecessary(bean, beanName, cacheKey);
}该方法主要做了几件事情
1、首先得到一个cachekey,cachekey就是beanName。
2、然后把beanName和bean(这是原始对象)存入earlyProxyReferences中
3、调用wrapIfNecessary进行AOP,得到一个代理对象。
在整个Spring中,默认就只有AbstractAutoProxyCreator真正意义上实现了getEarlyBeanReference方法,而该类就是用来进行AOP的。
前面提到的AnnotationAwareAspectJAutoProxyCreator的父类就是AbstractAutoProxyCreator。
5.4、什么时候会调用getEarlyBeanReference方法呢?
只有当出现了循环依赖的场景时才会去调用?为什么
如果调用的是C或者其他bean,其他bean并没有和他循环依赖,这个时候getbean的时候 是可以从一级缓存里拿到的,
只有因为此时出现了循环依赖,A对象还没有走完bean生命周期的,所以一级缓存里拿不到。
先想想现在的场景
1、A实例化-》添加三级缓存-》属性填充B
2.1、B去创建对象,实例化
2.2、B添加三级缓存
2.3、属性填充A(此时A的生命周期还没有走完)-》一级缓存-》二级缓存-》三级缓存-》存到二级缓存
2.4、剩下的生命周期流程...2、AOP(这里还有个问题需要处理,就是前面A已经执行了lamdba表达式,生成了AOP代理对象,这里无需再次执行AOP)
3、A的剩下生命周期流程…
1、支持循环依赖的情况下,就会提前增加三级缓存*()
addSingletonFactory(beanName, () ->getEarlyBeanReference(beanName, mbd, bean));2、在属性填充时,每个填充的对象,都会先调用getBean,而getBean则会先调用getSingleton()方法
Object sharedInstance = getSingleton(beanName);而在这个方法里面就会看到调用getEarlyBeanReference方法的地方
下面这个方法主要就是判断一级缓存和二级缓存都不存在的情况下,根据beanName获取三级缓存
调用singletonFactory.getObject()方法,他底层就是调用前面的lamdbabia表达式方法,生成原始或者代理对象,放到二级缓存,删除掉三级缓存
解决循环依赖源码的最新核心方法
protected Object getSingleton(String beanName, boolean allowEarlyReference) {// Quick check for existing instance without full singleton lock
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) { synchronized (this.singletonObjects) {// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) { ObjectFactorysingletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) { // 调用getEarlyBeanReference方法的地方
singletonObject = singletonFactory.getObject();
// 添加二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
// 删除三级缓存
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}注意这里还有个需要注意的点,在执行这个方法时,会缓存当前bean到earlyProxyReferences里,他主要是用来标记这个bean是否进行过aop
@Override
public Object getEarlyBeanReference(Object bean, String beanName) {Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
return wrapIfNecessary(bean, beanName, cacheKey);
}初始化后部分源码
可以看到他会先判断earlyProxyReferences是否存在,以此来判断是否进行过了aop
@Override
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {if (bean != null) { Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (this.earlyProxyReferences.remove(cacheKey) != bean) { return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}通过上面代码可以看到,如果提前进行过aop,他是直接返回了原始对象,并没有缓存到单例池
5.5、如果提前进行了AOP,什么时候把AOP的代理对象放到单例池呢?
答案是初始化后,回去处理,源码如下
如果进行了循环依赖,肯定会进下面的if
会再次获取下当前bean,然后判断传当前bean和初始化后的bean是否相等,是的话,就证明是同一个原始对象,就把刚从二级缓存取到的代理对象进行赋值,并且最终返回
if (earlySingletonExposure) { Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) { if (exposedObject == bean) {exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {String[] dependentBeans = getDependentBeans(beanName);
SetactualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) { actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
} 六、三级缓存总结 6.1、singletonObjects(一级缓存)
作用:不论是spring源码还是工作中经常用到getBean(),都是从这个缓存单例池拿对象
值从哪里来的?经历了完整的声明周期会存放进来
缓存经过了完整生命周期的bean
6.2、earlySingletonObjects(二级缓存)
作用:他主要是解决在循环依赖过程中,保持对象的单例。
值从哪里来的?三级缓存执行了lambda表达式后,生成的对象会放入二级缓存
原理解析
缓存未经过完整生命周期的bean,
如果某个bean出现了循环依赖,就会提前把这个暂时未经过完整生命周期的bean放入earlySingletonObjects中,
这个bean如果要经过AOP,那么就会把代理对象放入earlySingletonObjects中,
否则就是把原始对象放入earlySingletonObjects,
但是不管怎么样,就是是代理对象,代理对象所代理的原始对象也是没有经过完整生命周期的,所以放入earlySingletonObjects我们就可以统一认为是未经过完整生命周期的bean。
6.3、singletonFactories(三级缓存)
作用:打破循环依赖的关键!
值从哪里来的?实例化后,存放
原理解析
缓存的是一个ObjectFactory,也就是一个Lambda表达式。
1、在每个Bean的生成过程中,经过实例化得到一个原始对象后,都会提前基于原始对象暴露一个Lambda表达式,并保存到三级缓存中,
2、这个Lambda表达式可能用到,也可能用不到,如果当前Bean没有出现循环依赖,那么这个Lambda表达式没用,
当前bean按照自己的生命周期正常执行,执行完后直接把当前bean放入singletonObjects中,
3、如果当前bean在依赖注入时发现出现了循环依赖(当前正在创建的bean被其他bean依赖了),
3.1、则从三级缓存中拿到Lambda表达式,并执行Lambda表达式得到一个对象,并把得到的对象放入二级缓存
3.2、如果当前Bean**需要AOP,**那么执行lambda表达式,得到就是对应的代理对象,
3.3.、如果无需AOP,则直接得到一个原始对象。
6.4、earlyProxyReferences(是否进行了AOP缓存)
其实还要一个缓存,就是earlyProxyReferences,它用来记录某个原始对象是否进行过AOP了。
七、什么场景下spring循环依赖不行 7.1、循环依赖的2个类都为原型Bean
原因:单例可以是因为有单例池,可以找到单例bean,原型Bean则没办法像单例那样处理
如果只有有一个是单例的,就可以解决,无非就是多循环几圈
7.2、构造方法注入
原因:构造方法写死了依赖其他对象,这时根本无法创建实例
7.3、如何处理构造方法注入解决?
@Lazy注解即可
原因:是因为,他会生成一个代理对象,可以规避掉无法创建实例的问题。
八、spring只用二级循环能否解决循环依赖问题?
先反向分析一下singletonFactories
8.1、为什么需要singletonFactories?假设没有singletonFactories,只有earlySingletonObjects,earlySingletonObjects是二级缓存,它内部存储的是为经过完整生命周期的bean对象,Spring原有的流程是出现了循环依赖的情况下:
1、先从singletonFactories中拿到lambda表达式,这里肯定是能拿到的,因为每个bean实例化之后,依赖注入之前,就会生成一个lambda表示放入singletonFactories中
2、执行lambda表达式,得到结果,将结果放入earlySingletonObjects中
8.2、那如果没有singletonFactories,该如何把原始对象或AOP之后的代理对象放入earlySingletonObjects中呢?何时放入呢?
首先,将原始对象或AOP之后的代理对象放入earlySingletonObjects中的有两种:
1、实例化之后,依赖注入之前:如果是这样,那么对于每个bean而言,都是在依赖注入之前会去进行AOP,这是不符合bean生命周期步骤的设计的。
2、真正发现某个bean出现了循环依赖时:
按现在Spring源码的流程来说,就是getSingleton(String beanName, boolean allowEarlyReference)中,是在这个方法中判断出来了当前获取的这个bean在创建中,就表示获取的这个bean出现了循环依赖,
那在这个方法中该如何拿到原始对象呢?
更加重要的是,该如何拿到AOP之后的代理对象呢?
难道在这个方法中去循环调用BeanPostProcessor的初始化后的方法吗?不是做不到,不太合适,代码太丑。
最关键的是在这个方法中该如何拿到原始对象呢?
还是得需要一个Map,预先把这个Bean实例化后的对象存在这个Map中,那这样的话还不如直接用第一种方案,但是第一种又直接打破了Bean生命周期的设计。
所以,我们可以发现,现在Spring所用的singletonFactories,为了调和不同的情况,
在singletonFactories中存的是lambda表达式,这样的话,只有在出现了循环依赖的情况,才会执行lambda表达式,才会进行AOP,
也就说只有在出现了循环依赖的情况下才会打破Bean生命周期的设计,如果一个Bean没有出现循环依赖,那么它还是遵守了Bean的生命周期的设计的。
九、循环依赖流程图

你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
新闻名称:Spring循环依赖源码解析(深度理解)-创新互联
网页链接:https://www.cdcxhl.com/article34/pjjse.html
成都网站建设公司_创新互联,为您提供搜索引擎优化、关键词优化、服务器托管、软件开发、网站设计公司、网站设计
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 【网站建设】论网站建设的意义 2016-11-21
- 网站受众群体和网站需求调查一览表在网站建设中的重要性不可小觑 2022-05-23
- 企业网站建设设计的经验方法 2022-05-02
- 网站建设的八种常见类型有哪些? 2015-12-03
- 网站建设必须要注意的功能要点 2022-08-22
- 网站建设中怎样才能促进网页快速收率 2016-11-11
- 网站建设方案表现形式可以多样但一定不可脱离核心要点 2022-05-24
- 成都营销型网站建设有哪些优势? 2023-02-28
- 网站建设内容如何排版布局 2023-03-14
- 北京网站建设怎样扩大自身的影响 2022-07-17
- 为什么网站建设要选择响应式!看完你就懂了 2014-02-13
- 成都企业网站建设你不了解的这些目的 2016-09-20